 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDocILE Benchmark for Document Information Localization and Extraction
Feb 11, 2023


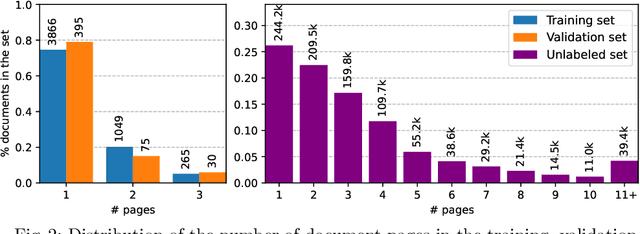
This paper introduces the DocILE benchmark with the largest dataset of business documents for the tasks of Key Information Localization and Extraction and Line Item Recognition. It contains 6.7k annotated business documents, 100k synthetically generated documents, and nearly~1M unlabeled documents for unsupervised pre-training. The dataset has been built with knowledge of domain- and task-specific aspects, resulting in the following key features: (i) annotations in 55 classes, which surpasses the granularity of previously published key information extraction datasets by a large margin; (ii) Line Item Recognition represents a highly practical information extraction task, where key information has to be assigned to items in a table; (iii) documents come from numerous layouts and the test set includes zero- and few-shot cases as well as layouts commonly seen in the training set. The benchmark comes with several baselines, including RoBERTa, LayoutLMv3 and DETR-based Table Transformer. These baseline models were applied to both tasks of the DocILE benchmark, with results shared in this paper, offering a quick starting point for future work. The dataset and baselines are available at https://github.com/rossumai/docile.
DocILE 2023 Teaser: Document Information Localization and Extraction
Jan 29, 2023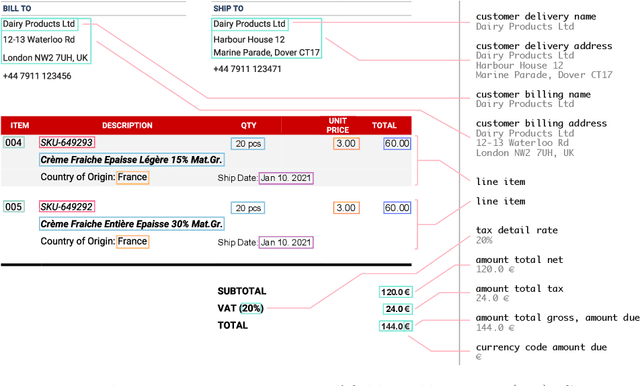
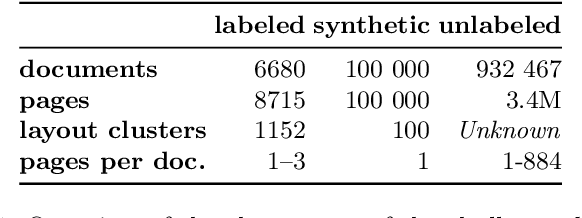


The lack of data for information extraction (IE) from semi-structured business documents is a real problem for the IE community. Publications relying on large-scale datasets use only proprietary, unpublished data due to the sensitive nature of such documents. Publicly available datasets are mostly small and domain-specific. The absence of a large-scale public dataset or benchmark hinders the reproducibility and cross-evaluation of published methods. The DocILE 2023 competition, hosted as a lab at the CLEF 2023 conference and as an ICDAR 2023 competition, will run the first major benchmark for the tasks of Key Information Localization and Extraction (KILE) and Line Item Recognition (LIR) from business documents. With thousands of annotated real documents from open sources, a hundred thousand of generated synthetic documents, and nearly a million unlabeled documents, the DocILE lab comes with the largest publicly available dataset for KILE and LIR. We are looking forward to contributions from the Computer Vision, Natural Language Processing, Information Retrieval, and other communities. The data, baselines, code and up-to-date information about the lab and competition are available at https://docile.rossum.ai/.
