 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Data-Oriented Model of Literary Language
Jan 26, 2017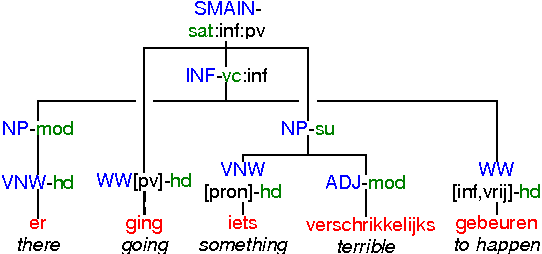


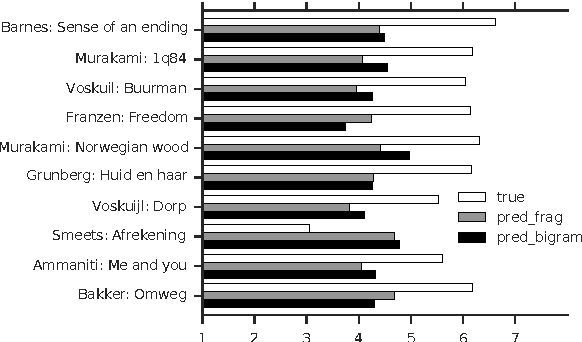
We consider the task of predicting how literary a text is, with a gold standard from human ratings. Aside from a standard bigram baseline, we apply rich syntactic tree fragments, mined from the training set, and a series of hand-picked features. Our model is the first to distinguish degrees of highly and less literary novels using a variety of lexical and syntactic features, and explains 76.0 % of the variation in literary ratings.
* To be published in EACL 2017, 11 pages
Combining semantic and syntactic structure for language modeling
Oct 24, 2001Structured language models for speech recognition have been shown to remedy the weaknesses of n-gram models. All current structured language models are, however, limited in that they do not take into account dependencies between non-headwords. We show that non-headword dependencies contribute to significantly improved word error rate, and that a data-oriented parsing model trained on semantically and syntactically annotated data can exploit these dependencies. This paper also contains the first DOP model trained by means of a maximum likelihood reestimation procedure, which solves some of the theoretical shortcomings of previous DOP models.
* 4 pages
What is the minimal set of fragments that achieves maximal parse accuracy?
Oct 24, 2001
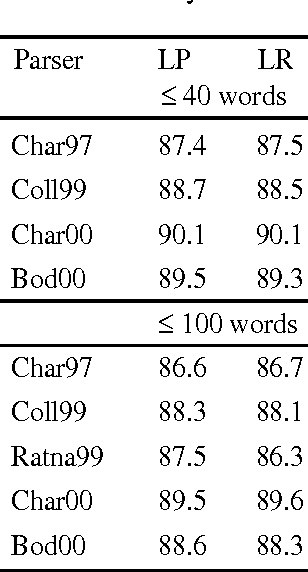
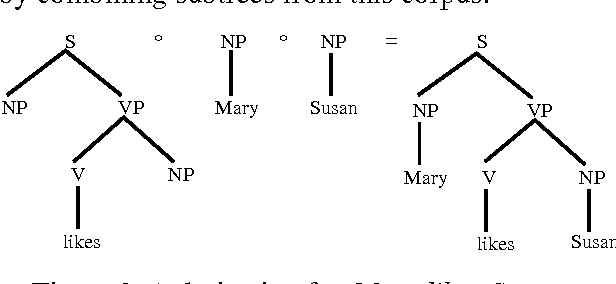

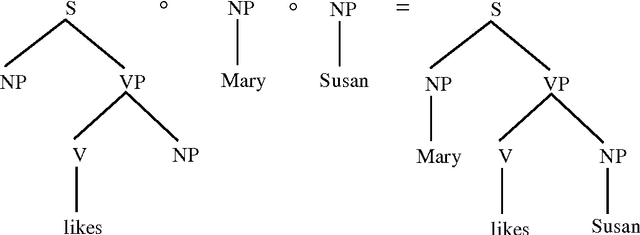
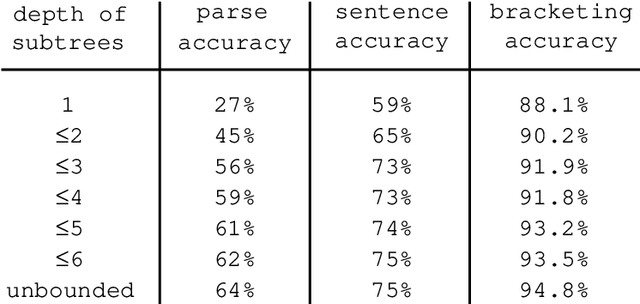
We aim at finding the minimal set of fragments which achieves maximal parse accuracy in Data Oriented Parsing. Experiments with the Penn Wall Street Journal treebank show that counts of almost arbitrary fragments within parse trees are important, leading to improved parse accuracy over previous models tested on this treebank (a precision of 90.8% and a recall of 90.6%). We isolate some dependency relations which previous models neglect but which contribute to higher parse accuracy.
