 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeData-Oriented Language Processing. An Overview
Nov 14, 1996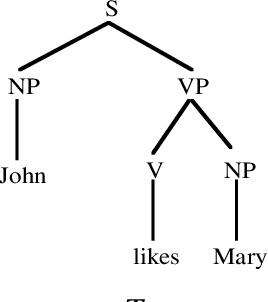
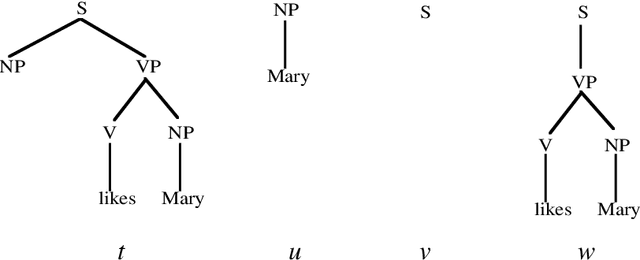
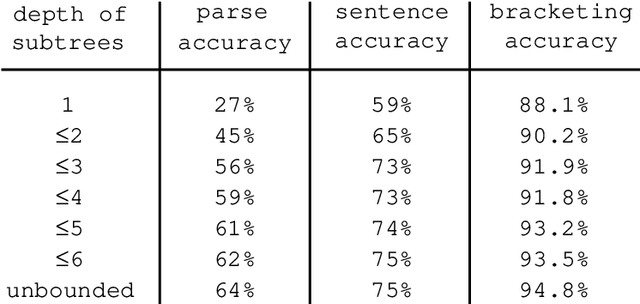
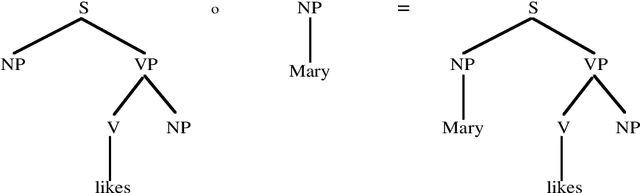
During the last few years, a new approach to language processing has started to emerge, which has become known under various labels such as "data-oriented parsing", "corpus-based interpretation", and "tree-bank grammar" (cf. van den Berg et al. 1994; Bod 1992-96; Bod et al. 1996a/b; Bonnema 1996; Charniak 1996a/b; Goodman 1996; Kaplan 1996; Rajman 1995a/b; Scha 1990-92; Sekine & Grishman 1995; Sima'an et al. 1994; Sima'an 1995-96; Tugwell 1995). This approach, which we will call "data-oriented processing" or "DOP", embodies the assumption that human language perception and production works with representations of concrete past language experiences, rather than with abstract linguistic rules. The models that instantiate this approach therefore maintain large corpora of linguistic representations of previously occurring utterances. When processing a new input utterance, analyses of this utterance are constructed by combining fragments from the corpus; the occurrence-frequencies of the fragments are used to estimate which analysis is the most probable one. In this paper we give an in-depth discussion of a data-oriented processing model which employs a corpus of labelled phrase-structure trees. Then we review some other models that instantiate the DOP approach. Many of these models also employ labelled phrase-structure trees, but use different criteria for extracting fragments from the corpus or employ different disambiguation strategies (Bod 1996b; Charniak 1996a/b; Goodman 1996; Rajman 1995a/b; Sekine & Grishman 1995; Sima'an 1995-96); other models use richer formalisms for their corpus annotations (van den Berg et al. 1994; Bod et al., 1996a/b; Bonnema 1996; Kaplan 1996; Tugwell 1995).
A Data-Oriented Approach to Semantic Interpretation
Jun 18, 1996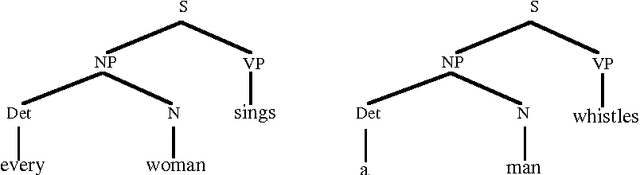
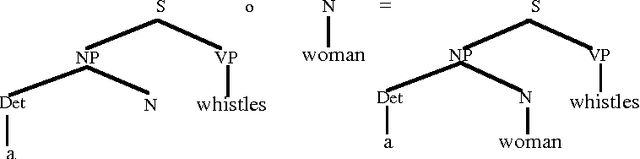
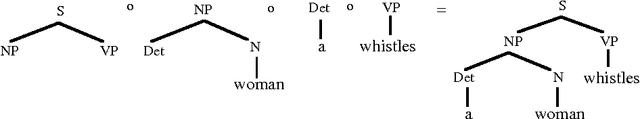
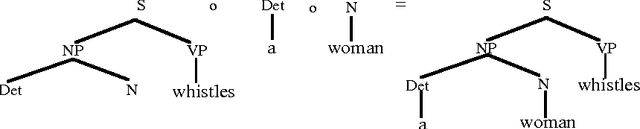
In Data-Oriented Parsing (DOP), an annotated language corpus is used as a stochastic grammar. The most probable analysis of a new input sentence is constructed by combining sub-analyses from the corpus in the most probable way. This approach has been succesfully used for syntactic analysis, using corpora with syntactic annotations such as the Penn Treebank. If a corpus with semantically annotated sentences is used, the same approach can also generate the most probable semantic interpretation of an input sentence. The present paper explains this semantic interpretation method, and summarizes the results of a preliminary experiment. Semantic annotations were added to the syntactic annotations of most of the sentences of the ATIS corpus. A data-oriented semantic interpretation algorithm was succesfully tested on this semantically enriched corpus.