 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe First Shared Task on Discourse Representation Structure Parsing
May 27, 2020
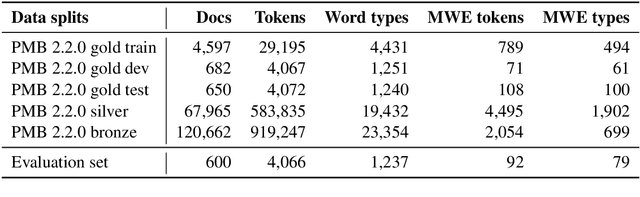

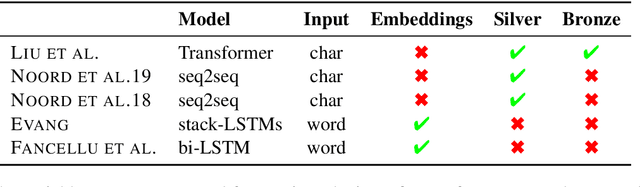
The paper presents the IWCS 2019 shared task on semantic parsing where the goal is to produce Discourse Representation Structures (DRSs) for English sentences. DRSs originate from Discourse Representation Theory and represent scoped meaning representations that capture the semantics of negation, modals, quantification, and presupposition triggers. Additionally, concepts and event-participants in DRSs are described with WordNet synsets and the thematic roles from VerbNet. To measure similarity between two DRSs, they are represented in a clausal form, i.e. as a set of tuples. Participant systems were expected to produce DRSs in this clausal form. Taking into account the rich lexical information, explicit scope marking, a high number of shared variables among clauses, and highly-constrained format of valid DRSs, all these makes the DRS parsing a challenging NLP task. The results of the shared task displayed improvements over the existing state-of-the-art parser.
* International Conference on Computational Semantics (IWCS)
Casting a Wide Net: Robust Extraction of Potentially Idiomatic Expressions
Nov 20, 2019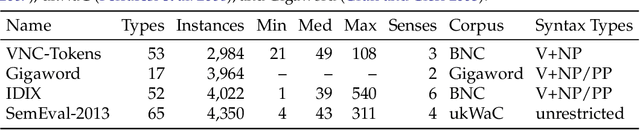



Idiomatic expressions like `out of the woods' and `up the ante' present a range of difficulties for natural language processing applications. We present work on the annotation and extraction of what we term potentially idiomatic expressions (PIEs), a subclass of multiword expressions covering both literal and non-literal uses of idiomatic expressions. Existing corpora of PIEs are small and have limited coverage of different PIE types, which hampers research. To further progress on the extraction and disambiguation of potentially idiomatic expressions, larger corpora of PIEs are required. In addition, larger corpora are a potential source for valuable linguistic insights into idiomatic expressions and their variability. We propose automatic tools to facilitate the building of larger PIE corpora, by investigating the feasibility of using dictionary-based extraction of PIEs as a pre-extraction tool for English. We do this by assessing the reliability and coverage of idiom dictionaries, the annotation of a PIE corpus, and the automatic extraction of PIEs from a large corpus. Results show that combinations of dictionaries are a reliable source of idiomatic expressions, that PIEs can be annotated with a high reliability (0.74-0.91 Fleiss' Kappa), and that parse-based PIE extraction yields highly accurate performance (88% F1-score). Combining complementary PIE extraction methods increases reliability further, to over 92% F1-score. Moreover, the extraction method presented here could be extended to other types of multiword expressions and to other languages, given that sufficient NLP tools are available.
Evaluating Scoped Meaning Representations
Apr 10, 2018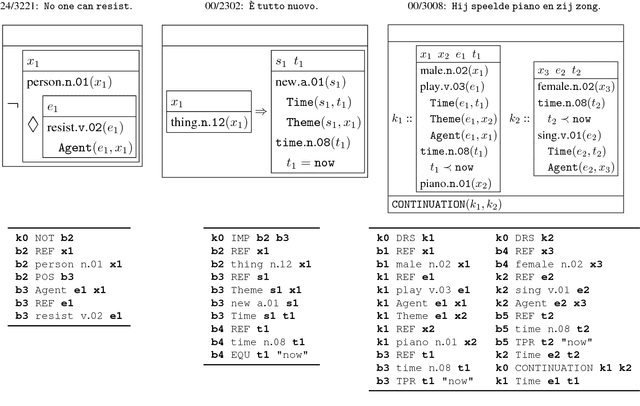