* 8 pages
Do All Fragments Count?
Nov 24, 2000
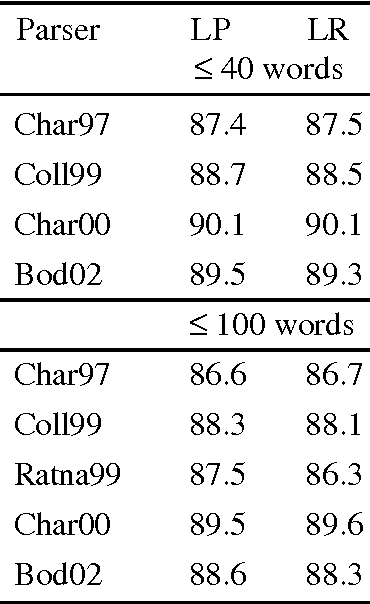
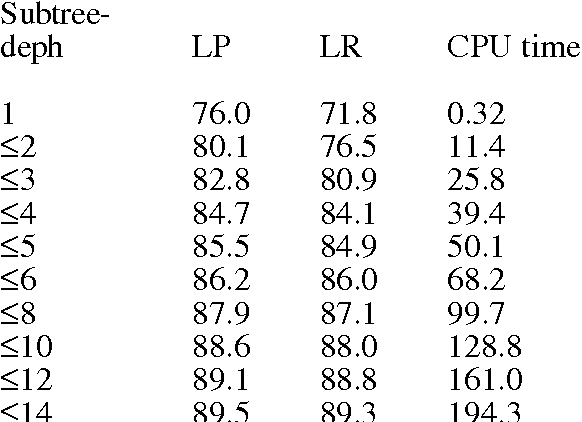
We aim at finding the minimal set of fragments which achieves maximal parse accuracy in Data Oriented Parsing. Experiments with the Penn Wall Street Journal treebank show that counts of almost arbitrary fragments within parse trees are important, leading to improved parse accuracy over previous models tested on this treebank. We isolate a number of dependency relations which previous models neglect but which contribute to higher parse accuracy.
* 18 pages
An improved parser for data-oriented lexical-functional analysis
Sep 27, 2000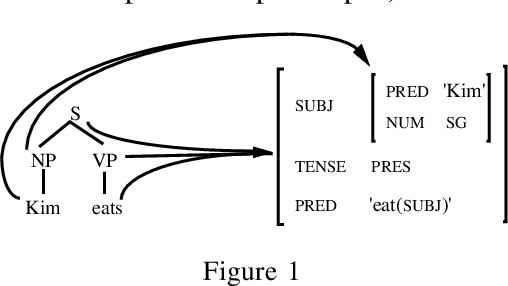
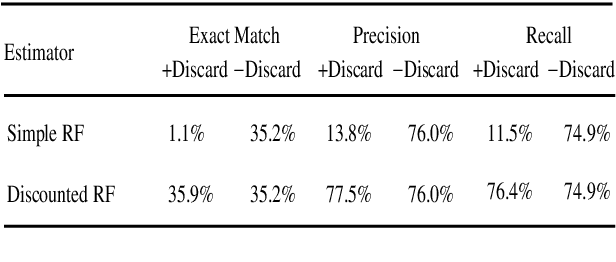

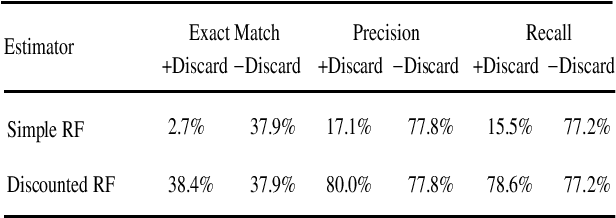
We present an LFG-DOP parser which uses fragments from LFG-annotated sentences to parse new sentences. Experiments with the Verbmobil and Homecentre corpora show that (1) Viterbi n best search performs about 100 times faster than Monte Carlo search while both achieve the same accuracy; (2) the DOP hypothesis which states that parse accuracy increases with increasing fragment size is confirmed for LFG-DOP; (3) LFG-DOP's relative frequency estimator performs worse than a discounted frequency estimator; and (4) LFG-DOP significantly outperforms Tree-DOP is evaluated on tree structures only.
