 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCLEF HIPE-2026: Evaluating Accurate and Efficient Person-Place Relation Extraction from Multilingual Historical Texts
Feb 19, 2026HIPE-2026 is a CLEF evaluation lab dedicated to person-place relation extraction from noisy, multilingual historical texts. Building on the HIPE-2020 and HIPE-2022 campaigns, it extends the series toward semantic relation extraction by targeting the task of identifying person--place associations in multiple languages and time periods. Systems are asked to classify relations of two types - $at$ ("Has the person ever been at this place?") and $isAt$ ("Is the person located at this place around publication time?") - requiring reasoning over temporal and geographical cues. The lab introduces a three-fold evaluation profile that jointly assesses accuracy, computational efficiency, and domain generalization. By linking relation extraction to large-scale historical data processing, HIPE-2026 aims to support downstream applications in knowledge-graph construction, historical biography reconstruction, and spatial analysis in digital humanities.
Optical Character Recognition of 19th Century Classical Commentaries: the Current State of Affairs
Oct 13, 2021


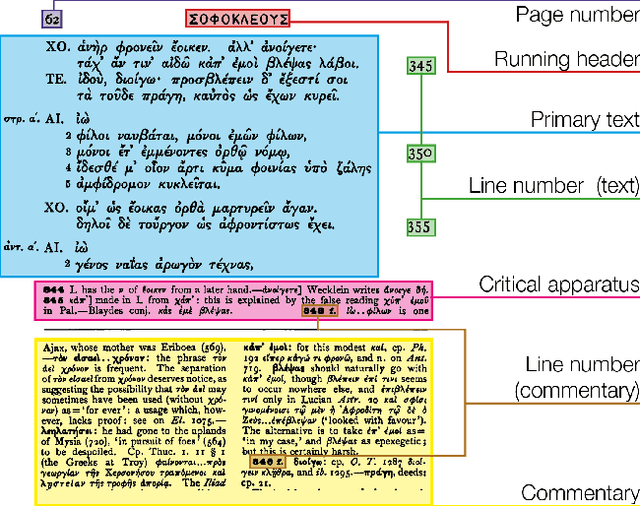
Together with critical editions and translations, commentaries are one of the main genres of publication in literary and textual scholarship, and have a century-long tradition. Yet, the exploitation of thousands of digitized historical commentaries was hitherto hindered by the poor quality of Optical Character Recognition (OCR), especially on commentaries to Greek texts. In this paper, we evaluate the performances of two pipelines suitable for the OCR of historical classical commentaries. Our results show that Kraken + Ciaconna reaches a substantially lower character error rate (CER) than Tesseract/OCR-D on commentary sections with high density of polytonic Greek text (average CER 7% vs. 13%), while Tesseract/OCR-D is slightly more accurate than Kraken + Ciaconna on text sections written predominantly in Latin script (average CER 8.2% vs. 8.4%). As part of this paper, we also release GT4HistComment, a small dataset with OCR ground truth for 19th classical commentaries and Pogretra, a large collection of training data and pre-trained models for a wide variety of ancient Greek typefaces.
Named Entity Recognition and Classification on Historical Documents: A Survey
Sep 23, 2021

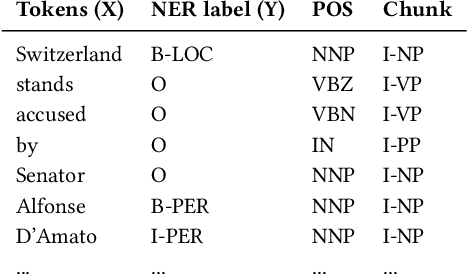

After decades of massive digitisation, an unprecedented amount of historical documents is available in digital format, along with their machine-readable texts. While this represents a major step forward with respect to preservation and accessibility, it also opens up new opportunities in terms of content mining and the next fundamental challenge is to develop appropriate technologies to efficiently search, retrieve and explore information from this 'big data of the past'. Among semantic indexing opportunities, the recognition and classification of named entities are in great demand among humanities scholars. Yet, named entity recognition (NER) systems are heavily challenged with diverse, historical and noisy inputs. In this survey, we present the array of challenges posed by historical documents to NER, inventory existing resources, describe the main approaches deployed so far, and identify key priorities for future developments.