 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDINOv3 as a Frozen Encoder for CRPS-Oriented Probabilistic Rainfall Nowcasting
Nov 19, 2025This paper proposes a competitive and computationally efficient approach to probabilistic rainfall nowcasting. A video projector (V-JEPA Vision Transformer) associated to a lightweight probabilistic head is attached to a pre-trained satellite vision encoder (DINOv3-SAT493M) to map encoder tokens into a discrete empirical CDF (eCDF) over 4-hour accumulated rainfall. The projector-head is optimized end-to-end over the Ranked Probability Score (RPS). As an alternative, 3D-UNET baselines trained with an aggregate Rank Probability Score and a per-pixel Gamma-Hurdle objective are used. On the Weather4Cast 2025 benchmark, the proposed method achieved a promising performance, with a CRPS of 3.5102, which represents $\approx$ 26% in effectiveness gain against the best 3D-UNET.
SeaTurtleID2022: A long-span dataset for reliable sea turtle re-identification
Nov 09, 2023



This paper introduces the first public large-scale, long-span dataset with sea turtle photographs captured in the wild -- SeaTurtleID2022 (https://www.kaggle.com/datasets/wildlifedatasets/seaturtleid2022). The dataset contains 8729 photographs of 438 unique individuals collected within 13 years, making it the longest-spanned dataset for animal re-identification. All photographs include various annotations, e.g., identity, encounter timestamp, and body parts segmentation masks. Instead of standard "random" splits, the dataset allows for two realistic and ecologically motivated splits: (i) a time-aware closed-set with training, validation, and test data from different days/years, and (ii) a time-aware open-set with new unknown individuals in test and validation sets. We show that time-aware splits are essential for benchmarking re-identification methods, as random splits lead to performance overestimation. Furthermore, a baseline instance segmentation and re-identification performance over various body parts is provided. Finally, an end-to-end system for sea turtle re-identification is proposed and evaluated. The proposed system based on Hybrid Task Cascade for head instance segmentation and ArcFace-trained feature-extractor achieved an accuracy of 86.8%.
SeaTurtleID: A novel long-span dataset highlighting the importance of timestamps in wildlife re-identification
Nov 18, 2022This paper introduces SeaTurtleID, the first public large-scale, long-span dataset with sea turtle photographs captured in the wild. The dataset is suitable for benchmarking re-identification methods and evaluating several other computer vision tasks. The dataset consists of 7774 high-resolution photographs of 400 unique individuals collected within 12 years in 1081 encounters. Each photograph is accompanied by rich metadata, e.g., identity label, head segmentation mask, and encounter timestamp. The 12-year span of the dataset makes it the longest-spanned public wild animal dataset with timestamps. By exploiting this unique property, we show that timestamps are necessary for an unbiased evaluation of animal re-identification methods because they allow time-aware splits of the dataset into reference and query sets. We show that time-unaware splits can lead to performance overestimation of more than 100% compared to the time-aware splits for both feature- and CNN-based re-identification methods. We also argue that time-aware splits correspond to more realistic re-identification pipelines than the time-unaware ones. We recommend that animal re-identification methods should only be tested on datasets with timestamps using time-aware splits, and we encourage dataset curators to include such information in the associated metadata.
Danish Fungi 2020 -- Not Just Another Image Recognition Dataset
Mar 22, 2021
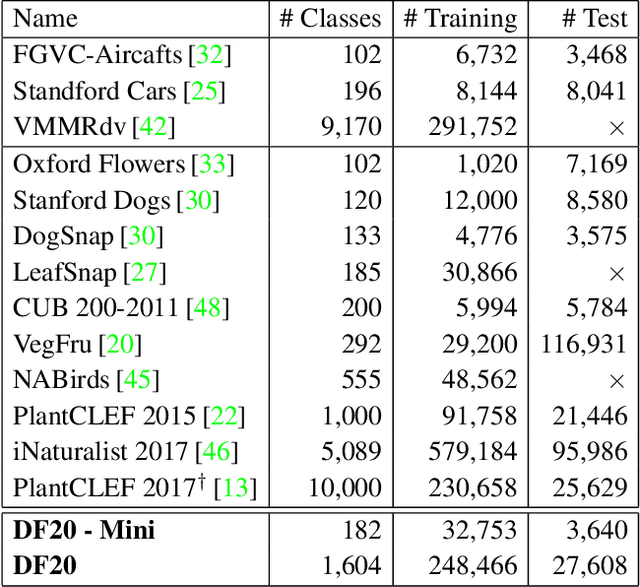
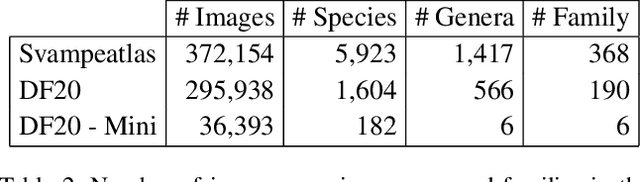
We introduce a novel fine-grained dataset and benchmark, the Danish Fungi 2020 (DF20). The dataset, constructed from observations submitted to the Danish Fungal Atlas, is unique in its taxonomy-accurate class labels, small number of errors, highly unbalanced long-tailed class distribution, rich observation metadata, and well-defined class hierarchy. DF20 has zero overlap with ImageNet, allowing unbiased comparison of models fine-tuned from publicly available ImageNet checkpoints. The proposed evaluation protocol enables testing the ability to improve classification using metadata -- e.g. precise geographic location, habitat, and substrate, facilitates classifier calibration testing, and finally allows to study the impact of the device settings on the classification performance. Experiments using Convolutional Neural Networks (CNN) and the recent Vision Transformers (ViT) show that DF20 presents a challenging task. Interestingly, ViT achieves results superior to CNN baselines with 81.25% accuracy, reducing the CNN error by 13%. A baseline procedure for including metadata into the decision process improves the classification accuracy by more than 3.5 percentage points, reducing the error rate by 20%. The source code for all methods and experiments is available at https://sites.google.com/view/danish-fungi-dataset.
Mastering Large Scale Multi-label Image Recognition with high efficiency overCamera trap images
Aug 18, 2020

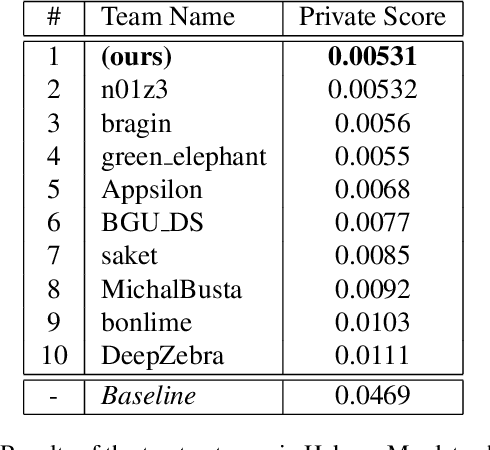
Camera traps are crucial in biodiversity motivated studies, however dealing with large number of images while annotating these data sets is a tedious and time consuming task. To speed up this process, Machine Learning approaches are a reasonable asset. In this article we are proposing an easy, accessible, light-weight, fast and efficient approach based on our winning submission to the "Hakuna Ma-data - Serengeti Wildlife Identification challenge". Our system achieved an Accuracy of 97% and outperformed the human level performance. We show that, given relatively large data sets, it is effective to look at each image only once with little or no augmentation. By utilizing such a simple, yet effective baseline we were able to avoid over-fitting without extensive regularization techniques and to train a top scoring system on a very limited hardware featuring single GPU (1080Ti) despite the large training set (6.7M images and 6TB).