 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOpenLID-v3: Improving the Precision of Closely Related Language Identification -- An Experience Report
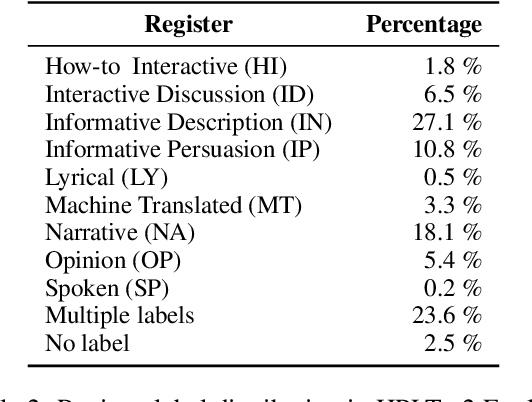
Feb 13, 2026Language identification (LID) is an essential step in building high-quality multilingual datasets from web data. Existing LID tools (such as OpenLID or GlotLID) often struggle to identify closely related languages and to distinguish valid natural language from noise, which contaminates language-specific subsets, especially for low-resource languages. In this work we extend the OpenLID classifier by adding more training data, merging problematic language variant clusters, and introducing a special label for marking noise. We call this extended system OpenLID-v3 and evaluate it against GlotLID on multiple benchmarks. During development, we focus on three groups of closely related languages (Bosnian, Croatian, and Serbian; Romance varieties of Northern Italy and Southern France; and Scandinavian languages) and contribute new evaluation datasets where existing ones are inadequate. We find that ensemble approaches improve precision but also substantially reduce coverage for low-resource languages. OpenLID-v3 is available on https://huggingface.co/HPLT/OpenLID-v3.
An Expanded Massive Multilingual Dataset for High-Performance Language Technologies
Mar 13, 2025


Training state-of-the-art large language models requires vast amounts of clean and diverse textual data. However, building suitable multilingual datasets remains a challenge. In this work, we present HPLT v2, a collection of high-quality multilingual monolingual and parallel corpora. The monolingual portion of the data contains 8T tokens covering 193 languages, while the parallel data contains 380M sentence pairs covering 51 languages. We document the entire data pipeline and release the code to reproduce it. We provide extensive analysis of the quality and characteristics of our data. Finally, we evaluate the performance of language models and machine translation systems trained on HPLT v2, demonstrating its value.
The Impact of Copyrighted Material on Large Language Models: A Norwegian Perspective
Dec 12, 2024



The use of copyrighted materials in training generative language models raises critical legal and ethical questions. This paper presents a framework for and the results of empirically assessing the impact of copyrighted materials on the performance of large language models (LLMs) for Norwegian. We found that both books and newspapers contribute positively when the models are evaluated on a diverse set of Norwegian benchmarks, while fiction works possibly lead to decreased performance. Our experiments could inform the creation of a compensation scheme for authors whose works contribute to AI development.
A New Massive Multilingual Dataset for High-Performance Language Technologies
Mar 20, 2024We present the HPLT (High Performance Language Technologies) language resources, a new massive multilingual dataset including both monolingual and bilingual corpora extracted from CommonCrawl and previously unused web crawls from the Internet Archive. We describe our methods for data acquisition, management and processing of large corpora, which rely on open-source software tools and high-performance computing. Our monolingual collection focuses on low- to medium-resourced languages and covers 75 languages and a total of ~5.6 trillion word tokens de-duplicated on the document level. Our English-centric parallel corpus is derived from its monolingual counterpart and covers 18 language pairs and more than 96 million aligned sentence pairs with roughly 1.4 billion English tokens. The HPLT language resources are one of the largest open text corpora ever released, providing a great resource for language modeling and machine translation training. We publicly release the corpora, the software, and the tools used in this work.
