Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Data-Oriented Model of Literary Language
Paper and Code
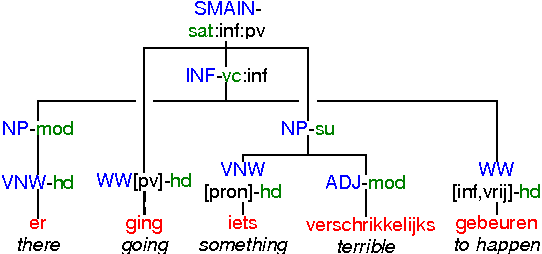


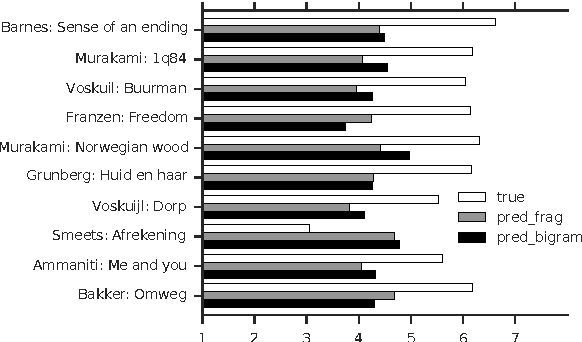
We consider the task of predicting how literary a text is, with a gold standard from human ratings. Aside from a standard bigram baseline, we apply rich syntactic tree fragments, mined from the training set, and a series of hand-picked features. Our model is the first to distinguish degrees of highly and less literary novels using a variety of lexical and syntactic features, and explains 76.0 % of the variation in literary ratings.
* Proceedings of EACL 2017, pp. 1228-1238 * To be published in EACL 2017, 11 pages
View paper on