 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluation of the NLP Components of the OVIS2 Spoken Dialogue System
Jun 14, 1999
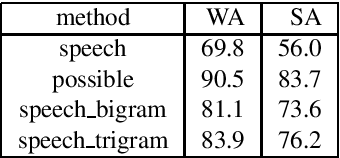
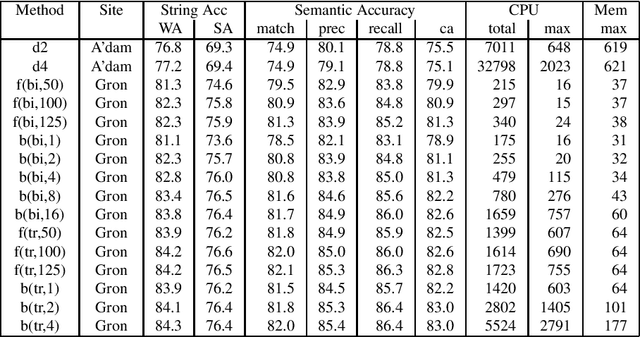
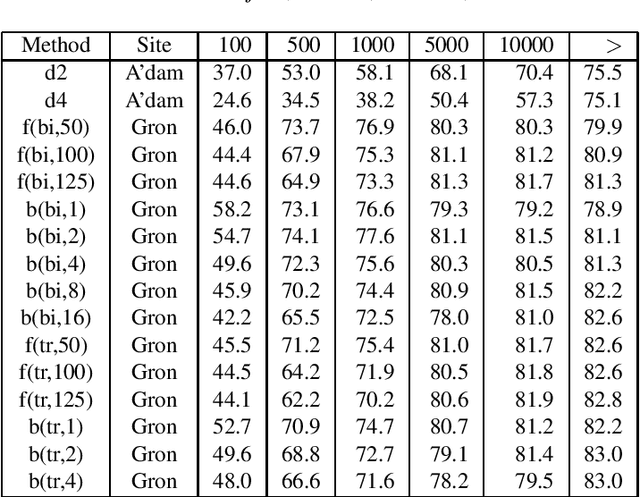
The NWO Priority Programme Language and Speech Technology is a 5-year research programme aiming at the development of spoken language information systems. In the Programme, two alternative natural language processing (NLP) modules are developed in parallel: a grammar-based (conventional, rule-based) module and a data-oriented (memory-based, stochastic, DOP) module. In order to compare the NLP modules, a formal evaluation has been carried out three years after the start of the Programme. This paper describes the evaluation procedure and the evaluation results. The grammar-based component performs much better than the data-oriented one in this comparison.
A Data-Oriented Approach to Semantic Interpretation
Jun 18, 1996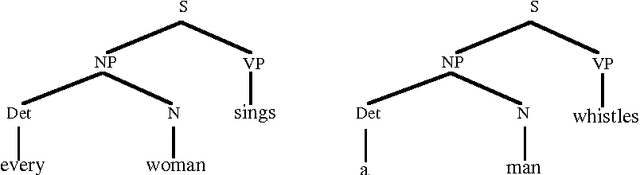
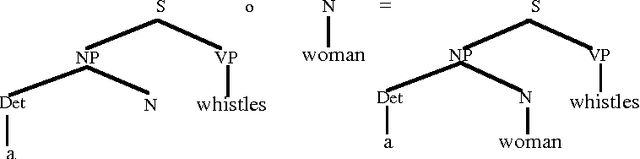
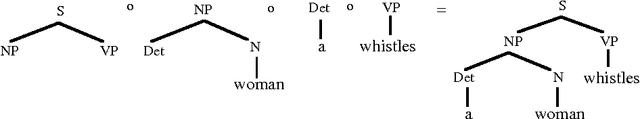
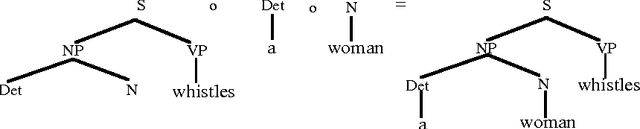
In Data-Oriented Parsing (DOP), an annotated language corpus is used as a stochastic grammar. The most probable analysis of a new input sentence is constructed by combining sub-analyses from the corpus in the most probable way. This approach has been succesfully used for syntactic analysis, using corpora with syntactic annotations such as the Penn Treebank. If a corpus with semantically annotated sentences is used, the same approach can also generate the most probable semantic interpretation of an input sentence. The present paper explains this semantic interpretation method, and summarizes the results of a preliminary experiment. Semantic annotations were added to the syntactic annotations of most of the sentences of the ATIS corpus. A data-oriented semantic interpretation algorithm was succesfully tested on this semantically enriched corpus.