 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCLaS-Bench: A Cross-Lingual Alignment and Steering Benchmark
Jan 13, 2026Understanding and controlling the behavior of large language models (LLMs) is an increasingly important topic in multilingual NLP. Beyond prompting or fine-tuning, , i.e.,~manipulating internal representations during inference, has emerged as a more efficient and interpretable technique for adapting models to a target language. Yet, no dedicated benchmarks or evaluation protocols exist to quantify the effectiveness of steering techniques. We introduce CLaS-Bench, a lightweight parallel-question benchmark for evaluating language-forcing behavior in LLMs across 32 languages, enabling systematic evaluation of multilingual steering methods. We evaluate a broad array of steering techniques, including residual-stream DiffMean interventions, probe-derived directions, language-specific neurons, PCA/LDA vectors, Sparse Autoencoders, and prompting baselines. Steering performance is measured along two axes: language control and semantic relevance, combined into a single harmonic-mean steering score. We find that across languages simple residual-based DiffMean method consistently outperforms all other methods. Moreover, a layer-wise analysis reveals that language-specific structure emerges predominantly in later layers and steering directions cluster based on language family. CLaS-Bench is the first standardized benchmark for multilingual steering, enabling both rigorous scientific analysis of language representations and practical evaluation of steering as a low-cost adaptation alternative.
Language Arithmetics: Towards Systematic Language Neuron Identification and Manipulation
Jul 30, 2025Large language models (LLMs) exhibit strong multilingual abilities, yet the neural mechanisms behind language-specific processing remain unclear. We analyze language-specific neurons in Llama-3.1-8B, Mistral-Nemo-12B, and Aya-Expanse-8B & 32B across 21 typologically diverse languages, identifying neurons that control language behavior. Using the Language Activation Probability Entropy (LAPE) method, we show that these neurons cluster in deeper layers, with non-Latin scripts showing greater specialization. Related languages share overlapping neurons, reflecting internal representations of linguistic proximity. Through language arithmetics, i.e. systematic activation addition and multiplication, we steer models to deactivate unwanted languages and activate desired ones, outperforming simpler replacement approaches. These interventions effectively guide behavior across five multilingual tasks: language forcing, translation, QA, comprehension, and NLI. Manipulation is more successful for high-resource languages, while typological similarity improves effectiveness. We also demonstrate that cross-lingual neuron steering enhances downstream performance and reveal internal "fallback" mechanisms for language selection when neurons are progressively deactivated. Our code is made publicly available at https://github.com/d-gurgurov/Language-Neurons-Manipulation.
What Language(s) Does Aya-23 Think In? How Multilinguality Affects Internal Language Representations
Jul 27, 2025Large language models (LLMs) excel at multilingual tasks, yet their internal language processing remains poorly understood. We analyze how Aya-23-8B, a decoder-only LLM trained on balanced multilingual data, handles code-mixed, cloze, and translation tasks compared to predominantly monolingual models like Llama 3 and Chinese-LLaMA-2. Using logit lens and neuron specialization analyses, we find: (1) Aya-23 activates typologically related language representations during translation, unlike English-centric models that rely on a single pivot language; (2) code-mixed neuron activation patterns vary with mixing rates and are shaped more by the base language than the mixed-in one; and (3) Aya-23's languagespecific neurons for code-mixed inputs concentrate in final layers, diverging from prior findings on decoder-only models. Neuron overlap analysis further shows that script similarity and typological relations impact processing across model types. These findings reveal how multilingual training shapes LLM internals and inform future cross-lingual transfer research.
The Lookahead Limitation: Why Multi-Operand Addition is Hard for LLMs
Feb 27, 2025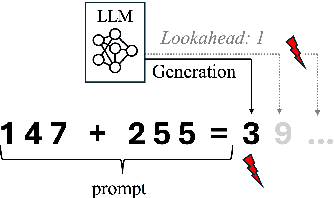
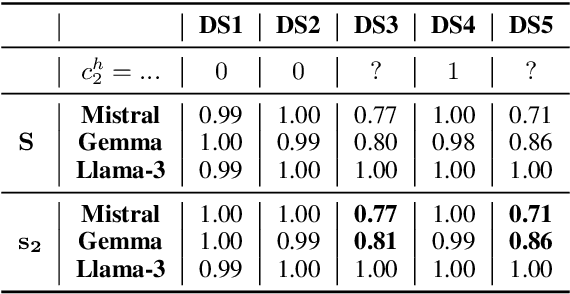
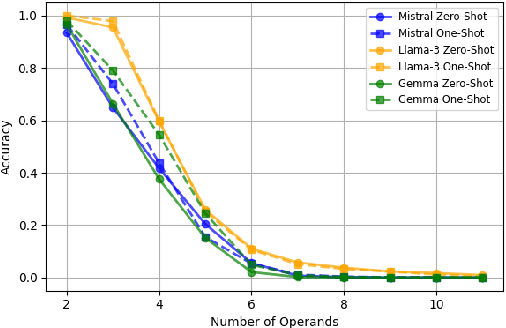
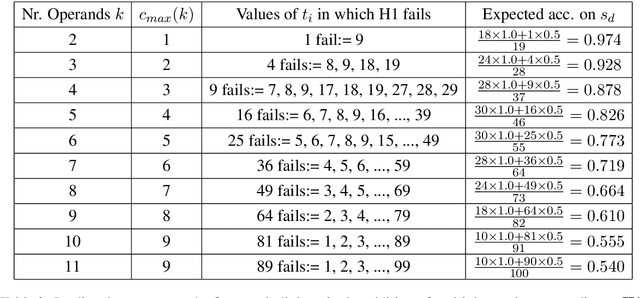
Autoregressive large language models (LLMs) exhibit impressive performance across various tasks but struggle with simple arithmetic, such as addition of two or more operands. We show that this struggle arises from LLMs' use of a simple one-digit lookahead heuristic, which works fairly well (but not perfect) for two-operand addition but fails in multi-operand cases, where the carry-over logic is more complex. Our probing experiments and digit-wise accuracy evaluation show that LLMs fail precisely where a one-digit lookahead is insufficient to account for cascading carries. We analyze the impact of tokenization strategies on arithmetic performance and show that all investigated models, regardless of tokenization, are inherently limited in the addition of multiple operands due to their reliance on a one-digit lookahead heuristic. Our findings reveal fundamental limitations that prevent LLMs from generalizing to more complex numerical reasoning.
Investigating the Encoding of Words in BERT's Neurons using Feature Textualization
Nov 14, 2023



Pretrained language models (PLMs) form the basis of most state-of-the-art NLP technologies. Nevertheless, they are essentially black boxes: Humans do not have a clear understanding of what knowledge is encoded in different parts of the models, especially in individual neurons. The situation is different in computer vision, where feature visualization provides a decompositional interpretability technique for neurons of vision models. Activation maximization is used to synthesize inherently interpretable visual representations of the information encoded in individual neurons. Our work is inspired by this but presents a cautionary tale on the interpretability of single neurons, based on the first large-scale attempt to adapt activation maximization to NLP, and, more specifically, large PLMs. We propose feature textualization, a technique to produce dense representations of neurons in the PLM word embedding space. We apply feature textualization to the BERT model (Devlin et al., 2019) to investigate whether the knowledge encoded in individual neurons can be interpreted and symbolized. We find that the produced representations can provide insights about the knowledge encoded in individual neurons, but that individual neurons do not represent clearcut symbolic units of language such as words. Additionally, we use feature textualization to investigate how many neurons are needed to encode words in BERT.