 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGADFA: Generator-Assisted Decision-Focused Approach for Opinion Expressing Timing Identification
Oct 02, 2024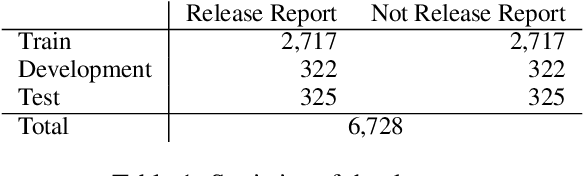
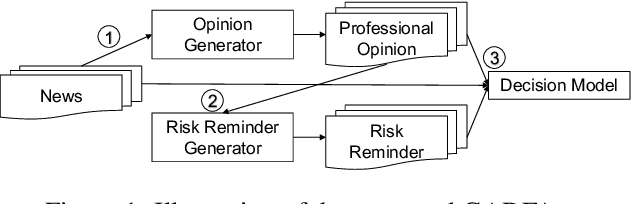

The advancement of text generation models has granted us the capability to produce coherent and convincing text on demand. Yet, in real-life circumstances, individuals do not continuously generate text or voice their opinions. For instance, consumers pen product reviews after weighing the merits and demerits of a product, and professional analysts issue reports following significant news releases. In essence, opinion expression is typically prompted by particular reasons or signals. Despite long-standing developments in opinion mining, the appropriate timing for expressing an opinion remains largely unexplored. To address this deficit, our study introduces an innovative task - the identification of news-triggered opinion expressing timing. We ground this task in the actions of professional stock analysts and develop a novel dataset for investigation. Our approach is decision-focused, leveraging text generation models to steer the classification model, thus enhancing overall performance. Our experimental findings demonstrate that the text generated by our model contributes fresh insights from various angles, effectively aiding in identifying the optimal timing for opinion expression.
Enhancing Financial Sentiment Analysis with Expert-Designed Hint
Sep 26, 2024
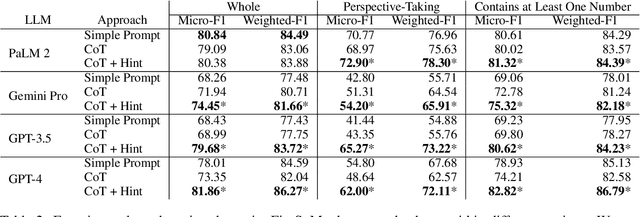


This paper investigates the role of expert-designed hint in enhancing sentiment analysis on financial social media posts. We explore the capability of large language models (LLMs) to empathize with writer perspectives and analyze sentiments. Our findings reveal that expert-designed hint, i.e., pointing out the importance of numbers, significantly improve performances across various LLMs, particularly in cases requiring perspective-taking skills. Further analysis on tweets containing different types of numerical data demonstrates that the inclusion of expert-designed hint leads to notable improvements in sentiment analysis performance, especially for tweets with monetary-related numbers. Our findings contribute to the ongoing discussion on the applicability of Theory of Mind in NLP and open new avenues for improving sentiment analysis in financial domains through the strategic use of expert knowledge.
Enhancing Investment Opinion Ranking through Argument-Based Sentiment Analysis
Sep 25, 2024
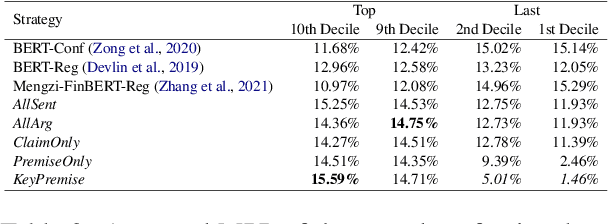