Direct parsing to sentiment graphs
Mar 24, 2022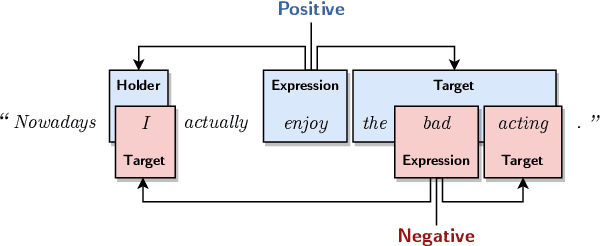
This paper demonstrates how a graph-based semantic parser can be applied to the task of structured sentiment analysis, directly predicting sentiment graphs from text. We advance the state of the art on 4 out of 5 standard benchmark sets. We release the source code, models and predictions.
Structured Sentiment Analysis as Dependency Graph Parsing
May 30, 2021
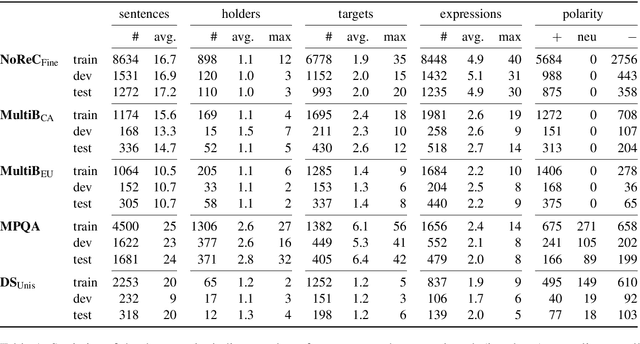
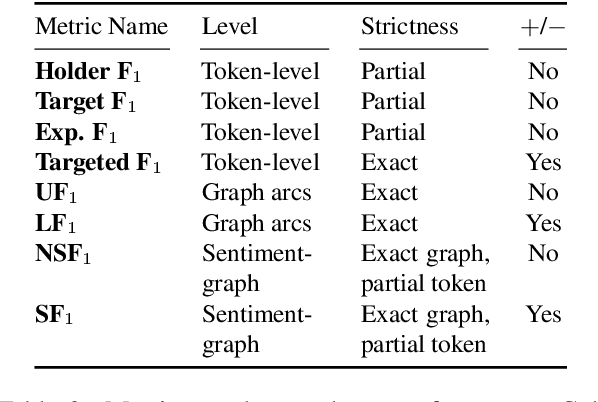
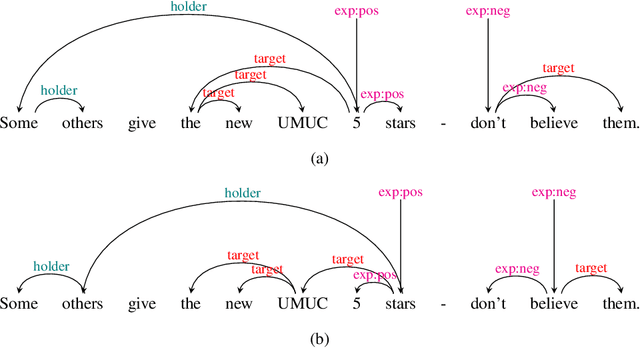
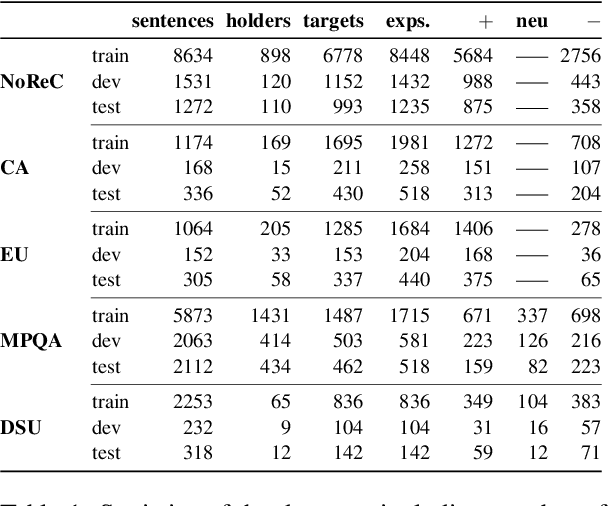
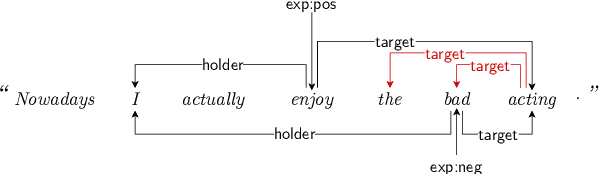
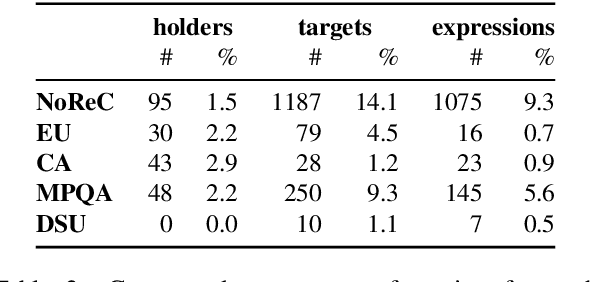
Structured sentiment analysis attempts to extract full opinion tuples from a text, but over time this task has been subdivided into smaller and smaller sub-tasks, e,g,, target extraction or targeted polarity classification. We argue that this division has become counterproductive and propose a new unified framework to remedy the situation. We cast the structured sentiment problem as dependency graph parsing, where the nodes are spans of sentiment holders, targets and expressions, and