 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGLAMI-1M: A Multilingual Image-Text Fashion Dataset
Paper and Code

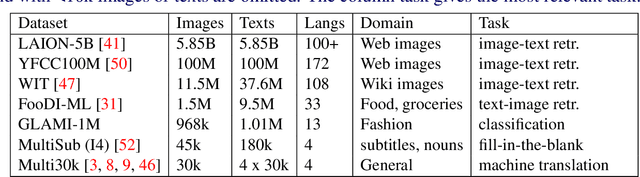
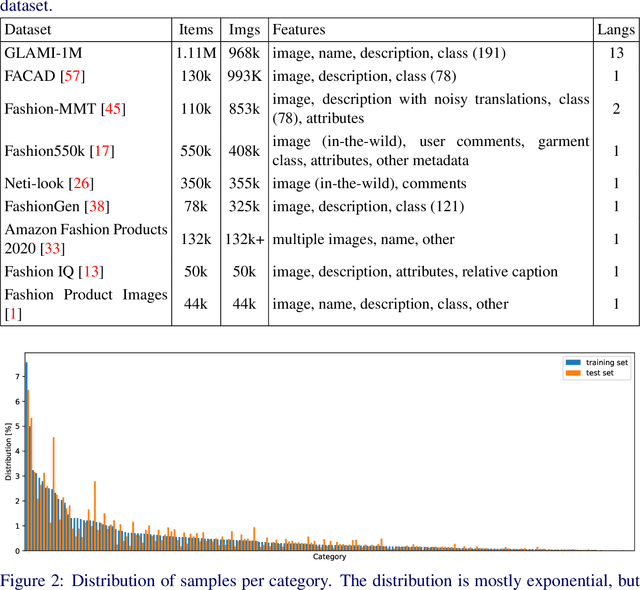
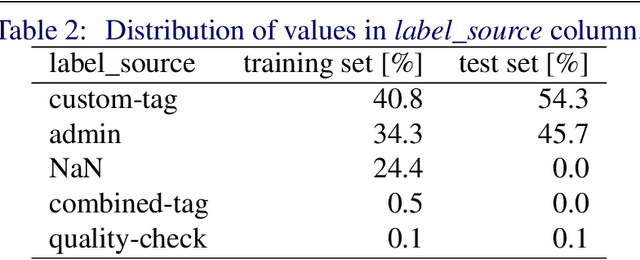
We introduce GLAMI-1M: the largest multilingual image-text classification dataset and benchmark. The dataset contains images of fashion products with item descriptions, each in 1 of 13 languages. Categorization into 191 classes has high-quality annotations: all 100k images in the test set and 75% of the 1M training set were human-labeled. The paper presents baselines for image-text classification showing that the dataset presents a challenging fine-grained classification problem: The best scoring EmbraceNet model using both visual and textual features achieves 69.7% accuracy. Experiments with a modified Imagen model show the dataset is also suitable for image generation conditioned on text. The dataset, source code and model checkpoints are published at https://github.com/glami/glami-1m