 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDocILE 2023 Teaser: Document Information Localization and Extraction
Paper and Code
Jan 29, 2023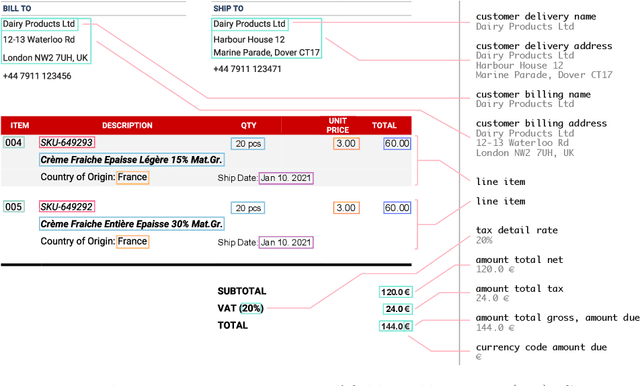
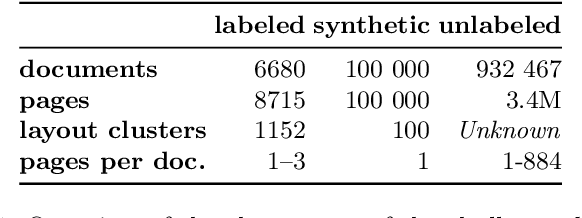


The lack of data for information extraction (IE) from semi-structured business documents is a real problem for the IE community. Publications relying on large-scale datasets use only proprietary, unpublished data due to the sensitive nature of such documents. Publicly available datasets are mostly small and domain-specific. The absence of a large-scale public dataset or benchmark hinders the reproducibility and cross-evaluation of published methods. The DocILE 2023 competition, hosted as a lab at the CLEF 2023 conference and as an ICDAR 2023 competition, will run the first major benchmark for the tasks of Key Information Localization and Extraction (KILE) and Line Item Recognition (LIR) from business documents. With thousands of annotated real documents from open sources, a hundred thousand of generated synthetic documents, and nearly a million unlabeled documents, the DocILE lab comes with the largest publicly available dataset for KILE and LIR. We are looking forward to contributions from the Computer Vision, Natural Language Processing, Information Retrieval, and other communities. The data, baselines, code and up-to-date information about the lab and competition are available at https://docile.rossum.ai/.