 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhat are the Right Symmetries for Formal Theorem Proving?
May 21, 2026Formal theorem provers based on large language models (LLMs) are highly sensitive to superficial variations in problem representation: semantically equivalent statements can exhibit drastically different proof success rates, revealing a failure to respect structural symmetries inherent in formal mathematics. This raises a central question: what are the right symmetries for formal theorem proving? We introduce rewriting categories, a category-theoretic framework capturing the compositional, generally non-invertible transformations induced by proof tactics, and use it to formalize two symmetry notions: proof equivariance, governing how proof distributions transform under rewrites, and success invariance (i.e., invariance of success probability), requiring equivalent statements to be solved with the same probability. We observe that state-based next-tactic provers naturally satisfy proof equivariance by operating on proof states. In contrast, state-of-the-art LLM-based provers satisfy neither property, exhibiting large performance variation across equivalent formulations. To mitigate this, we propose test-time methods that aggregate over equivalent rewritings of the input, showing theoretically that they recover success invariance in the sampling limit, and empirically, that they improve robustness and performance under fixed inference budgets. Our results highlight symmetry as a key missing inductive bias in LLM-based theorem proving and suggest test-time computation as a practical route to approximate it.
Flock: A Knowledge Graph Foundation Model via Learning on Random Walks
Oct 01, 2025We study the problem of zero-shot link prediction on knowledge graphs (KGs), which requires models to generalize over novel entities and novel relations. Knowledge graph foundation models (KGFMs) address this task by enforcing equivariance over both nodes and relations, learning from structural properties of nodes and relations, which are then transferable to novel graphs with similar structural properties. However, the conventional notion of deterministic equivariance imposes inherent limits on the expressive power of KGFMs, preventing them from distinguishing structurally similar but semantically distinct relations. To overcome this limitation, we introduce probabilistic node-relation equivariance, which preserves equivariance in distribution while incorporating a principled randomization to break symmetries during inference. Building on this principle, we present Flock, a KGFM that iteratively samples random walks, encodes them into sequences via a recording protocol, embeds them with a sequence model, and aggregates representations of nodes and relations via learned pooling. Crucially, Flock respects probabilistic node-relation equivariance and is a universal approximator for isomorphism-invariant link-level functions over KGs. Empirically, Flock perfectly solves our new diagnostic dataset Petals where current KGFMs fail, and achieves state-of-the-art performances on entity- and relation prediction tasks on 54 KGs from diverse domains.
One Model, Any Conjunctive Query: Graph Neural Networks for Answering Complex Queries over Knowledge Graphs
Sep 21, 2024



Traditional query answering over knowledge graphs -- or broadly over relational data -- is one of the most fundamental problems in data management. Motivated by the incompleteness of modern knowledge graphs, a new setup for query answering has emerged, where the goal is to predict answers that do not necessarily appear in the knowledge graph, but are present in its completion. In this work, we propose AnyCQ, a graph neural network model that can classify answers to any conjunctive query on any knowledge graph, following training. At the core of our framework lies a graph neural network model trained using a reinforcement learning objective to answer Boolean queries. Our approach and problem setup differ from existing query answering studies in multiple dimensions. First, we focus on the problem of query answer classification: given a query and a set of possible answers, classify these proposals as true or false relative to the complete knowledge graph. Second, we study the problem of query answer retrieval: given a query, retrieve an answer to the query relative to the complete knowledge graph or decide that no correct solutions exist. Trained on simple, small instances, AnyCQ can generalize to large queries of arbitrary structure, reliably classifying and retrieving answers to samples where existing approaches fail, which is empirically validated on new and challenging benchmarks. Furthermore, we demonstrate that our AnyCQ models effectively transfer to out-of-distribution knowledge graphs, when equipped with a relevant link predictor, highlighting their potential to serve as a general engine for query answering.
Text Detection Forgot About Document OCR
Oct 14, 2022


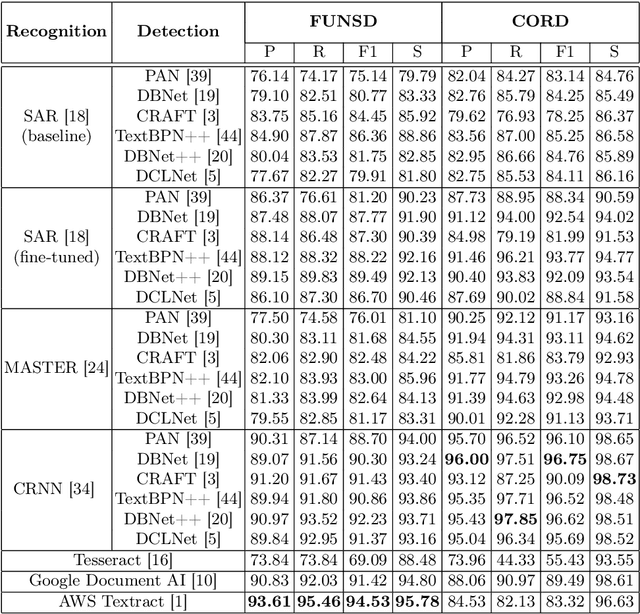
Detection and recognition of text from scans and other images, commonly denoted as Optical Character Recognition (OCR), is a widely used form of automated document processing with a number of methods available. Advances in machine learning enabled even more challenging scenarios of text detection and recognition "in-the-wild" - such as detecting text on objects from photographs of complex scenes. While the state-of-the-art methods for in-the-wild text recognition are typically evaluated on complex scenes, their performance in the domain of documents has not been published. This paper compares several methods designed for in-the-wild text recognition and for document text recognition, and provides their evaluation on the domain of structured documents. The results suggest that state-of-the-art methods originally proposed for in-the-wild text detection also achieve excellent results on document text detection, outperforming available OCR methods. We argue that the application of document OCR should not be omitted in evaluation of text detection and recognition methods.