In the era of rapid Internet and social media platform development, individuals readily share their viewpoints online. The overwhelming quantity of these posts renders comprehensive analysis impractical. This necessitates an efficient recommendation system to filter and present significant, relevant opinions. Our research introduces a dual-pronged argument mining technique to improve recommendation system effectiveness, considering both professional and amateur investor perspectives. Our first strategy involves using the discrepancy between target and closing prices as an opinion indicator. The second strategy applies argument mining principles to score investors' opinions, subsequently ranking them by these scores. Experimental results confirm the effectiveness of our approach, demonstrating its ability to identify opinions with higher profit potential. Beyond profitability, our research extends to risk analysis, examining the relationship between recommended opinions and investor behaviors. This offers a holistic view of potential outcomes following the adoption of these recommended opinions.
FinGen: A Dataset for Argument Generation in Finance
May 31, 2024



Thinking about the future is one of the important activities that people do in daily life. Futurists also pay a lot of effort into figuring out possible scenarios for the future. We argue that the exploration of this direction is still in an early stage in the NLP research. To this end, we propose three argument generation tasks in the financial application scenario. Our experimental results show these tasks are still big challenges for representative generation models. Based on our empirical results, we further point out several unresolved issues and challenges in this research direction.
AcTED: Automatic Acquisition of Typical Event Duration for Semi-supervised Temporal Commonsense QA
Mar 27, 2024



