 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeText Detection Forgot About Document OCR
Paper and Code
Oct 14, 2022


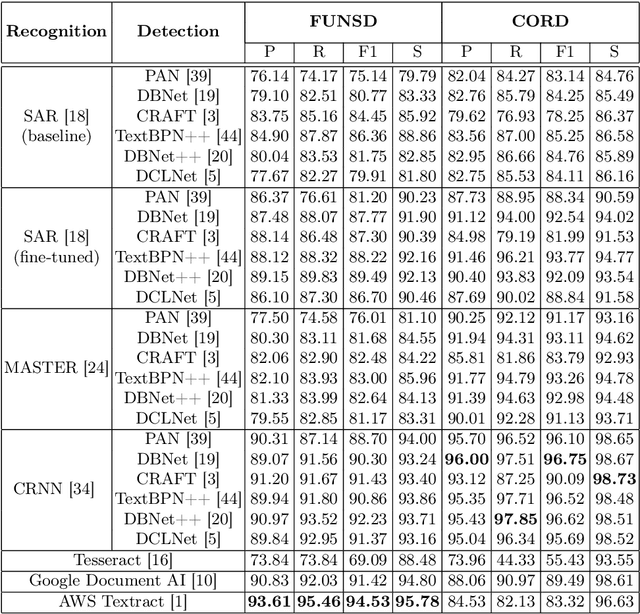
Detection and recognition of text from scans and other images, commonly denoted as Optical Character Recognition (OCR), is a widely used form of automated document processing with a number of methods available. Advances in machine learning enabled even more challenging scenarios of text detection and recognition "in-the-wild" - such as detecting text on objects from photographs of complex scenes. While the state-of-the-art methods for in-the-wild text recognition are typically evaluated on complex scenes, their performance in the domain of documents has not been published. This paper compares several methods designed for in-the-wild text recognition and for document text recognition, and provides their evaluation on the domain of structured documents. The results suggest that state-of-the-art methods originally proposed for in-the-wild text detection also achieve excellent results on document text detection, outperforming available OCR methods. We argue that the application of document OCR should not be omitted in evaluation of text detection and recognition methods.