 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeACCIDENT: A Benchmark Dataset for Vehicle Accident Detection from Traffic Surveillance Videos
Apr 10, 2026We introduce ACCIDENT, a benchmark dataset for traffic accident detection in CCTV footage, designed to evaluate models in supervised (IID and OOD) and zero-shot settings, reflecting both data-rich and data-scarce scenarios. The benchmark consists of a curated set of 2,027 real and 2,211 synthetic clips annotated with the accident time, spatial location, and high-level collision type. We define three core tasks: (i) temporal localization of the accident, (ii) its spatial localization, and (iii) collision type classification. Each task is evaluated using custom metrics that account for the uncertainty and ambiguity inherent in CCTV footage. In addition to the benchmark, we provide a diverse set of baselines, including heuristic, motion-aware, and vision-language approaches, and show that ACCIDENT is challenging. You can access the ACCIDENT at: https://accidentbench.github.io
Zero-shot Hazard Identification in Autonomous Driving: A Case Study on the COOOL Benchmark
Dec 27, 2024
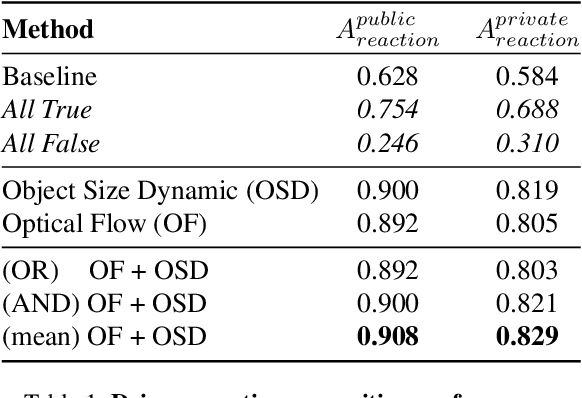


This paper presents our submission to the COOOL competition, a novel benchmark for detecting and classifying out-of-label hazards in autonomous driving. Our approach integrates diverse methods across three core tasks: (i) driver reaction detection, (ii) hazard object identification, and (iii) hazard captioning. We propose kernel-based change point detection on bounding boxes and optical flow dynamics for driver reaction detection to analyze motion patterns. For hazard identification, we combined a naive proximity-based strategy with object classification using a pre-trained ViT model. At last, for hazard captioning, we used the MOLMO vision-language model with tailored prompts to generate precise and context-aware descriptions of rare and low-resolution hazards. The proposed pipeline outperformed the baseline methods by a large margin, reducing the relative error by 33%, and scored 2nd on the final leaderboard consisting of 32 teams.
WildlifeReID-10k: Wildlife re-identification dataset with 10k individual animals
Jun 17, 2024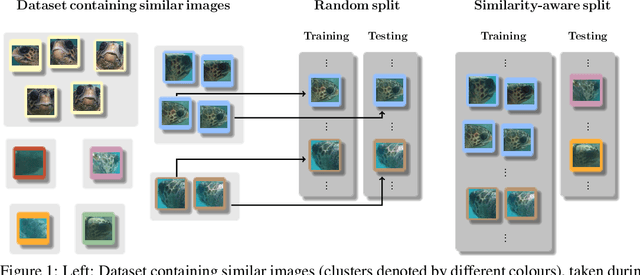



