 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTwo Questions about Data-Oriented Parsing
Paper and Code
Jun 17, 1996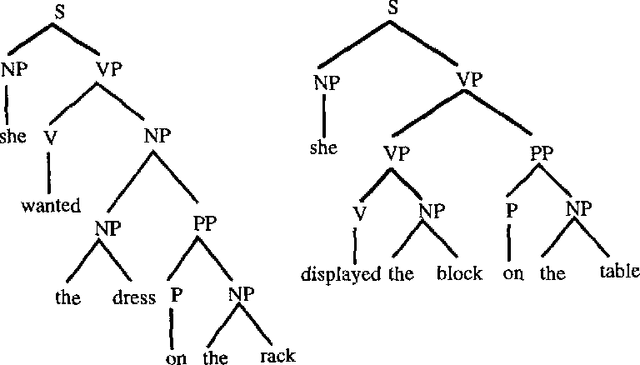
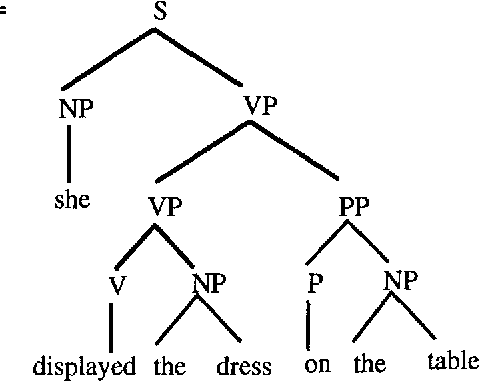
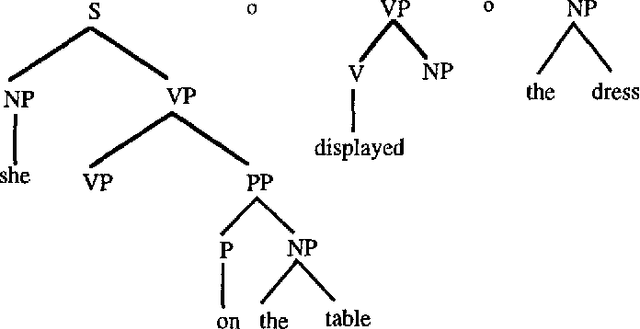
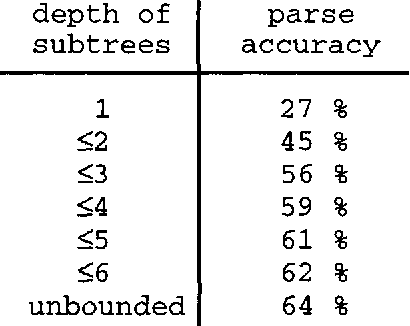
In this paper I present ongoing work on the data-oriented parsing (DOP) model. In previous work, DOP was tested on a cleaned-up set of analyzed part-of-speech strings from the Penn Treebank, achieving excellent test results. This left, however, two important questions unanswered: (1) how does DOP perform if tested on unedited data, and (2) how can DOP be used for parsing word strings that contain unknown words? This paper addresses these questions. We show that parse results on unedited data are worse than on cleaned-up data, although very competitive if compared to other models. As to the parsing of word strings, we show that the hardness of the problem does not so much depend on unknown words, but on previously unseen lexical categories of known words. We give a novel method for parsing these words by estimating the probabilities of unknown subtrees. The method is of general interest since it shows that good performance can be obtained without the use of a part-of-speech tagger. To the best of our knowledge, our method outperforms other statistical parsers tested on Penn Treebank word strings.