* 8 pages
Parsing with the Shortest Derivation
Sep 27, 2000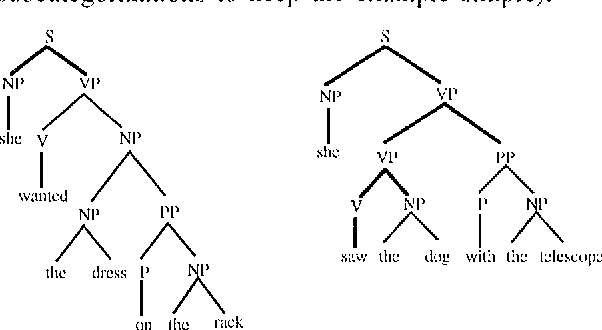
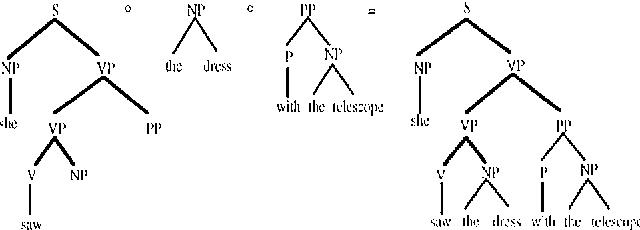
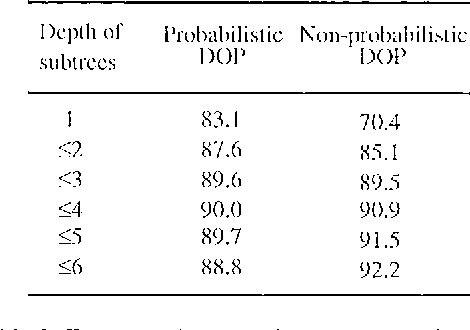
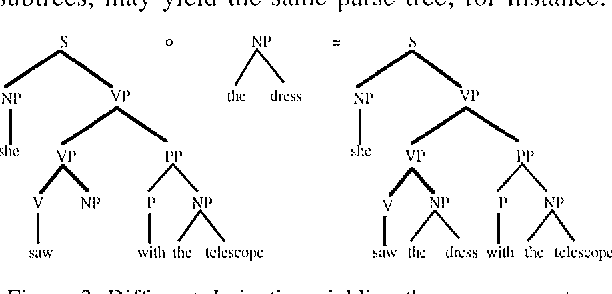
Common wisdom has it that the bias of stochastic grammars in favor of shorter derivations of a sentence is harmful and should be redressed. We show that the common wisdom is wrong for stochastic grammars that use elementary trees instead of context-free rules, such as Stochastic Tree-Substitution Grammars used by Data-Oriented Parsing models. For such grammars a non-probabilistic metric based on the shortest derivation outperforms a probabilistic metric on the ATIS and OVIS corpora, while it obtains very competitive results on the Wall Street Journal corpus. This paper also contains the first published experiments with DOP on the Wall Street Journal.