We propose a voting-driven semi-supervised approach to automatically acquire the typical duration of an event and use it as pseudo-labeled data. The human evaluation demonstrates that our pseudo labels exhibit surprisingly high accuracy and balanced coverage. In the temporal commonsense QA task, experimental results show that using only pseudo examples of 400 events, we achieve performance comparable to the existing BERT-based weakly supervised approaches that require a significant amount of training examples. When compared to the RoBERTa baselines, our best approach establishes state-of-the-art performance with a 7% improvement in Exact Match.
Dynamically Updating Event Representations for Temporal Relation Classification with Multi-category Learning
Oct 31, 2023Temporal relation classification is a pair-wise task for identifying the relation of a temporal link (TLINK) between two mentions, i.e. event, time, and document creation time (DCT). It leads to two crucial limits: 1) Two TLINKs involving a common mention do not share information. 2) Existing models with independent classifiers for each TLINK category (E2E, E2T, and E2D) hinder from using the whole data. This paper presents an event centric model that allows to manage dynamic event representations across multiple TLINKs. Our model deals with three TLINK categories with multi-task learning to leverage the full size of data. The experimental results show that our proposal outperforms state-of-the-art models and two transfer learning baselines on both the English and Japanese data.
Towards Parameter-Efficient Integration of Pre-Trained Language Models In Temporal Video Grounding
Sep 26, 2022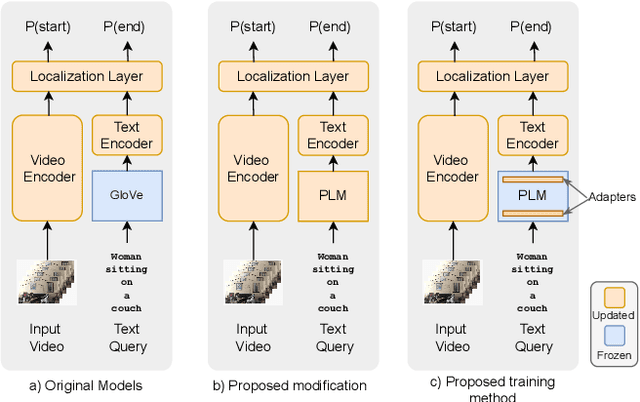
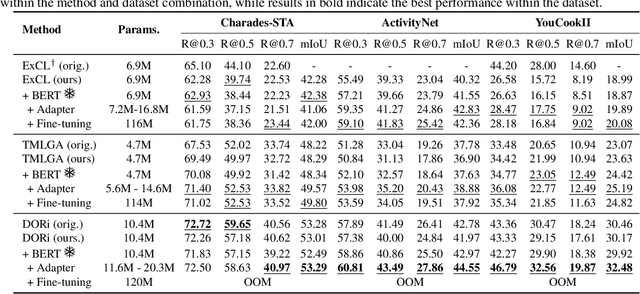
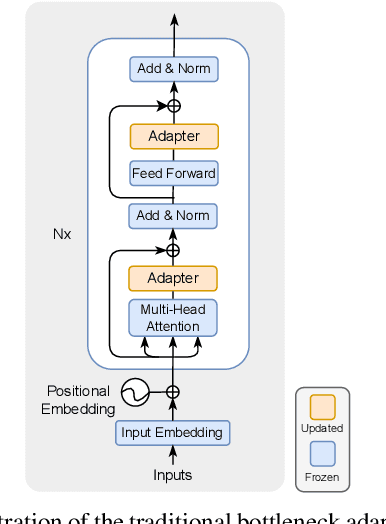
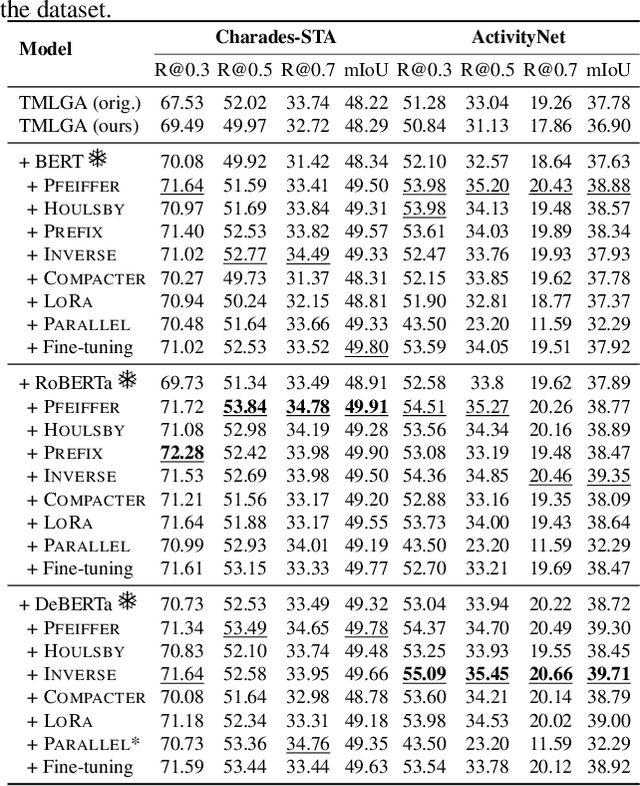
This paper explores the task of Temporal Video Grounding (TVG) where, given an untrimmed video and a query sentence, the goal is to recognize and determine temporal boundaries of action instances in the video described by the provided natural language queries. Recent works solve this task by directly encoding the query using large pre-trained language models (PLM). However, isolating the effects of the improved language representations is difficult, as these works also propose improvements in the visual inputs. Furthermore, these PLMs significantly increase the computational cost of training TVG models. Therefore, this paper studies the effects of PLMs in the TVG task and assesses the applicability of NLP parameter-efficient training alternatives based on adapters. We couple popular PLMs with a selection of existing approaches and test different adapters to reduce the impact of the additional parameters. Our results on three challenging datasets show that TVG models could greatly benefit from PLMs when these are fine-tuned for the task and that adapters are an effective alternative to full fine-tuning, even though they are not tailored for our task. Concretely, adapters helped save on computational cost, allowing PLM integration in larger TVG models and delivering results comparable to the state-of-the-art models. Finally, through benchmarking different types of adapters in TVG, our results shed light on what kind of adapters work best for each studied case.
OCHADAI at SemEval-2022 Task 2: Adversarial Training for Multilingual Idiomaticity Detection
Jun 07, 2022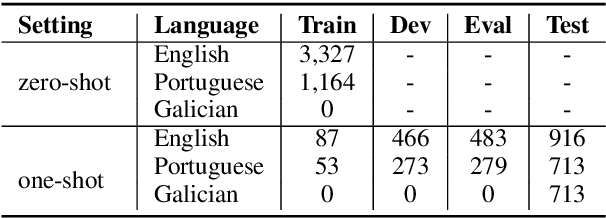