the arcs are the relations between them. We perform experiments on five datasets in four languages (English, Norwegian, Basque, and Catalan) and show that this approach leads to strong improvements over state-of-the-art baselines. Our analysis shows that refining the sentiment graphs with syntactic dependency information further improves results.
Large-Scale Contextualised Language Modelling for Norwegian
Apr 13, 2021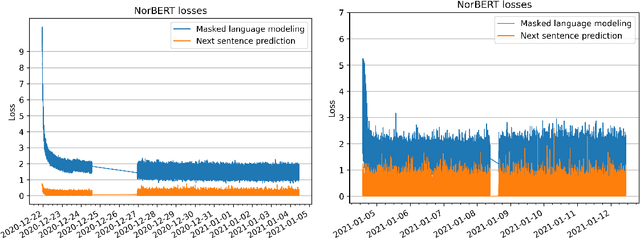
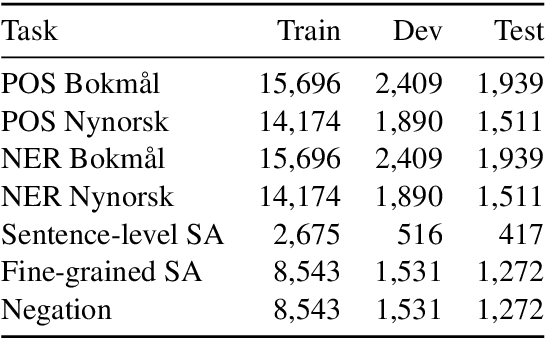
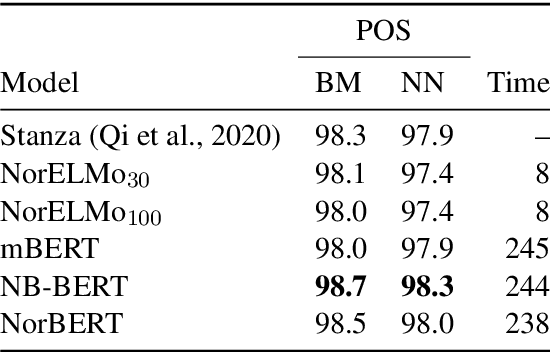
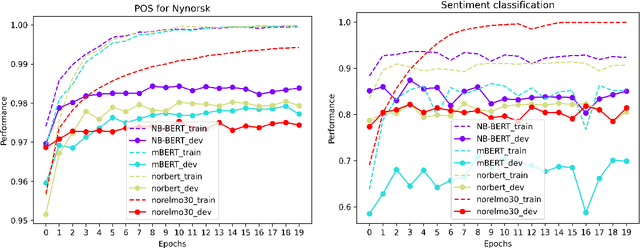
We present the ongoing NorLM initiative to support the creation and use of very large contextualised language models for Norwegian (and in principle other Nordic languages), including a ready-to-use software environment, as well as an experience report for data preparation and training. This paper introduces the first large-scale monolingual language models for Norwegian, based on both the ELMo and BERT frameworks. In addition to detailing the training process, we present contrastive benchmark results on a suite of NLP tasks for Norwegian. For additional background and access to the data, models, and software, please see http://norlm.nlpl.eu