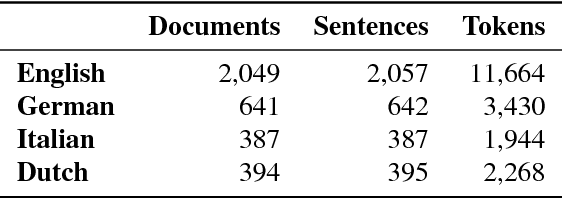

Semantic parsing offers many opportunities to improve natural language understanding. We present a semantically annotated parallel corpus for English, German, Italian, and Dutch where sentences are aligned with scoped meaning representations in order to capture the semantics of negation, modals, quantification, and presupposition triggers. The semantic formalism is based on Discourse Representation Theory, but concepts are represented by WordNet synsets and thematic roles by VerbNet relations. Translating scoped meaning representations to sets of clauses enables us to compare them for the purpose of semantic parser evaluation and checking translations. This is done by computing precision and recall on matching clauses, in a similar way as is done for Abstract Meaning Representations. We show that our matching tool for evaluating scoped meaning representations is both accurate and efficient. Applying this matching tool to three baseline semantic parsers yields F-scores between 43% and 54%. A pilot study is performed to automatically find changes in meaning by comparing meaning representations of translations. This comparison turns out to be an additional way of (i) finding annotation mistakes and (ii) finding instances where our semantic analysis needs to be improved.
N-GrAM: New Groningen Author-profiling Model
Jul 12, 2017



We describe our participation in the PAN 2017 shared task on Author Profiling, identifying authors' gender and language variety for English, Spanish, Arabic and Portuguese. We describe both the final, submitted system, and a series of negative results. Our aim was to create a single model for both gender and language, and for all language varieties. Our best-performing system (on cross-validated results) is a linear support vector machine (SVM) with word unigrams and character 3- to 5-grams as features. A set of additional features, including POS tags, additional datasets, geographic entities, and Twitter handles, hurt, rather than improve, performance. Results from cross-validation indicated high performance overall and results on the test set confirmed them, at 0.86 averaged accuracy, with performance on sub-tasks ranging from 0.68 to 0.98.
The Parallel Meaning Bank: Towards a Multilingual Corpus of Translations Annotated with Compositional Meaning Representations
Feb 13, 2017
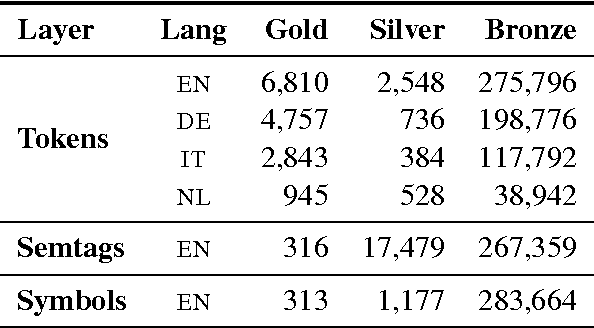
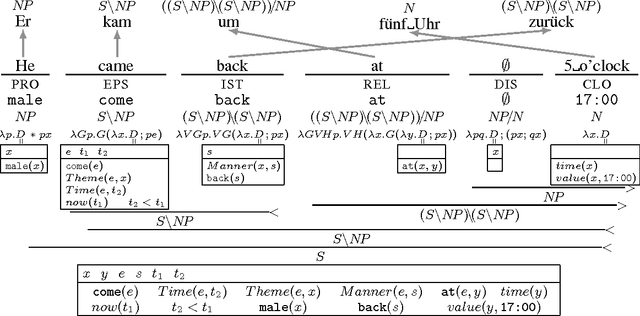
The Parallel Meaning Bank is a corpus of translations annotated with shared, formal meaning representations comprising over 11 million words divided over four languages (English, German, Italian, and Dutch). Our approach is based on cross-lingual projection: automatically produced (and manually corrected) semantic annotations for English sentences are mapped onto their word-aligned translations, assuming that the translations are meaning-preserving. The semantic annotation consists of five main steps: (i) segmentation of the text in sentences and lexical items; (ii) syntactic parsing with Combinatory Categorial Grammar; (iii) universal semantic tagging; (iv) symbolization; and (v) compositional semantic analysis based on Discourse Representation Theory. These steps are performed using statistical models trained in a semi-supervised manner. The employed annotation models are all language-neutral. Our first results are promising.