 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeACES: Generating Diverse Programming Puzzles with Autotelic Language Models and Semantic Descriptors
Oct 25, 2023



Finding and selecting new and interesting problems to solve is at the heart of curiosity, science and innovation. We here study automated problem generation in the context of the open-ended space of python programming puzzles. Existing generative models often aim at modeling a reference distribution without any explicit diversity optimization. Other methods explicitly optimizing for diversity do so either in limited hand-coded representation spaces or in uninterpretable learned embedding spaces that may not align with human perceptions of interesting variations. With ACES (Autotelic Code Exploration via Semantic descriptors), we introduce a new autotelic generation method that leverages semantic descriptors produced by a large language model (LLM) to directly optimize for interesting diversity, as well as few-shot-based generation. Each puzzle is labeled along 10 dimensions, each capturing a programming skill required to solve it. ACES generates and pursues novel and feasible goals to explore that abstract semantic space, slowly discovering a diversity of solvable programming puzzles in any given run. Across a set of experiments, we show that ACES discovers a richer diversity of puzzles than existing diversity-maximizing algorithms as measured across a range of diversity metrics. We further study whether and in which conditions this diversity can translate into the successful training of puzzle solving models.
Augmenting Autotelic Agents with Large Language Models
May 21, 2023Humans learn to master open-ended repertoires of skills by imagining and practicing their own goals. This autotelic learning process, literally the pursuit of self-generated (auto) goals (telos), becomes more and more open-ended as the goals become more diverse, abstract and creative. The resulting exploration of the space of possible skills is supported by an inter-individual exploration: goal representations are culturally evolved and transmitted across individuals, in particular using language. Current artificial agents mostly rely on predefined goal representations corresponding to goal spaces that are either bounded (e.g. list of instructions), or unbounded (e.g. the space of possible visual inputs) but are rarely endowed with the ability to reshape their goal representations, to form new abstractions or to imagine creative goals. In this paper, we introduce a language model augmented autotelic agent (LMA3) that leverages a pretrained language model (LM) to support the representation, generation and learning of diverse, abstract, human-relevant goals. The LM is used as an imperfect model of human cultural transmission; an attempt to capture aspects of humans' common-sense, intuitive physics and overall interests. Specifically, it supports three key components of the autotelic architecture: 1)~a relabeler that describes the goals achieved in the agent's trajectories, 2)~a goal generator that suggests new high-level goals along with their decomposition into subgoals the agent already masters, and 3)~reward functions for each of these goals. Without relying on any hand-coded goal representations, reward functions or curriculum, we show that LMA3 agents learn to master a large diversity of skills in a task-agnostic text-based environment.
A Song of Ice and Fire: Analyzing Textual Autotelic Agents in ScienceWorld
Feb 24, 2023



Building open-ended agents that can autonomously discover a diversity of behaviours is one of the long-standing goals of artificial intelligence. This challenge can be studied in the framework of autotelic RL agents, i.e. agents that learn by selecting and pursuing their own goals, self-organizing a learning curriculum. Recent work identified language as a key dimension of autotelic learning, in particular because it enables abstract goal sampling and guidance from social peers for hindsight relabelling. Within this perspective, we study the following open scientific questions: What is the impact of hindsight feedback from a social peer (e.g. selective vs. exhaustive)? How can the agent learn from very rare language goal examples in its experience replay? How can multiple forms of exploration be combined, and take advantage of easier goals as stepping stones to reach harder ones? To address these questions, we use ScienceWorld, a textual environment with rich abstract and combinatorial physics. We show the importance of selectivity from the social peer's feedback; that experience replay needs to over-sample examples of rare goals; and that following self-generated goal sequences where the agent's competence is intermediate leads to significant improvements in final performance.
Automatic Exploration of Textual Environments with Language-Conditioned Autotelic Agents
Jul 08, 2022In this extended abstract we discuss the opportunities and challenges of studying intrinsically-motivated agents for exploration in textual environments. We argue that there is important synergy between text environments and autonomous agents. We identify key properties of text worlds that make them suitable for exploration by autonmous agents, namely, depth, breadth, progress niches and the ease of use of language goals; we identify drivers of exploration for such agents that are implementable in text worlds. We discuss the opportunities of using autonomous agents to make progress on text environment benchmarks. Finally we list some specific challenges that need to be overcome in this area.
