 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeural Morphological Tagging from Characters for Morphologically Rich Languages
Paper and Code
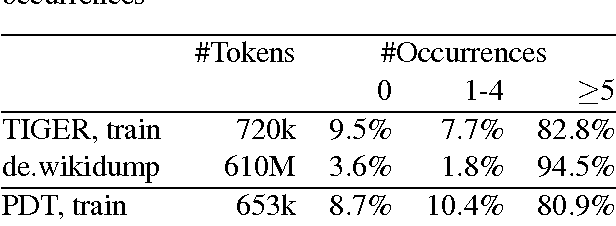
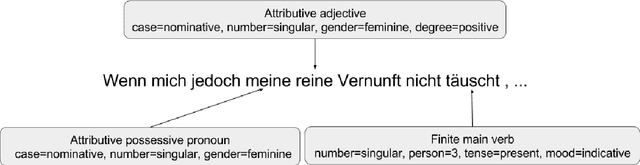

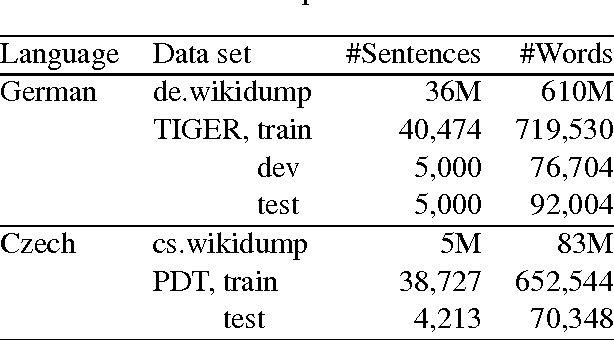
This paper investigates neural character-based morphological tagging for languages with complex morphology and large tag sets. We systematically explore a variety of neural architectures (DNN, CNN, CNNHighway, LSTM, BLSTM) to obtain character-based word vectors combined with bidirectional LSTMs to model across-word context in an end-to-end setting. We explore supplementary use of word-based vectors trained on large amounts of unlabeled data. Our experiments for morphological tagging suggest that for "simple" model configurations, the choice of the network architecture (CNN vs. CNNHighway vs. LSTM vs. BLSTM) or the augmentation with pre-trained word embeddings can be important and clearly impact the accuracy. Increasing the model capacity by adding depth, for example, and carefully optimizing the neural networks can lead to substantial improvements, and the differences in accuracy (but not training time) become much smaller or even negligible. Overall, our best morphological taggers for German and Czech outperform the best results reported in the literature by a large margin.