 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSLVMEval: Synthetic Meta Evaluation Benchmark for Text-to-Long Video Generation
Mar 31, 2026This paper proposes the synthetic long-video meta-evaluation (SLVMEval), a benchmark for meta-evaluating text-to-video (T2V) evaluation systems. The proposed SLVMEval benchmark focuses on assessing these systems on videos of up to 10,486 s (approximately 3 h). The benchmark targets a fundamental requirement, namely, whether the systems can accurately assess video quality in settings that are easy for humans to assess. We adopt a pairwise comparison-based meta-evaluation framework. Building on dense video-captioning datasets, we synthetically degrade source videos to create controlled "high-quality versus low-quality" pairs across 10 distinct aspects. Then, we employ crowdsourcing to filter and retain only those pairs in which the degradation is clearly perceptible, thereby establishing an effective final testbed. Using this testbed, we assess the reliability of existing evaluation systems in ranking these pairs. Experimental results demonstrate that human evaluators can identify the better long video with 84.7%-96.8% accuracy, and in nine of the 10 aspects, the accuracy of these systems falls short of human assessment, revealing weaknesses in text-to-long-video evaluation.
Nodes Are Early, Edges Are Late: Probing Diagram Representations in Large Vision-Language Models
Mar 03, 2026Large vision-language models (LVLMs) demonstrate strong performance on diagram understanding benchmarks, yet they still struggle with understanding relationships between elements, particularly those represented by nodes and directed edges (e.g., arrows and lines). To investigate the underlying causes of this limitation, we probe the internal representation of LVLMs using a carefully constructed synthetic diagram dataset based on directed graphs. Our probing experiments reveal that edge information is not linearly separable in the vision encoder and becomes linearly encoded only in the text tokens in the language model. In contrast, node information and global structural features are already linearly encoded in individual hidden states of the vision encoder. These findings suggest that the stage at which linearly separable representations are formed varies depending on the type of visual information. In particular, the delayed emergence of edge representations may help explain why LVLMs struggle with relational understanding, such as interpreting edge directions, which require more abstract, compositionally integrated processes.
Relaxing Positional Alignment in Masked Diffusion Language Models
Jan 30, 2026Masked diffusion language models (MDLMs) have emerged as a promising alternative to dominant autoregressive approaches. Although they achieve competitive performance on several tasks, a substantial gap remains in open-ended text generation. We hypothesize that one cause of this gap is that strict positional prediction makes MDLM decoding highly sensitive to token misalignment, and we show through controlled interventions that a one-position shift can severely disrupt semantics. This observation suggests that enforcing strict positional supervision during training is misaligned with the irreversible denoising dynamics of MDLM decoding. Motivated by this mismatch, we adopt an alignment-flexible supervision strategy during fine-tuning. Specifically, we introduce a special token <slack> via the connectionist temporal classification objective. We apply this approach to the widely used MDLM model and conduct experiments on five open-ended text generation benchmarks. Our method consistently outperforms the original model and improves robustness to positional shifts, indicating that relaxing strict positional supervision is an important factor in improving generation quality in MDLMs.
Weight-based Analysis of Detokenization in Language Models: Understanding the First Stage of Inference Without Inference
Jan 27, 2025



According to the stages-of-inference hypothesis, early layers of language models map their subword-tokenized input, which does not necessarily correspond to a linguistically meaningful segmentation, to more meaningful representations that form the model's ``inner vocabulary''. Prior analysis of this detokenization stage has predominantly relied on probing and interventions such as path patching, which involve selecting particular inputs, choosing a subset of components that will be patched, and then observing changes in model behavior. Here, we show that several important aspects of the detokenization stage can be understood purely by analyzing model weights, without performing any model inference steps. Specifically, we introduce an analytical decomposition of first-layer attention in GPT-2. Our decomposition yields interpretable terms that quantify the relative contributions of position-related, token-related, and mixed effects. By focusing on terms in this decomposition, we discover weight-based explanations of attention bias toward close tokens and attention for detokenization.
Think-to-Talk or Talk-to-Think? When LLMs Come Up with an Answer in Multi-Step Reasoning
Dec 02, 2024



This study investigates the internal reasoning mechanism of language models during symbolic multi-step reasoning, motivated by the question of whether chain-of-thought (CoT) outputs are faithful to the model's internals. Specifically, we inspect when they internally determine their answers, particularly before or after CoT begins, to determine whether models follow a post-hoc "think-to-talk" mode or a step-by-step "talk-to-think" mode of explanation. Through causal probing experiments in controlled arithmetic reasoning tasks, we found systematic internal reasoning patterns across models; for example, simple subproblems are solved before CoT begins, and more complicated multi-hop calculations are performed during CoT.
First Heuristic Then Rational: Dynamic Use of Heuristics in Language Model Reasoning
Jun 23, 2024



Multi-step reasoning is widely adopted in the community to explore the better performance of language models (LMs). We report on the systematic strategy that LMs use in this process. Our controlled experiments reveal that LMs rely more heavily on heuristics, such as lexical overlap, in the earlier stages of reasoning when more steps are required to reach an answer. Conversely, as LMs progress closer to the final answer, their reliance on heuristics decreases. This suggests that LMs track only a limited number of future steps and dynamically combine heuristic strategies with logical ones in tasks involving multi-step reasoning.
ACORN: Aspect-wise Commonsense Reasoning Explanation Evaluation
May 08, 2024



