 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExtending Neural Keyword Extraction with TF-IDF tagset matching
Paper and Code
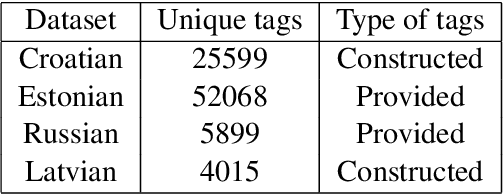
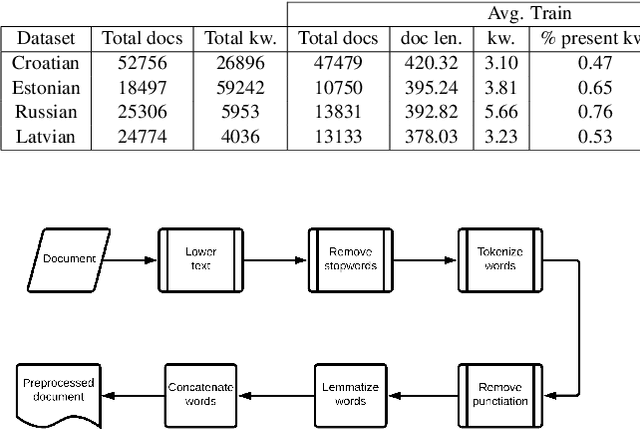

Keyword extraction is the task of identifying words (or multi-word expressions) that best describe a given document and serve in news portals to link articles of similar topics. In this work we develop and evaluate our methods on four novel data sets covering less represented, morphologically-rich languages in European news media industry (Croatian, Estonian, Latvian and Russian). First, we perform evaluation of two supervised neural transformer-based methods (TNT-KID and BERT+BiLSTM CRF) and compare them to a baseline TF-IDF based unsupervised approach. Next, we show that by combining the keywords retrieved by both neural transformer based methods and extending the final set of keywords with an unsupervised TF-IDF based technique, we can drastically improve the recall of the system, making it appropriate to be used as a recommendation system in the media house environment.