We introduce a new wildlife re-identification dataset WildlifeReID-10k with more than 214k images of 10k individual animals. It is a collection of 30 existing wildlife re-identification datasets with additional processing steps. WildlifeReID-10k contains animals as diverse as marine turtles, primates, birds, African herbivores, marine mammals and domestic animals. Due to the ubiquity of similar images in datasets, we argue that the standard (random) splits into training and testing sets are inadequate for wildlife re-identification and propose a new similarity-aware split based on the similarity of extracted features. To promote fair method comparison, we include similarity-aware splits both for closed-set and open-set settings, use MegaDescriptor - a foundational model for wildlife re-identification - for baseline performance and host a leaderboard with the best results. We publicly publish the dataset and the codes used to create it in the wildlife-datasets library, making WildlifeReID-10k both highly curated and easy to use.
WildlifeDatasets: An open-source toolkit for animal re-identification
Nov 15, 2023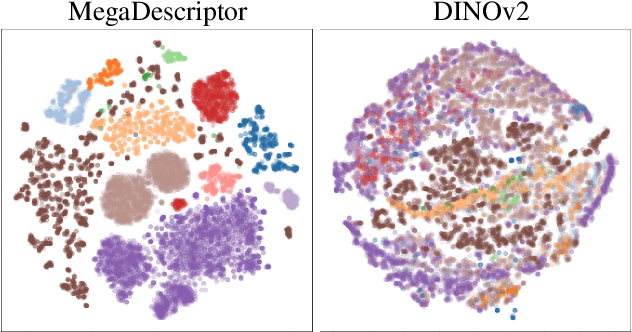
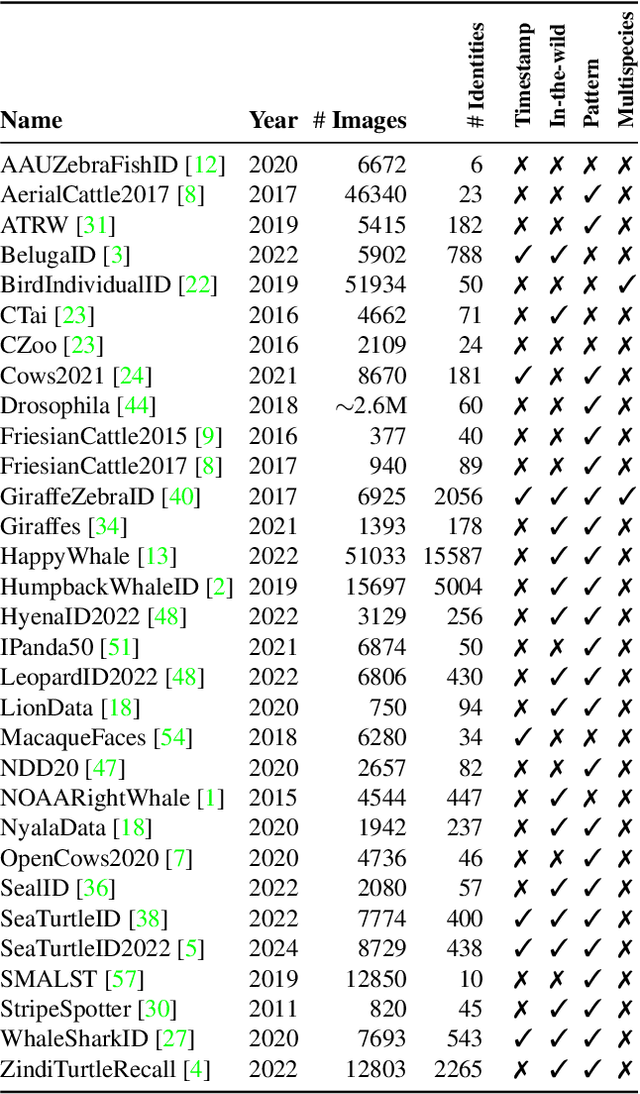


In this paper, we present WildlifeDatasets (https://github.com/WildlifeDatasets/wildlife-datasets) - an open-source toolkit intended primarily for ecologists and computer-vision / machine-learning researchers. The WildlifeDatasets is written in Python, allows straightforward access to publicly available wildlife datasets, and provides a wide variety of methods for dataset pre-processing, performance analysis, and model fine-tuning. We showcase the toolkit in various scenarios and baseline experiments, including, to the best of our knowledge, the most comprehensive experimental comparison of datasets and methods for wildlife re-identification, including both local descriptors and deep learning approaches. Furthermore, we provide the first-ever foundation model for individual re-identification within a wide range of species - MegaDescriptor - that provides state-of-the-art performance on animal re-identification datasets and outperforms other pre-trained models such as CLIP and DINOv2 by a significant margin. To make the model available to the general public and to allow easy integration with any existing wildlife monitoring applications, we provide multiple MegaDescriptor flavors (i.e., Small, Medium, and Large) through the HuggingFace hub (https://huggingface.co/BVRA).
SeaTurtleID2022: A long-span dataset for reliable sea turtle re-identification
Nov 09, 2023