DRS at MRP 2020: Dressing up Discourse Representation Structures as Graphs
Dec 29, 2020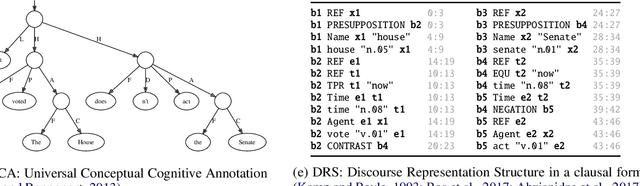
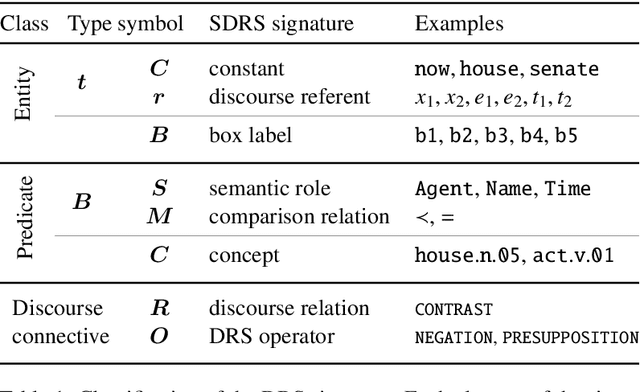
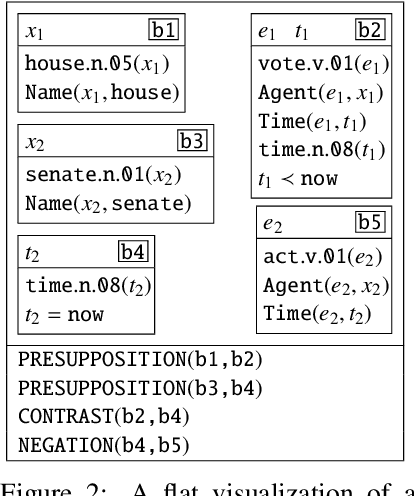
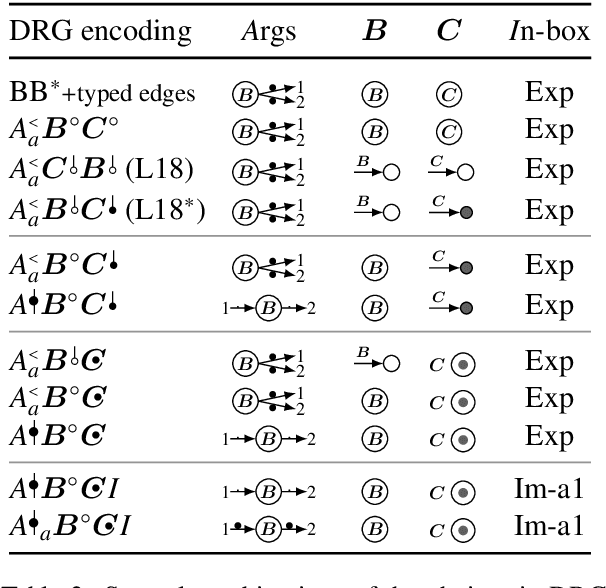
Discourse Representation Theory (DRT) is a formal account for representing the meaning of natural language discourse. Meaning in DRT is modeled via a Discourse Representation Structure (DRS), a meaning representation with a model-theoretic interpretation, which is usually depicted as nested boxes. In contrast, a directed labeled graph is a common data structure used to encode semantics of natural language texts. The paper describes the procedure of dressing up DRSs as directed labeled graphs to include DRT as a new framework in the 2020 shared task on Cross-Framework and Cross-Lingual Meaning Representation Parsing. Since one of the goals of the shared task is to encourage unified models for several semantic graph frameworks, the conversion procedure was biased towards making the DRT graph framework somewhat similar to other graph-based meaning representation frameworks.