Evaluating free-text explanations is a multifaceted, subjective, and labor-intensive task. Large language models (LLMs) present an appealing alternative due to their potential for consistency, scalability, and cost-efficiency. In this work, we present ACORN, a new dataset of 3,500 free-text explanations and aspect-wise quality ratings, and use it to gain insights into how LLMs evaluate explanations. We observed that replacing one of the human ratings sometimes maintained, but more often lowered the inter-annotator agreement across different settings and quality aspects, suggesting that their judgments are not always consistent with human raters. We further quantified this difference by comparing the correlation between LLM-generated ratings with majority-voted human ratings across different quality aspects. With the best system, Spearman's rank correlation ranged between 0.53 to 0.95, averaging 0.72 across aspects, indicating moderately high but imperfect alignment. Finally, we considered the alternative of using an LLM as an additional rater when human raters are scarce, and measured the correlation between majority-voted labels with a limited human pool and LLMs as an additional rater, compared to the original gold labels. While GPT-4 improved the outcome when there were only two human raters, in all other observed cases, LLMs were neutral to detrimental when there were three or more human raters. We publicly release the dataset to support future improvements in LLM-in-the-loop evaluation here: https://github.com/a-brassard/ACORN.
A Challenging Multimodal Video Summary: Simultaneously Extracting and Generating Keyframe-Caption Pairs from Video
Dec 04, 2023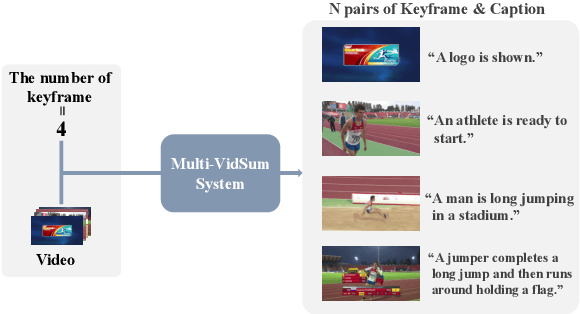

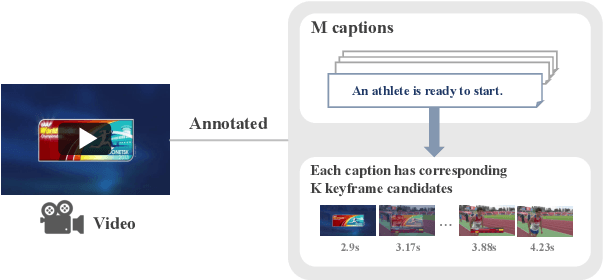
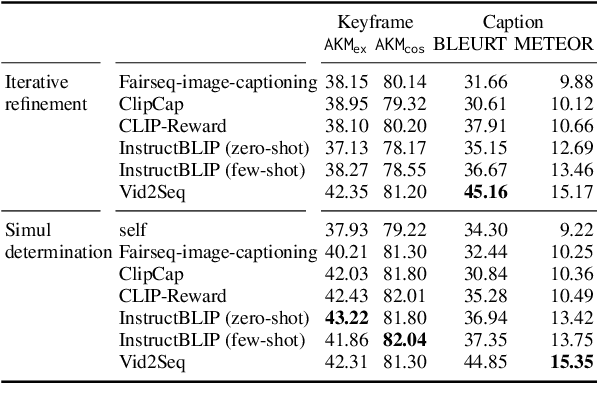
This paper proposes a practical multimodal video summarization task setting and a dataset to train and evaluate the task. The target task involves summarizing a given video into a predefined number of keyframe-caption pairs and displaying them in a listable format to grasp the video content quickly. This task aims to extract crucial scenes from the video in the form of images (keyframes) and generate corresponding captions explaining each keyframe's situation. This task is useful as a practical application and presents a highly challenging problem worthy of study. Specifically, achieving simultaneous optimization of the keyframe selection performance and caption quality necessitates careful consideration of the mutual dependence on both preceding and subsequent keyframes and captions. To facilitate subsequent research in this field, we also construct a dataset by expanding upon existing datasets and propose an evaluation framework. Furthermore, we develop two baseline systems and report their respective performance.
Empirical Investigation of Neural Symbolic Reasoning Strategies
Feb 16, 2023Neural reasoning accuracy improves when generating intermediate reasoning steps. However, the source of this improvement is yet unclear. Here, we investigate and factorize the benefit of generating intermediate steps for symbolic reasoning. Specifically, we decompose the reasoning strategy w.r.t. step granularity and chaining strategy. With a purely symbolic numerical reasoning dataset (e.g., A=1, B=3, C=A+3, C?), we found that the choice of reasoning strategies significantly affects the performance, with the gap becoming even larger as the extrapolation length becomes longer. Surprisingly, we also found that certain configurations lead to nearly perfect performance, even in the case of length extrapolation. Our results indicate the importance of further exploring effective strategies for neural reasoning models.
Do Deep Neural Networks Capture Compositionality in Arithmetic Reasoning?
Feb 15, 2023Compositionality is a pivotal property of symbolic reasoning. However, how well recent neural models capture compositionality remains underexplored in the symbolic reasoning tasks. This study empirically addresses this question by systematically examining recently published pre-trained seq2seq models with a carefully controlled dataset of multi-hop arithmetic symbolic reasoning. We introduce a skill tree on compositionality in arithmetic symbolic reasoning that defines the hierarchical levels of complexity along with three compositionality dimensions: systematicity, productivity, and substitutivity. Our experiments revealed that among the three types of composition, the models struggled most with systematicity, performing poorly even with relatively simple compositions. That difficulty was not resolved even after training the models with intermediate reasoning steps.