This paper introduces the first public large-scale, long-span dataset with sea turtle photographs captured in the wild -- SeaTurtleID2022 (https://www.kaggle.com/datasets/wildlifedatasets/seaturtleid2022). The dataset contains 8729 photographs of 438 unique individuals collected within 13 years, making it the longest-spanned dataset for animal re-identification. All photographs include various annotations, e.g., identity, encounter timestamp, and body parts segmentation masks. Instead of standard "random" splits, the dataset allows for two realistic and ecologically motivated splits: (i) a time-aware closed-set with training, validation, and test data from different days/years, and (ii) a time-aware open-set with new unknown individuals in test and validation sets. We show that time-aware splits are essential for benchmarking re-identification methods, as random splits lead to performance overestimation. Furthermore, a baseline instance segmentation and re-identification performance over various body parts is provided. Finally, an end-to-end system for sea turtle re-identification is proposed and evaluated. The proposed system based on Hybrid Task Cascade for head instance segmentation and ArcFace-trained feature-extractor achieved an accuracy of 86.8%.
SeaTurtleID: A novel long-span dataset highlighting the importance of timestamps in wildlife re-identification
Nov 18, 2022This paper introduces SeaTurtleID, the first public large-scale, long-span dataset with sea turtle photographs captured in the wild. The dataset is suitable for benchmarking re-identification methods and evaluating several other computer vision tasks. The dataset consists of 7774 high-resolution photographs of 400 unique individuals collected within 12 years in 1081 encounters. Each photograph is accompanied by rich metadata, e.g., identity label, head segmentation mask, and encounter timestamp. The 12-year span of the dataset makes it the longest-spanned public wild animal dataset with timestamps. By exploiting this unique property, we show that timestamps are necessary for an unbiased evaluation of animal re-identification methods because they allow time-aware splits of the dataset into reference and query sets. We show that time-unaware splits can lead to performance overestimation of more than 100% compared to the time-aware splits for both feature- and CNN-based re-identification methods. We also argue that time-aware splits correspond to more realistic re-identification pipelines than the time-unaware ones. We recommend that animal re-identification methods should only be tested on datasets with timestamps using time-aware splits, and we encourage dataset curators to include such information in the associated metadata.
Adversarial examples by perturbing high-level features in intermediate decoder layers
Oct 14, 2021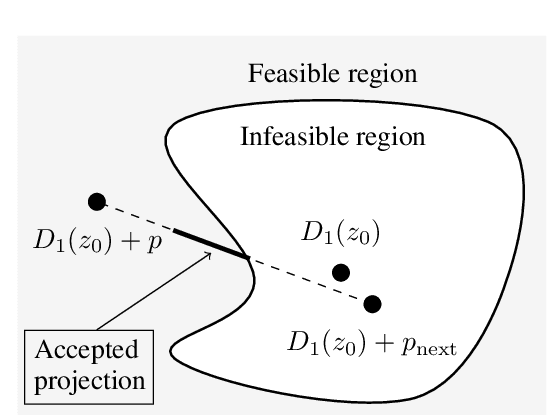

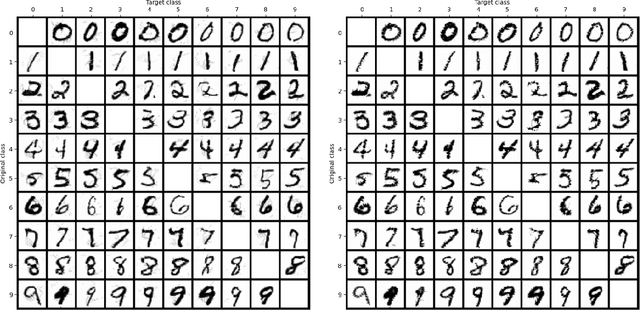
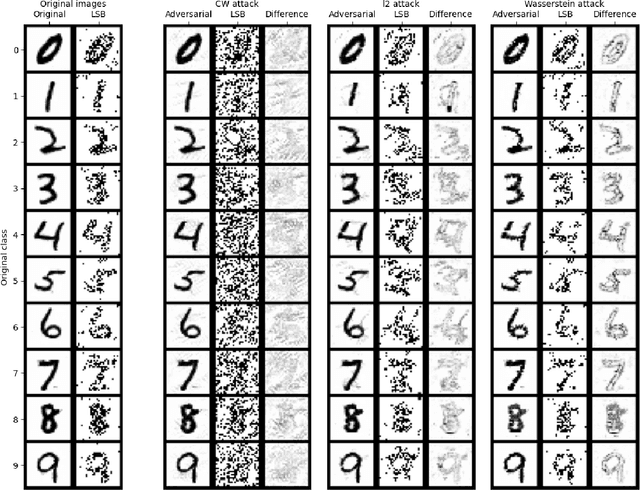
We propose a novel method for creating adversarial examples. Instead of perturbing pixels, we use an encoder-decoder representation of the input image and perturb intermediate layers in the decoder. This changes the high-level features provided by the generative model. Therefore, our perturbation possesses semantic meaning, such as a longer beak or green tints. We formulate this task as an optimization problem by minimizing the Wasserstein distance between the adversarial and initial images under a misclassification constraint. We employ the projected gradient method with a simple inexact projection. Due to the projection, all iterations are feasible, and our method always generates adversarial images. We perform numerical experiments on the MNIST and ImageNet datasets in both targeted and untargeted settings. We demonstrate that our adversarial images are much less vulnerable to steganographic defence techniques than pixel-based attacks. Moreover, we show that our method modifies key features such as edges and that defence techniques based on adversarial training are vulnerable to our attacks.