 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOverview of MWE history, challenges, and horizons: standing at the 20th anniversary of the MWE workshop series via MWE-UD2024
Dec 25, 2024Starting in 2003 when the first MWE workshop was held with ACL in Sapporo, Japan, this year, the joint workshop of MWE-UD co-located with the LREC-COLING 2024 conference marked the 20th anniversary of MWE workshop events over the past nearly two decades. Standing at this milestone, we look back to this workshop series and summarise the research topics and methodologies researchers have carried out over the years. We also discuss the current challenges that we are facing and the broader impacts/synergies of MWE research within the CL and NLP fields. Finally, we give future research perspectives. We hope this position paper can help researchers, students, and industrial practitioners interested in MWE get a brief but easy understanding of its history, current, and possible future.
Neural Semantic Parsing with Extremely Rich Symbolic Meaning Representations
Apr 19, 2024
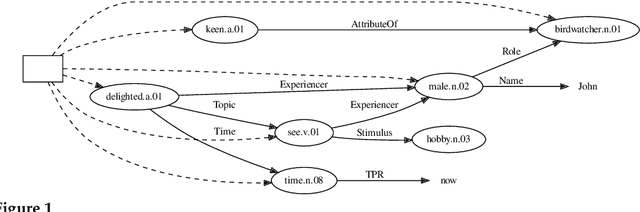


Current open-domain neural semantics parsers show impressive performance. However, closer inspection of the symbolic meaning representations they produce reveals significant weaknesses: sometimes they tend to merely copy character sequences from the source text to form symbolic concepts, defaulting to the most frequent word sense based in the training distribution. By leveraging the hierarchical structure of a lexical ontology, we introduce a novel compositional symbolic representation for concepts based on their position in the taxonomical hierarchy. This representation provides richer semantic information and enhances interpretability. We introduce a neural "taxonomical" semantic parser to utilize this new representation system of predicates, and compare it with a standard neural semantic parser trained on the traditional meaning representation format, employing a novel challenge set and evaluation metric for evaluation. Our experimental findings demonstrate that the taxonomical model, trained on much richer and complex meaning representations, is slightly subordinate in performance to the traditional model using the standard metrics for evaluation, but outperforms it when dealing with out-of-vocabulary concepts. This finding is encouraging for research in computational semantics that aims to combine data-driven distributional meanings with knowledge-based symbolic representations.