GLAMI-1M: A Multilingual Image-Text Fashion Dataset
Nov 17, 2022
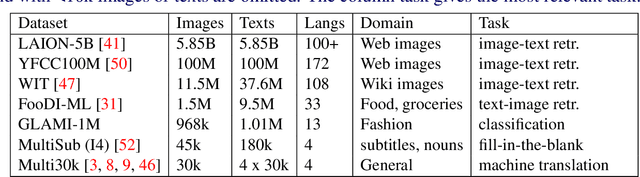
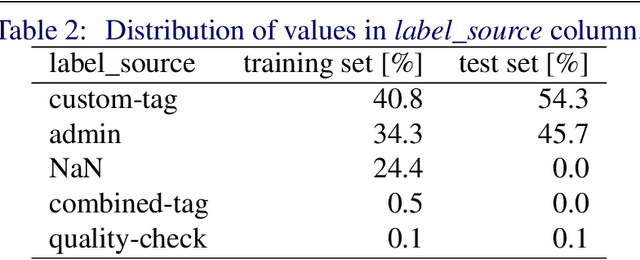
We introduce GLAMI-1M: the largest multilingual image-text classification dataset and benchmark. The dataset contains images of fashion products with item descriptions, each in 1 of 13 languages. Categorization into 191 classes has high-quality annotations: all 100k images in the test set and 75% of the 1M training set were human-labeled. The paper presents baselines for image-text classification showing that the dataset presents a challenging fine-grained classification problem: The best scoring EmbraceNet model using both visual and textual features achieves 69.7% accuracy. Experiments with a modified Imagen model show the dataset is also suitable for image generation conditioned on text. The dataset, source code and model checkpoints are published at https://github.com/glami/glami-1m
Text Detection Forgot About Document OCR
Oct 14, 2022


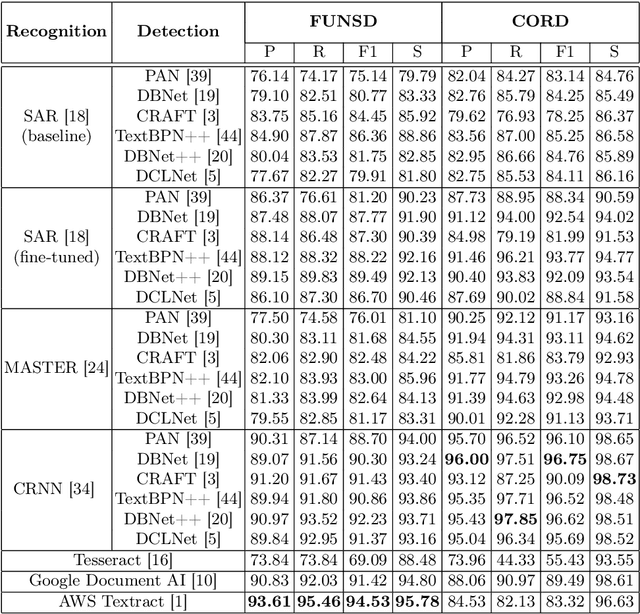
Detection and recognition of text from scans and other images, commonly denoted as Optical Character Recognition (OCR), is a widely used form of automated document processing with a number of methods available. Advances in machine learning enabled even more challenging scenarios of text detection and recognition "in-the-wild" - such as detecting text on objects from photographs of complex scenes. While the state-of-the-art methods for in-the-wild text recognition are typically evaluated on complex scenes, their performance in the domain of documents has not been published. This paper compares several methods designed for in-the-wild text recognition and for document text recognition, and provides their evaluation on the domain of structured documents. The results suggest that state-of-the-art methods originally proposed for in-the-wild text detection also achieve excellent results on document text detection, outperforming available OCR methods. We argue that the application of document OCR should not be omitted in evaluation of text detection and recognition methods.