* 7 pages
Data-Oriented Language Processing. An Overview
Nov 14, 1996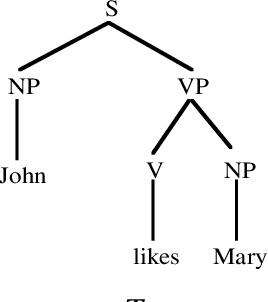
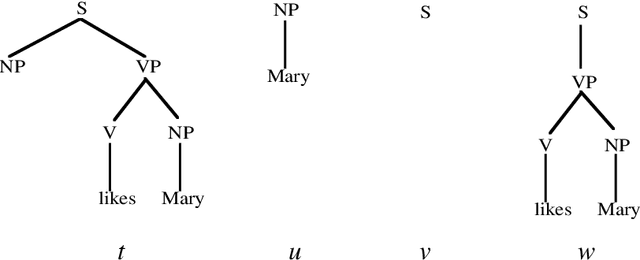
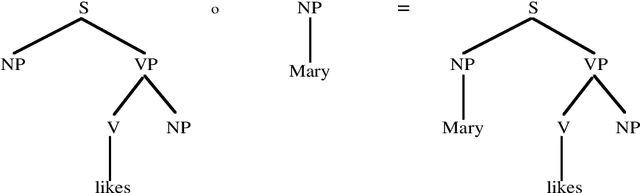
During the last few years, a new approach to language processing has started to emerge, which has become known under various labels such as "data-oriented parsing", "corpus-based interpretation", and "tree-bank grammar" (cf. van den Berg et al. 1994; Bod 1992-96; Bod et al. 1996a/b; Bonnema 1996; Charniak 1996a/b; Goodman 1996; Kaplan 1996; Rajman 1995a/b; Scha 1990-92; Sekine & Grishman 1995; Sima'an et al. 1994; Sima'an 1995-96; Tugwell 1995). This approach, which we will call "data-oriented processing" or "DOP", embodies the assumption that human language perception and production works with representations of concrete past language experiences, rather than with abstract linguistic rules. The models that instantiate this approach therefore maintain large corpora of linguistic representations of previously occurring utterances. When processing a new input utterance, analyses of this utterance are constructed by combining fragments from the corpus; the occurrence-frequencies of the fragments are used to estimate which analysis is the most probable one. In this paper we give an in-depth discussion of a data-oriented processing model which employs a corpus of labelled phrase-structure trees. Then we review some other models that instantiate the DOP approach. Many of these models also employ labelled phrase-structure trees, but use different criteria for extracting fragments from the corpus or employ different disambiguation strategies (Bod 1996b; Charniak 1996a/b; Goodman 1996; Rajman 1995a/b; Sekine & Grishman 1995; Sima'an 1995-96); other models use richer formalisms for their corpus annotations (van den Berg et al. 1994; Bod et al., 1996a/b; Bonnema 1996; Kaplan 1996; Tugwell 1995).
A Data-Oriented Approach to Semantic Interpretation
Jun 18, 1996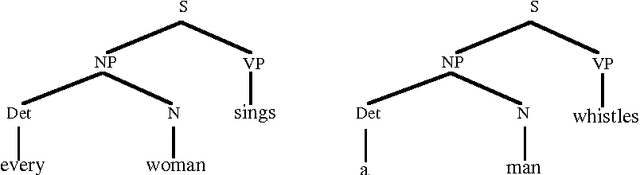
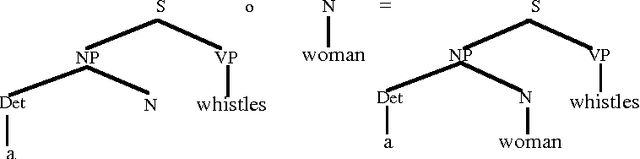
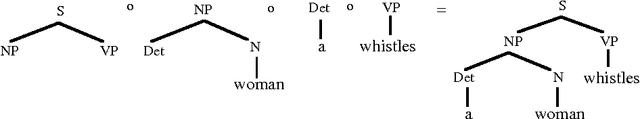
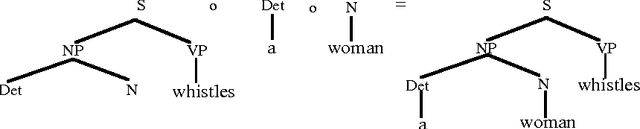
In Data-Oriented Parsing (DOP), an annotated language corpus is used as a stochastic grammar. The most probable analysis of a new input sentence is constructed by combining sub-analyses from the corpus in the most probable way. This approach has been succesfully used for syntactic analysis, using corpora with syntactic annotations such as the Penn Treebank. If a corpus with semantically annotated sentences is used, the same approach can also generate the most probable semantic interpretation of an input sentence. The present paper explains this semantic interpretation method, and summarizes the results of a preliminary experiment. Semantic annotations were added to the syntactic annotations of most of the sentences of the ATIS corpus. A data-oriented semantic interpretation algorithm was succesfully tested on this semantically enriched corpus.