Hyper-X: A Unified Hypernetwork for Multi-Task Multilingual Transfer
May 24, 2022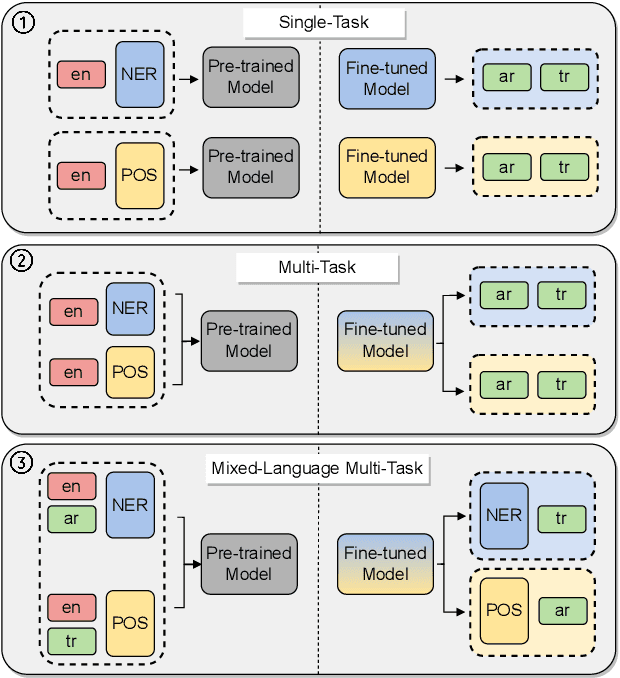

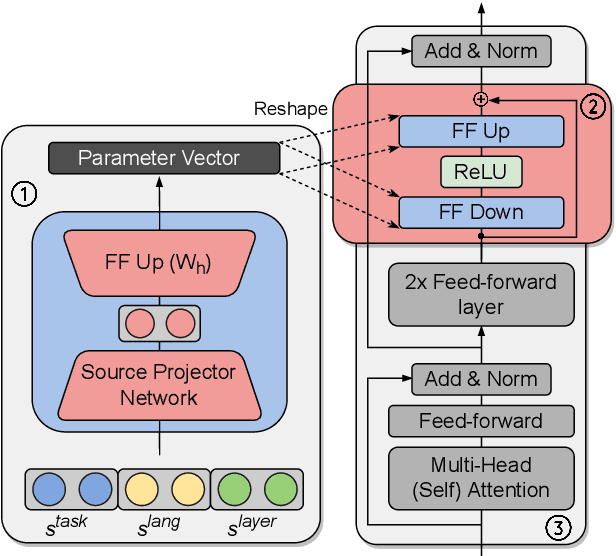
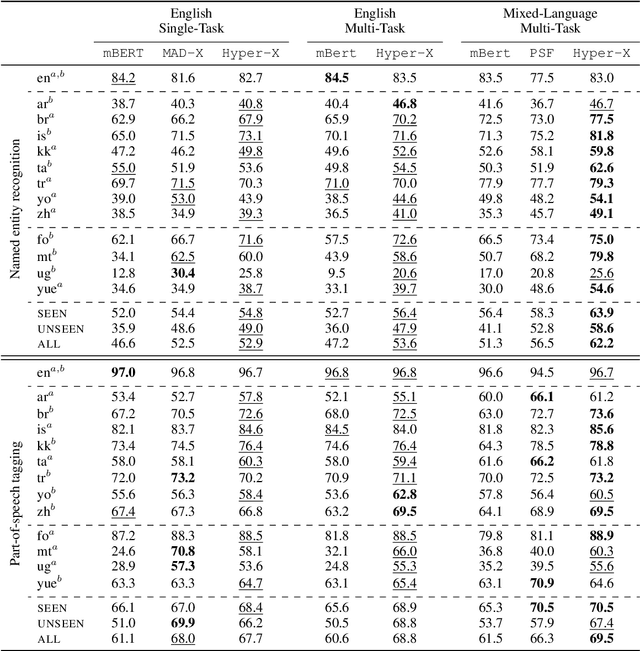
Massively multilingual models are promising for transfer learning across tasks and languages. However, existing methods are unable to fully leverage training data when it is available in different task-language combinations. To exploit such heterogeneous supervision we propose Hyper-X, a unified hypernetwork that generates weights for parameter-efficient adapter modules conditioned on both tasks and language embeddings. By learning to combine task and language-specific knowledge our model enables zero-shot transfer for unseen languages and task-language combinations. Our experiments on a diverse set of languages demonstrate that Hyper-X achieves the best gain when a mixture of multiple resources is available while performing on par with strong baselines in the standard scenario. Finally, Hyper-X consistently produces strong results in few-shot scenarios for new languages and tasks showing the effectiveness of our approach beyond zero-shot transfer.
POS tagging, lemmatization and dependency parsing of West Frisian
Jul 28, 2021



We present a lemmatizer/POS-tagger/dependency parser for West Frisian using a corpus of 44,714 words in 3,126 sentences that were annotated according to the guidelines of Universal Dependency version 2. POS tags were assigned to words by using a Dutch POS tagger that was applied to a literal word-by-word translation, or to sentences of a Dutch parallel text. Best results were obtained when using literal translations that were created by using the Frisian translation program Oersetter. Morphologic and syntactic annotations were generated on the basis of a literal Dutch translation as well. The performance of the lemmatizer/tagger/annotator when it was trained using default parameters was compared to the performance that was obtained when using the parameter values that were used for training the LassySmall UD 2.5 corpus. A significant improvement was found for `lemma'. The Frisian lemmatizer/PoS tagger/dependency parser is released as a web app and as a web service.