Business Document Information Extraction: Towards Practical Benchmarks
Jun 20, 2022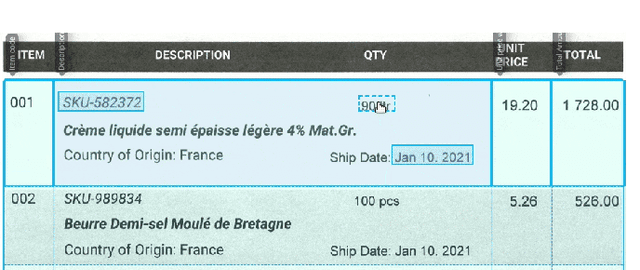
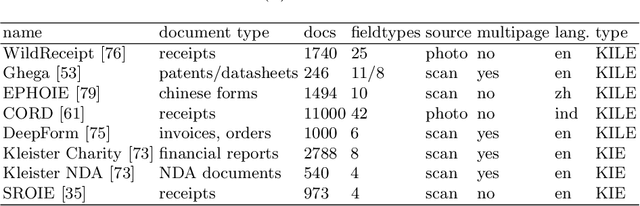
Information extraction from semi-structured documents is crucial for frictionless business-to-business (B2B) communication. While machine learning problems related to Document Information Extraction (IE) have been studied for decades, many common problem definitions and benchmarks do not reflect domain-specific aspects and practical needs for automating B2B document communication. We review the landscape of Document IE problems, datasets and benchmarks. We highlight the practical aspects missing in the common definitions and define the Key Information Localization and Extraction (KILE) and Line Item Recognition (LIR) problems. There is a lack of relevant datasets and benchmarks for Document IE on semi-structured business documents as their content is typically legally protected or sensitive. We discuss potential sources of available documents including synthetic data.
Danish Fungi 2020 -- Not Just Another Image Recognition Dataset
Mar 22, 2021
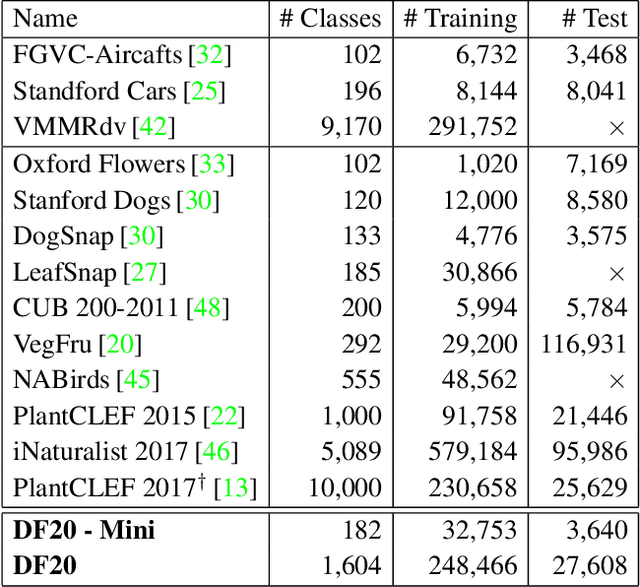
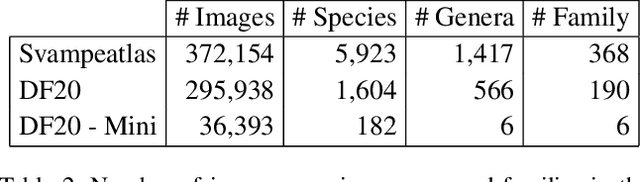
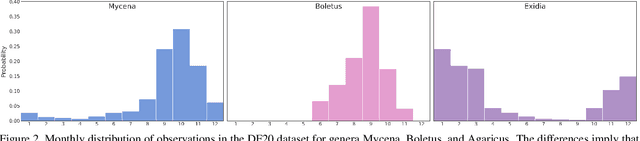
We introduce a novel fine-grained dataset and benchmark, the Danish Fungi 2020 (DF20). The dataset, constructed from observations submitted to the Danish Fungal Atlas, is unique in its taxonomy-accurate class labels, small number of errors, highly unbalanced long-tailed class distribution, rich observation metadata, and well-defined class hierarchy. DF20 has zero overlap with ImageNet, allowing unbiased comparison of models fine-tuned from publicly available ImageNet checkpoints. The proposed evaluation protocol enables testing the ability to improve classification using metadata -- e.g. precise geographic location, habitat, and substrate, facilitates classifier calibration testing, and finally allows to study the impact of the device settings on the classification performance. Experiments using Convolutional Neural Networks (CNN) and the recent Vision Transformers (ViT) show that DF20 presents a challenging task. Interestingly, ViT achieves results superior to CNN baselines with 81.25% accuracy, reducing the CNN error by 13%. A baseline procedure for including metadata into the decision process improves the classification accuracy by more than 3.5 percentage points, reducing the error rate by 20%. The source code for all methods and experiments is available at https://sites.google.com/view/danish-fungi-dataset.