Grounding Spatio-Temporal Language with Transformers
Jun 16, 2021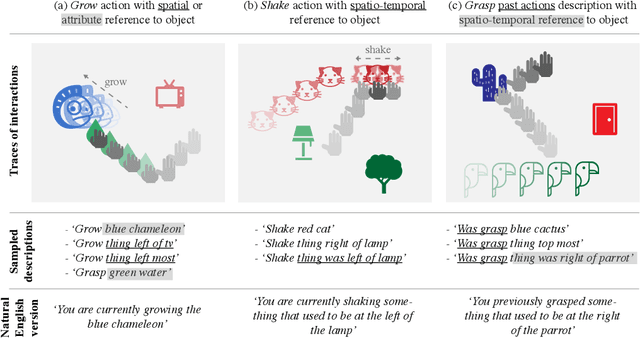
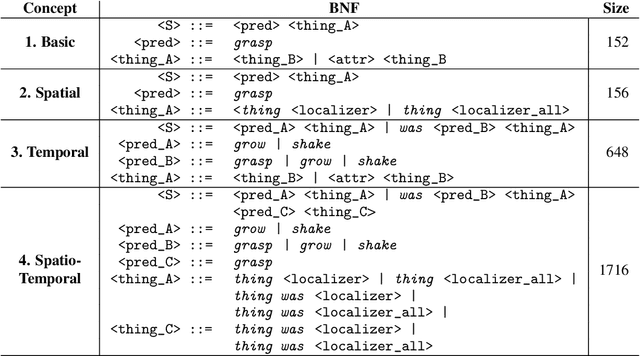
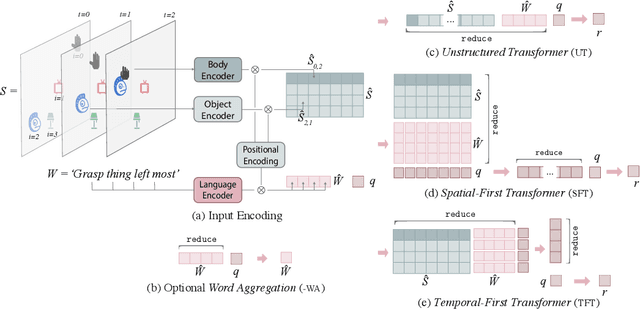
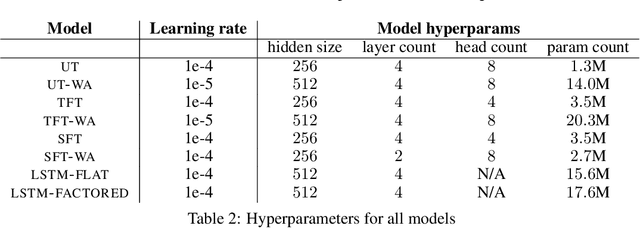
Language is an interface to the outside world. In order for embodied agents to use it, language must be grounded in other, sensorimotor modalities. While there is an extended literature studying how machines can learn grounded language, the topic of how to learn spatio-temporal linguistic concepts is still largely uncharted. To make progress in this direction, we here introduce a novel spatio-temporal language grounding task where the goal is to learn the meaning of spatio-temporal descriptions of behavioral traces of an embodied agent. This is achieved by training a truth function that predicts if a description matches a given history of observations. The descriptions involve time-extended predicates in past and present tense as well as spatio-temporal references to objects in the scene. To study the role of architectural biases in this task, we train several models including multimodal Transformer architectures; the latter implement different attention computations between words and objects across space and time. We test models on two classes of generalization: 1) generalization to randomly held-out sentences; 2) generalization to grammar primitives. We observe that maintaining object identity in the attention computation of our Transformers is instrumental to achieving good performance on generalization overall, and that summarizing object traces in a single token has little influence on performance. We then discuss how this opens new perspectives for language-guided autonomous embodied agents. We also release our code under open-source license as well as pretrained models and datasets to encourage the wider community to build upon and extend our work in the future.