UDapter: Language Adaptation for Truly Universal Dependency Parsing
Apr 29, 2020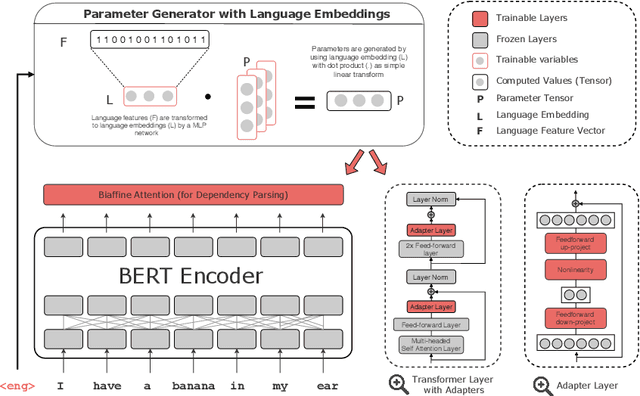
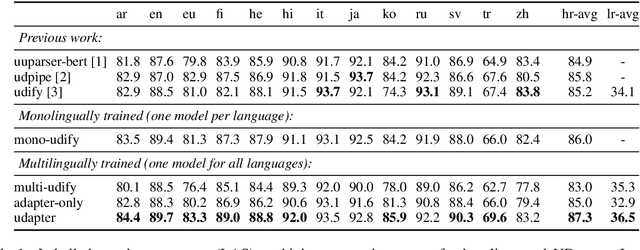
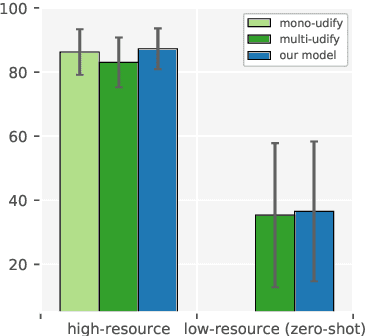

Recent advances in the field of multilingual dependency parsing have brought the idea of a truly universal parser closer to reality. However, cross-language interference and restrained model capacity remain a major obstacle to this pursuit. To address these issues, we propose a novel multilingual task adaptation approach based on recent work in parameter-efficient transfer learning, which allows for an easy but effective integration of existing linguistic typology features into the parsing network. The resulting parser, UDapter, consistently outperforms strong monolingual and multilingual baselines on both high-resource and low-resource (zero-shot) languages, setting a new state of the art in multilingual UD parsing. Our in-depth analyses show that soft parameter sharing via typological features is key to this success.
A Finite State and Data-Oriented Method for Grapheme to Phoneme Conversion
Mar 23, 2000

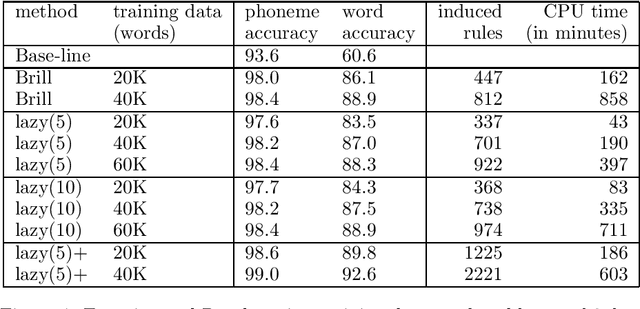
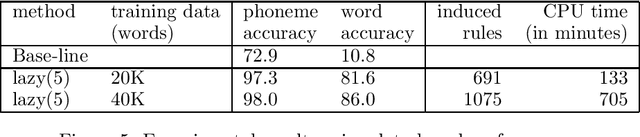
A finite-state method, based on leftmost longest-match replacement, is presented for segmenting words into graphemes, and for converting graphemes into phonemes. A small set of hand-crafted conversion rules for Dutch achieves a phoneme accuracy of over 93%. The accuracy of the system is further improved by using transformation-based learning. The phoneme accuracy of the best system (using a large set of rule templates and a `lazy' variant of Brill's algoritm), trained on only 40K words, reaches 99% accuracy.
