Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInstance-Based Neural Dependency Parsing
Paper and Code
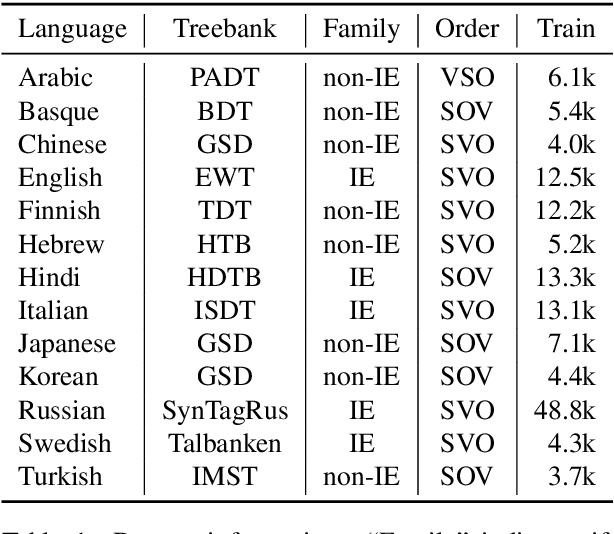
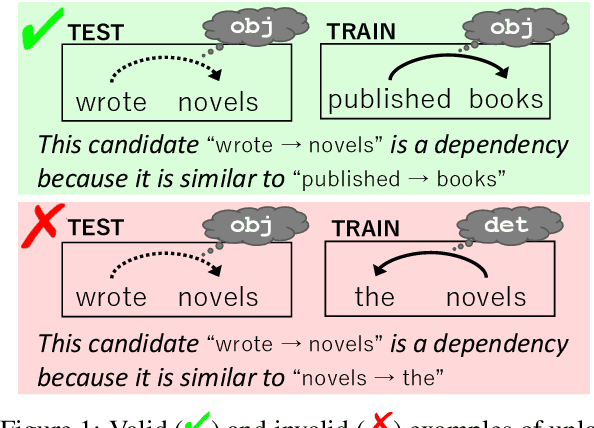

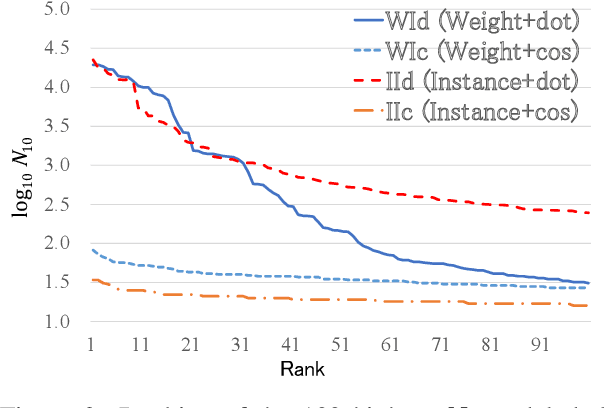
Interpretable rationales for model predictions are crucial in practical applications. We develop neural models that possess an interpretable inference process for dependency parsing. Our models adopt instance-based inference, where dependency edges are extracted and labeled by comparing them to edges in a training set. The training edges are explicitly used for the predictions; thus, it is easy to grasp the contribution of each edge to the predictions. Our experiments show that our instance-based models achieve competitive accuracy with standard neural models and have the reasonable plausibility of instance-based explanations.
* 15 pages, accepted to TACL 2021
View paper on