 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInvestigating the Encoding of Words in BERT's Neurons using Feature Textualization
Nov 14, 2023



Pretrained language models (PLMs) form the basis of most state-of-the-art NLP technologies. Nevertheless, they are essentially black boxes: Humans do not have a clear understanding of what knowledge is encoded in different parts of the models, especially in individual neurons. The situation is different in computer vision, where feature visualization provides a decompositional interpretability technique for neurons of vision models. Activation maximization is used to synthesize inherently interpretable visual representations of the information encoded in individual neurons. Our work is inspired by this but presents a cautionary tale on the interpretability of single neurons, based on the first large-scale attempt to adapt activation maximization to NLP, and, more specifically, large PLMs. We propose feature textualization, a technique to produce dense representations of neurons in the PLM word embedding space. We apply feature textualization to the BERT model (Devlin et al., 2019) to investigate whether the knowledge encoded in individual neurons can be interpreted and symbolized. We find that the produced representations can provide insights about the knowledge encoded in individual neurons, but that individual neurons do not represent clearcut symbolic units of language such as words. Additionally, we use feature textualization to investigate how many neurons are needed to encode words in BERT.
Linguistically inspired morphological inflection with a sequence to sequence model
Sep 04, 2020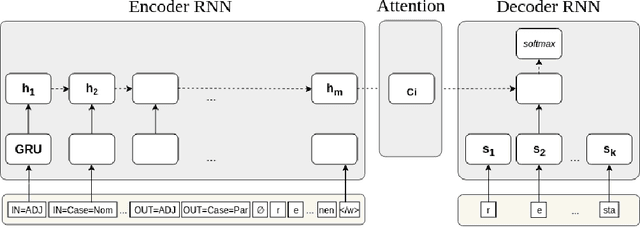

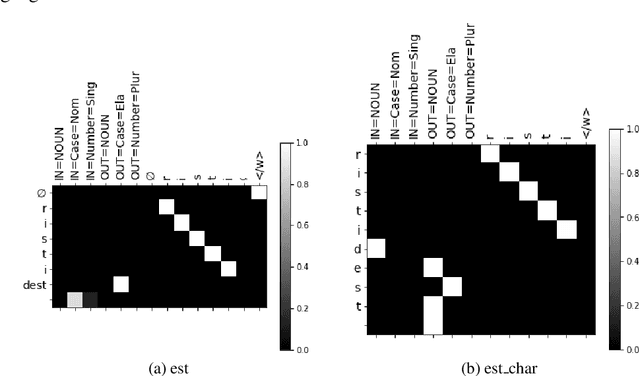
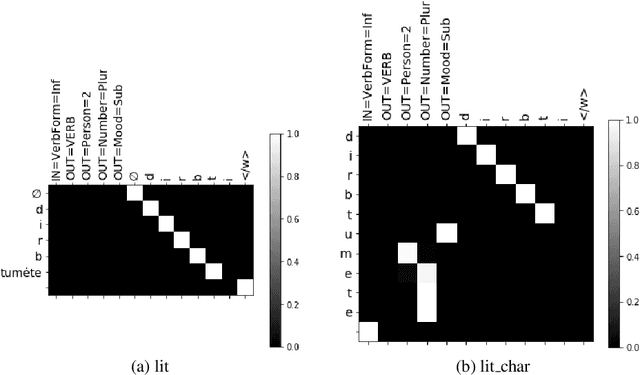
Inflection is an essential part of every human language's morphology, yet little effort has been made to unify linguistic theory and computational methods in recent years. Methods of string manipulation are used to infer inflectional changes; our research question is whether a neural network would be capable of learning inflectional morphemes for inflection production in a similar way to a human in early stages of language acquisition. We are using an inflectional corpus (Metheniti and Neumann, 2020) and a single layer seq2seq model to test this hypothesis, in which the inflectional affixes are learned and predicted as a block and the word stem is modelled as a character sequence to account for infixation. Our character-morpheme-based model creates inflection by predicting the stem character-to-character and the inflectional affixes as character blocks. We conducted three experiments on creating an inflected form of a word given the lemma and a set of input and target features, comparing our architecture to a mainstream character-based model with the same hyperparameters, training and test sets. Overall for 17 languages, we noticed small improvements on inflecting known lemmas (+0.68%) but steadily better performance of our model in predicting inflected forms of unknown words (+3.7%) and small improvements on predicting in a low-resource scenario (+1.09%)
Neural Morphological Tagging from Characters for Morphologically Rich Languages
Jun 21, 2016
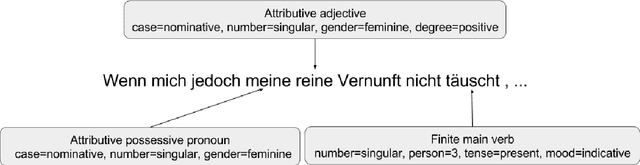

