Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Finite State and Data-Oriented Method for Grapheme to Phoneme Conversion
Paper and Code
Mar 23, 2000

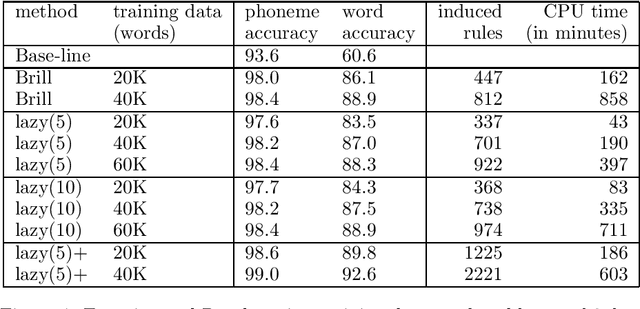
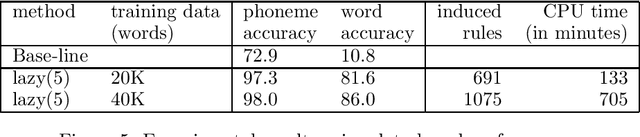
A finite-state method, based on leftmost longest-match replacement, is presented for segmenting words into graphemes, and for converting graphemes into phonemes. A small set of hand-crafted conversion rules for Dutch achieves a phoneme accuracy of over 93%. The accuracy of the system is further improved by using transformation-based learning. The phoneme accuracy of the best system (using a large set of rule templates and a `lazy' variant of Brill's algoritm), trained on only 40K words, reaches 99% accuracy.
* Proceedings of NAACL-2000, Seattle, WA * 8 pages
View paper on