Recognizing Spatial Configurations of Objects with Graph Neural Networks
Apr 09, 2020

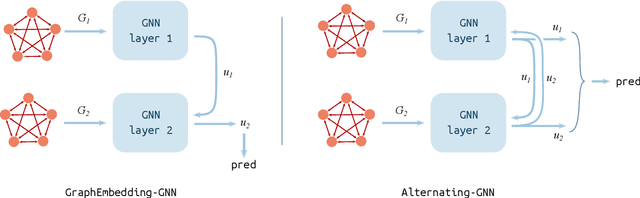
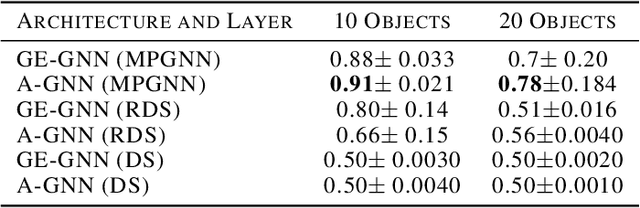
Deep learning algorithms can be seen as compositions of functions acting on learned representations encoded as tensor-structured data. However, in most applications those representations are monolithic, with for instance one single vector encoding an entire image or sentence. In this paper, we build upon the recent successes of Graph Neural Networks (GNNs) to explore the use of graph-structured representations for learning spatial configurations. Motivated by the ability of humans to distinguish arrangements of shapes, we introduce two novel geometrical reasoning tasks, for which we provide the datasets. We introduce novel GNN layers and architectures to solve the tasks and show that graph-structured representations are necessary for good performance.
Deep Sets for Generalization in RL
Mar 20, 2020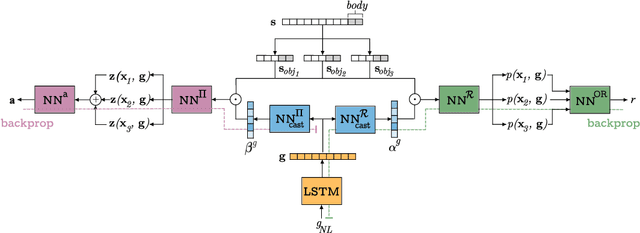
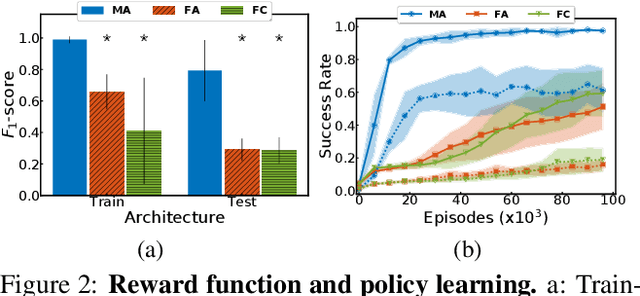
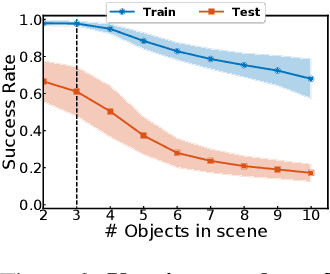
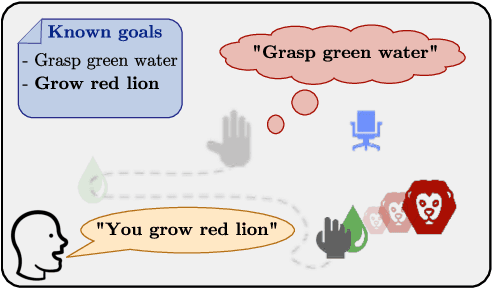
This paper investigates the idea of encoding object-centered representations in the design of the reward function and policy architectures of a language-guided reinforcement learning agent. This is done using a combination of object-wise permutation invariant networks inspired from Deep Sets and gated-attention mechanisms. In a 2D procedurally-generated world where agents targeting goals in natural language navigate and interact with objects, we show that these architectures demonstrate strong generalization capacities to out-of-distribution goals. We study the generalization to varying numbers of objects at test time and further extend the object-centered architectures to goals involving relational reasoning.