 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMastering Large Scale Multi-label Image Recognition with high efficiency overCamera trap images
Aug 18, 2020

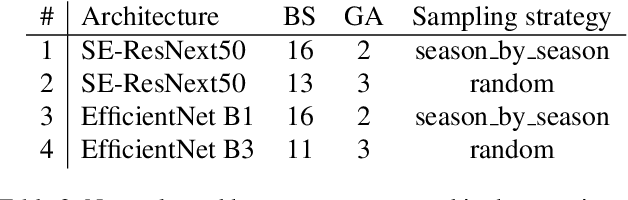
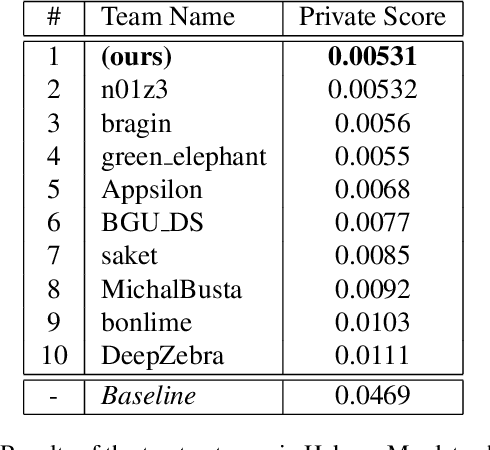
Camera traps are crucial in biodiversity motivated studies, however dealing with large number of images while annotating these data sets is a tedious and time consuming task. To speed up this process, Machine Learning approaches are a reasonable asset. In this article we are proposing an easy, accessible, light-weight, fast and efficient approach based on our winning submission to the "Hakuna Ma-data - Serengeti Wildlife Identification challenge". Our system achieved an Accuracy of 97% and outperformed the human level performance. We show that, given relatively large data sets, it is effective to look at each image only once with little or no augmentation. By utilizing such a simple, yet effective baseline we were able to avoid over-fitting without extensive regularization techniques and to train a top scoring system on a very limited hardware featuring single GPU (1080Ti) despite the large training set (6.7M images and 6TB).