* 8 pages
Robust Grammatical Analysis for Spoken Dialogue Systems
Jun 25, 1999
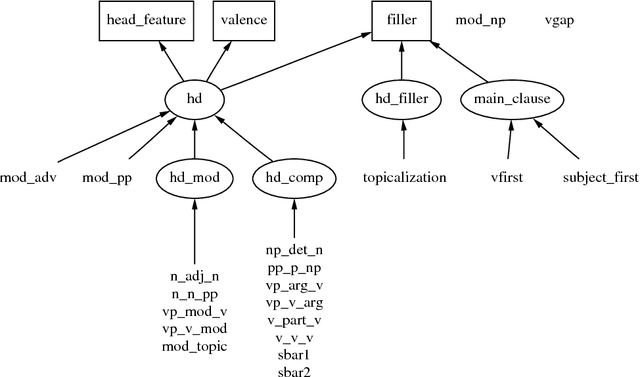
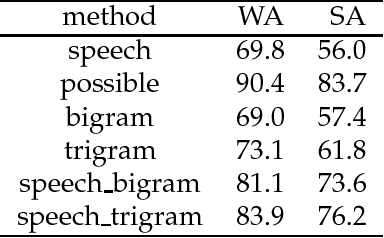
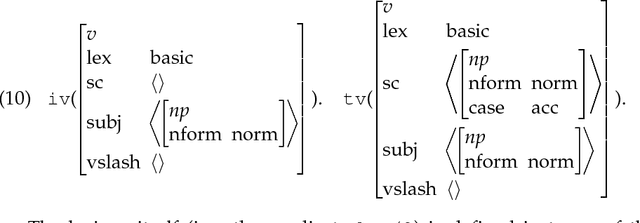
We argue that grammatical analysis is a viable alternative to concept spotting for processing spoken input in a practical spoken dialogue system. We discuss the structure of the grammar, and a model for robust parsing which combines linguistic sources of information and statistical sources of information. We discuss test results suggesting that grammatical processing allows fast and accurate processing of spoken input.
Evaluation of the NLP Components of the OVIS2 Spoken Dialogue System
Jun 14, 1999
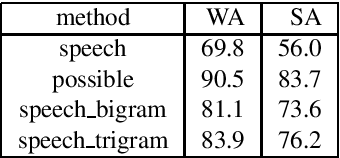
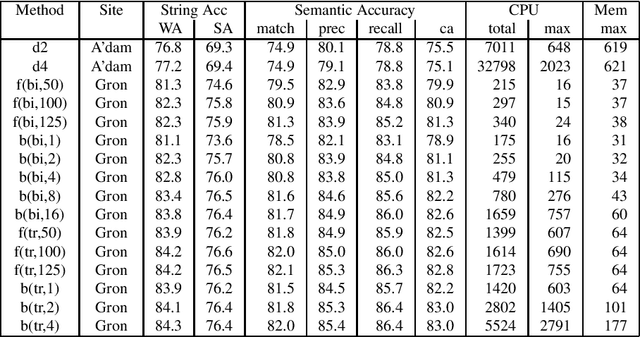
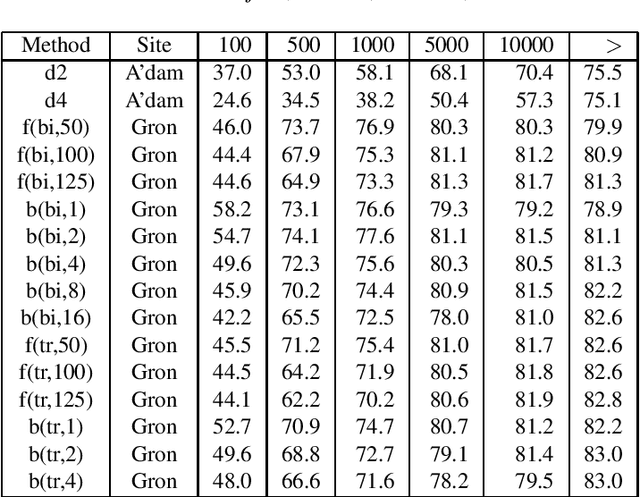
The NWO Priority Programme Language and Speech Technology is a 5-year research programme aiming at the development of spoken language information systems. In the Programme, two alternative natural language processing (NLP) modules are developed in parallel: a grammar-based (conventional, rule-based) module and a data-oriented (memory-based, stochastic, DOP) module. In order to compare the NLP modules, a formal evaluation has been carried out three years after the start of the Programme. This paper describes the evaluation procedure and the evaluation results. The grammar-based component performs much better than the data-oriented one in this comparison.
