 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOrder in the Evaluation Court: A Critical Analysis of NLG Evaluation Trends
Jan 12, 2026Despite advances in Natural Language Generation (NLG), evaluation remains challenging. Although various new metrics and LLM-as-a-judge (LaaJ) methods are proposed, human judgment persists as the gold standard. To systematically review how NLG evaluation has evolved, we employ an automatic information extraction scheme to gather key information from NLG papers, focusing on different evaluation methods (metrics, LaaJ and human evaluation). With extracted metadata from 14,171 papers across four major conferences (ACL, EMNLP, NAACL, and INLG) over the past six years, we reveal several critical findings: (1) Task Divergence: While Dialogue Generation demonstrates a rapid shift toward LaaJ (>40% in 2025), Machine Translation remains locked into n-gram metrics, and Question Answering exhibits a substantial decline in the proportion of studies conducting human evaluation. (2) Metric Inertia: Despite the development of semantic metrics, general-purpose metrics (e.g., BLEU, ROUGE) continue to be widely used across tasks without empirical justification, often lacking the discriminative power to distinguish between specific quality criteria. (3) Human-LaaJ Divergence: Our association analysis challenges the assumption that LLMs act as mere proxies for humans; LaaJ and human evaluations prioritize very different signals, and explicit validation is scarce (<8% of papers comparing the two), with only moderate to low correlation. Based on these observations, we derive practical recommendations to improve the rigor of future NLG evaluation.
Linguistically inspired morphological inflection with a sequence to sequence model
Sep 04, 2020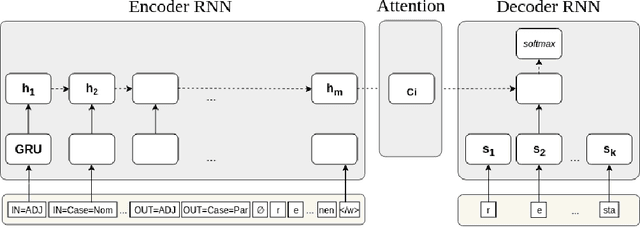

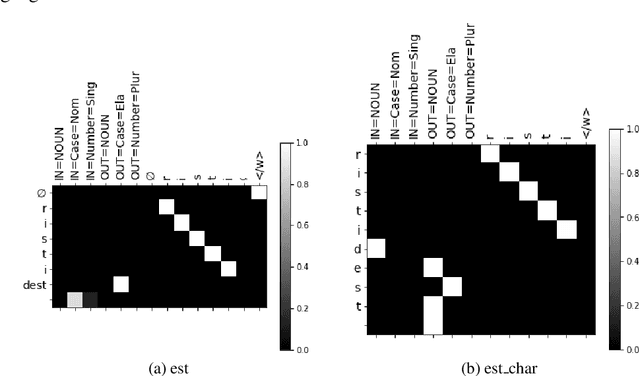
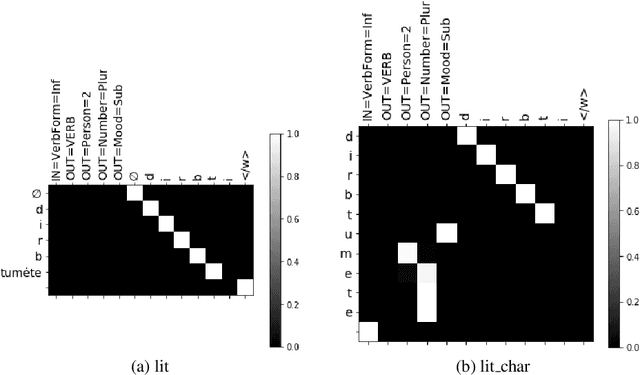
Inflection is an essential part of every human language's morphology, yet little effort has been made to unify linguistic theory and computational methods in recent years. Methods of string manipulation are used to infer inflectional changes; our research question is whether a neural network would be capable of learning inflectional morphemes for inflection production in a similar way to a human in early stages of language acquisition. We are using an inflectional corpus (Metheniti and Neumann, 2020) and a single layer seq2seq model to test this hypothesis, in which the inflectional affixes are learned and predicted as a block and the word stem is modelled as a character sequence to account for infixation. Our character-morpheme-based model creates inflection by predicting the stem character-to-character and the inflectional affixes as character blocks. We conducted three experiments on creating an inflected form of a word given the lemma and a set of input and target features, comparing our architecture to a mainstream character-based model with the same hyperparameters, training and test sets. Overall for 17 languages, we noticed small improvements on inflecting known lemmas (+0.68%) but steadily better performance of our model in predicting inflected forms of unknown words (+3.7%) and small improvements on predicting in a low-resource scenario (+1.09%)