Two Questions about Data-Oriented Parsing
Jun 17, 1996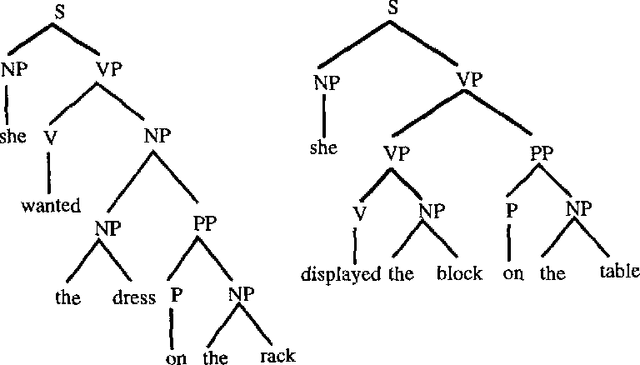
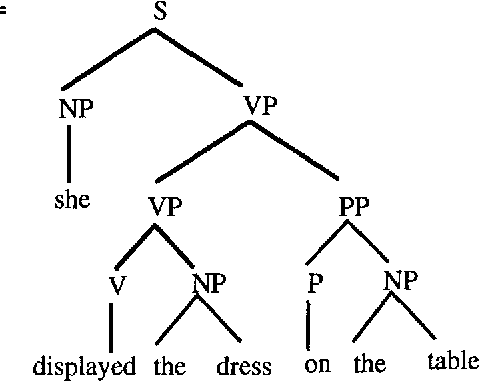
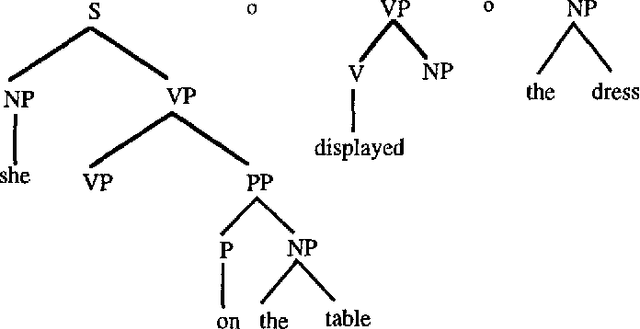
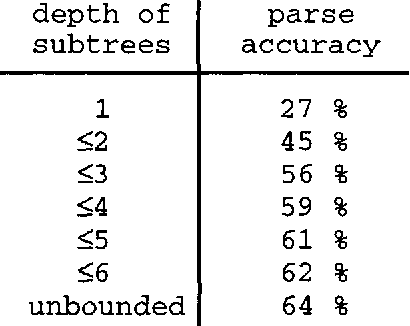
In this paper I present ongoing work on the data-oriented parsing (DOP) model. In previous work, DOP was tested on a cleaned-up set of analyzed part-of-speech strings from the Penn Treebank, achieving excellent test results. This left, however, two important questions unanswered: (1) how does DOP perform if tested on unedited data, and (2) how can DOP be used for parsing word strings that contain unknown words? This paper addresses these questions. We show that parse results on unedited data are worse than on cleaned-up data, although very competitive if compared to other models. As to the parsing of word strings, we show that the hardness of the problem does not so much depend on unknown words, but on previously unseen lexical categories of known words. We give a novel method for parsing these words by estimating the probabilities of unknown subtrees. The method is of general interest since it shows that good performance can be obtained without the use of a part-of-speech tagger. To the best of our knowledge, our method outperforms other statistical parsers tested on Penn Treebank word strings.
Efficient Algorithms for Parsing the DOP Model? A Reply to Joshua Goodman
May 24, 1996This note is a reply to Joshua Goodman's paper "Efficient Algorithms for Parsing the DOP Model" (Goodman, 1996; cmp-lg/9604008). In his paper, Goodman makes a number of claims about (my work on) the Data-Oriented Parsing model (Bod, 1992-1996). This note shows that some of these claims must be mistaken.