Grammatical analysis in the OVIS spoken-dialogue system
May 01, 1997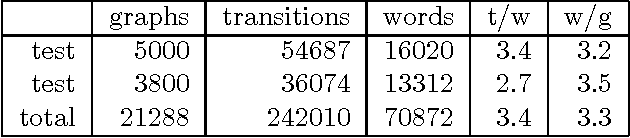
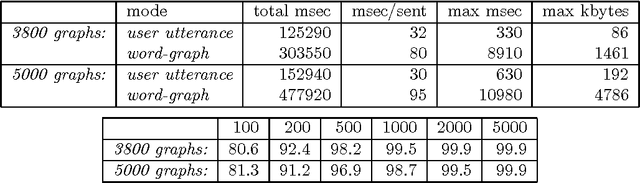
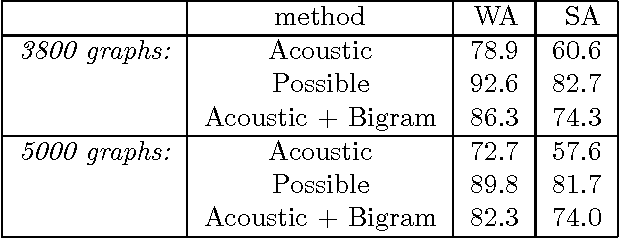
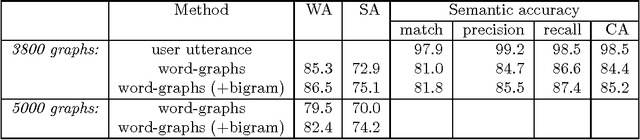
We argue that grammatical processing is a viable alternative to concept spotting for processing spoken input in a practical dialogue system. We discuss the structure of the grammar, the properties of the parser, and a method for achieving robustness. We discuss test results suggesting that grammatical processing allows fast and accurate processing of spoken input.
* 8 pages, uses aclap.sty
Adjuncts and the Processing of Lexical Rules
May 01, 1994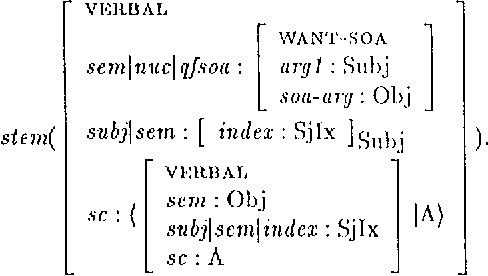
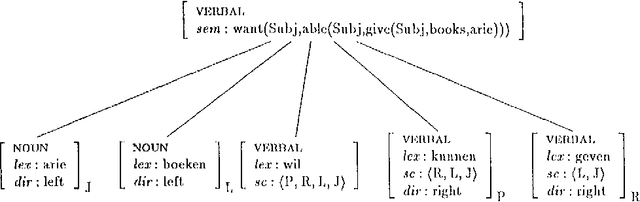
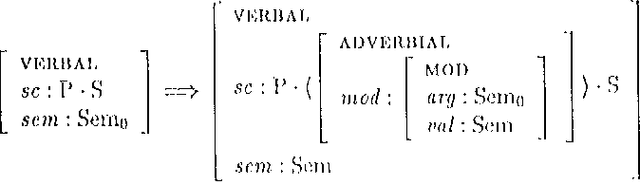

The standard HPSG analysis of Germanic verb clusters can not explain the observed narrow-scope readings of adjuncts in such verb clusters. We present an extension of the HPSG analysis that accounts for the systematic ambiguity of the scope of adjuncts in verb cluster constructions, by treating adjuncts as members of the subcat list. The extension uses powerful recursive lexical rules, implemented as complex constraints. We show how `delayed evaluation' techniques from constraint-logic programming can be used to process such lexical rules.
* 8 pages (a4wide), to be published in Coling-94