Transfer and Multi-Task Learning for Noun-Noun Compound Interpretation
Sep 18, 2018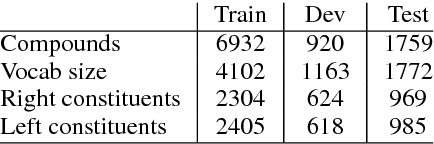
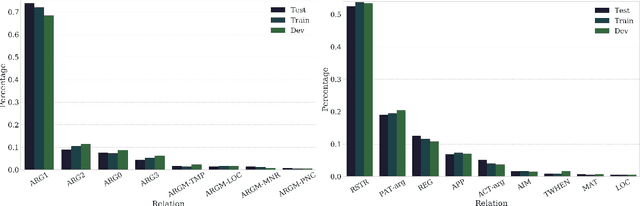
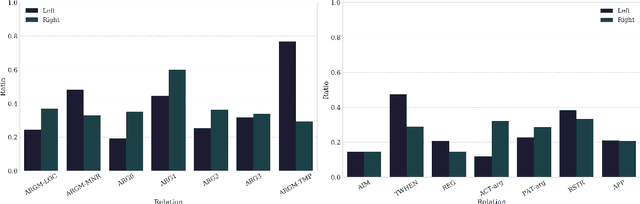
In this paper, we empirically evaluate the utility of transfer and multi-task learning on a challenging semantic classification task: semantic interpretation of noun--noun compounds. Through a comprehensive series of experiments and in-depth error analysis, we show that transfer learning via parameter initialization and multi-task learning via parameter sharing can help a neural classification model generalize over a highly skewed distribution of relations. Further, we demonstrate how dual annotation with two distinct sets of relations over the same set of compounds can be exploited to improve the overall accuracy of a neural classifier and its F1 scores on the less frequent, but more difficult relations.
TSNLP - Test Suites for Natural Language Processing
Jul 15, 1996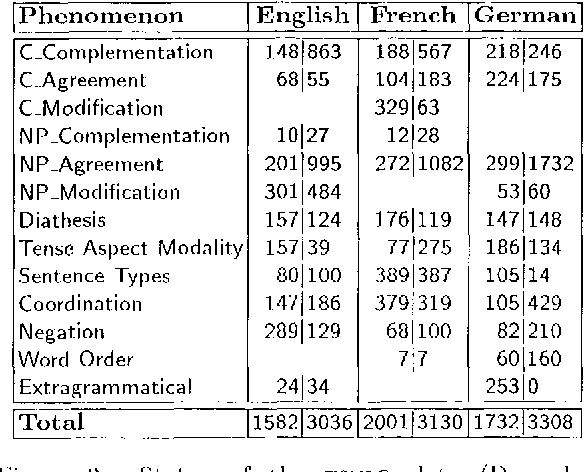
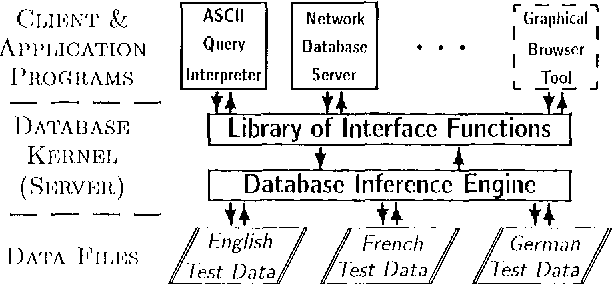
The TSNLP project has investigated various aspects of the construction, maintenance and application of systematic test suites as diagnostic and evaluation tools for NLP applications. The paper summarizes the motivation and main results of the project: besides the solid methodological foundation, TSNLP has produced substantial multi-purpose and multi-user test suites for three European languages together with a set of specialized tools that facilitate the construction, extension, maintenance, retrieval, and customization of the test data. As TSNLP results, including the data and technology, are made publicly available, the project presents a valuable linguistic resourc e that has the potential of providing a wide-spread pre-standard diagnostic and evaluation tool for both developers and users of NLP applications.