This paper investigates neural character-based morphological tagging for languages with complex morphology and large tag sets. We systematically explore a variety of neural architectures (DNN, CNN, CNNHighway, LSTM, BLSTM) to obtain character-based word vectors combined with bidirectional LSTMs to model across-word context in an end-to-end setting. We explore supplementary use of word-based vectors trained on large amounts of unlabeled data. Our experiments for morphological tagging suggest that for "simple" model configurations, the choice of the network architecture (CNN vs. CNNHighway vs. LSTM vs. BLSTM) or the augmentation with pre-trained word embeddings can be important and clearly impact the accuracy. Increasing the model capacity by adding depth, for example, and carefully optimizing the neural networks can lead to substantial improvements, and the differences in accuracy (but not training time) become much smaller or even negligible. Overall, our best morphological taggers for German and Czech outperform the best results reported in the literature by a large margin.
Applying Explanation-based Learning to Control and Speeding-up Natural Language Generation
Dec 08, 1997
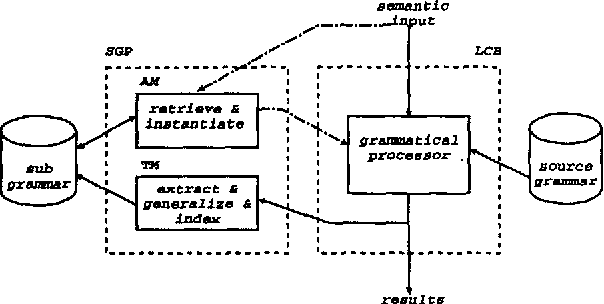
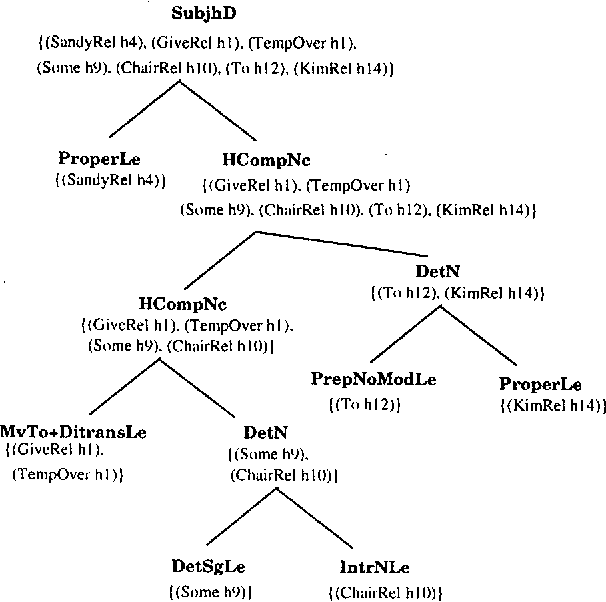
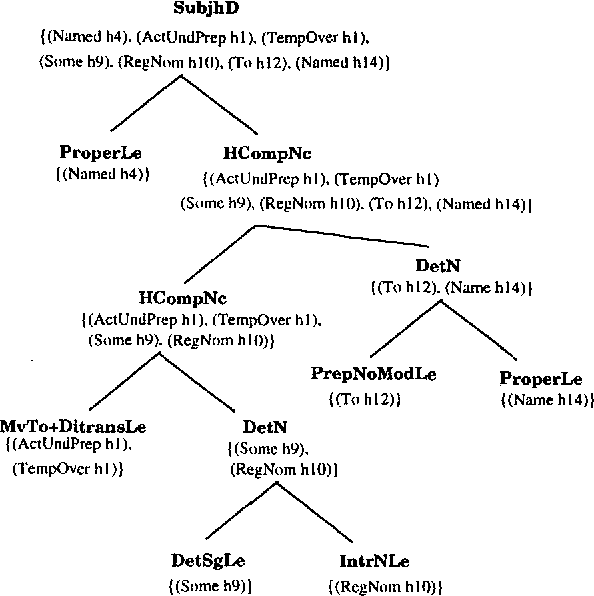
This paper presents a method for the automatic extraction of subgrammars to control and speeding-up natural language generation NLG. The method is based on explanation-based learning (EBL). The main advantage for the proposed new method for NLG is that the complexity of the grammatical decision making process during NLG can be vastly reduced, because the EBL method supports the adaption of a NLG system to a particular use of a language.
DISCO---An HPSG-based NLP System and its Application for Appointment Scheduling
Jun 30, 1994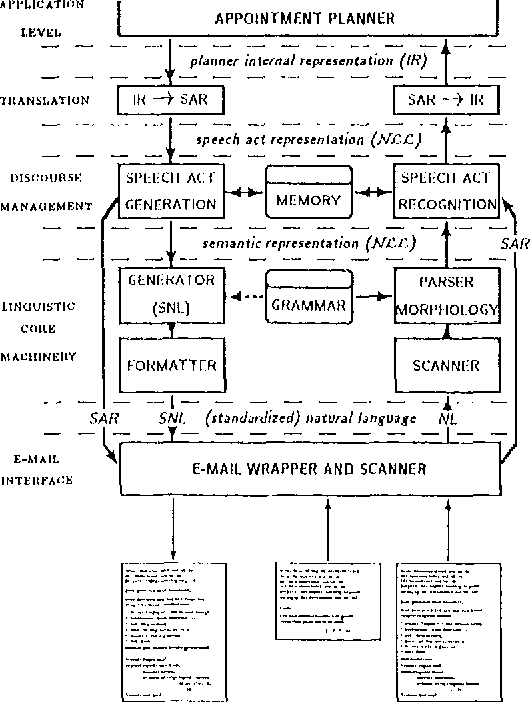
The natural language system DISCO is described. It combines o a powerful and flexible grammar development system; o linguistic competence for German including morphology, syntax and semantics; o new methods for linguistic performance modelling on the basis of high-level competence grammars; o new methods for modelling multi-agent dialogue competence; o an interesting sample application for appointment scheduling and calendar management.