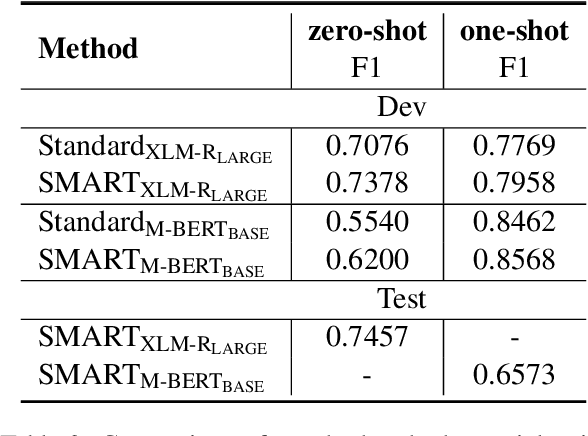
We propose a multilingual adversarial training model for determining whether a sentence contains an idiomatic expression. Given that a key challenge with this task is the limited size of annotated data, our model relies on pre-trained contextual representations from different multi-lingual state-of-the-art transformer-based language models (i.e., multilingual BERT and XLM-RoBERTa), and on adversarial training, a training method for further enhancing model generalization and robustness. Without relying on any human-crafted features, knowledge bases, or additional datasets other than the target datasets, our model achieved competitive results and ranked 6th place in SubTask A (zero-shot) setting and 15th place in SubTask A (one-shot) setting.
* arXiv admin note: substantial text overlap with arXiv:2105.05535
OCHADAI-KYODAI at SemEval-2021 Task 1: Enhancing Model Generalization and Robustness for Lexical Complexity Prediction
May 13, 2021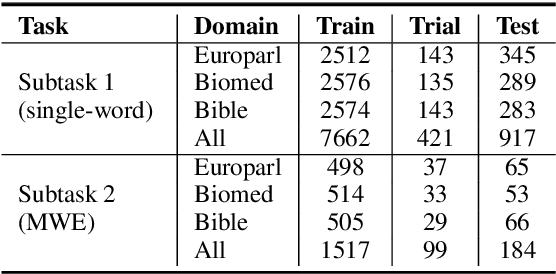
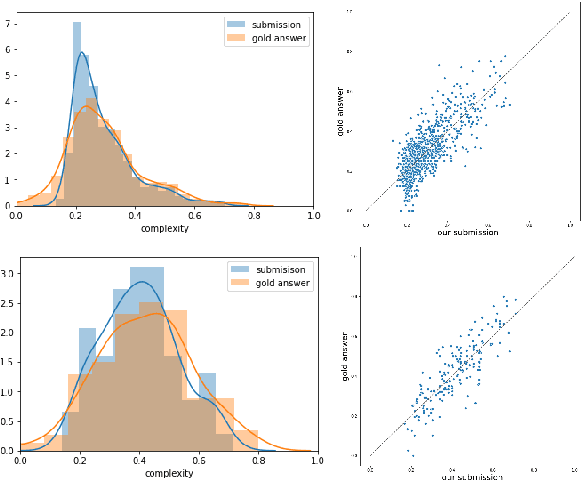

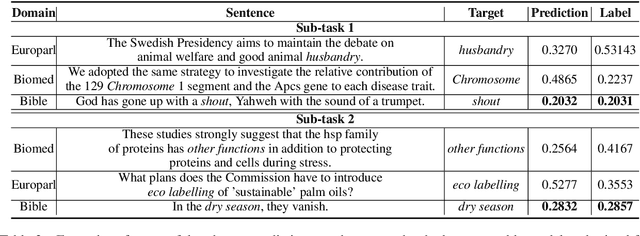
We propose an ensemble model for predicting the lexical complexity of words and multiword expressions (MWEs). The model receives as input a sentence with a target word or MWEand outputs its complexity score. Given that a key challenge with this task is the limited size of annotated data, our model relies on pretrained contextual representations from different state-of-the-art transformer-based language models (i.e., BERT and RoBERTa), and on a variety of training methods for further enhancing model generalization and robustness:multi-step fine-tuning and multi-task learning, and adversarial training. Additionally, we propose to enrich contextual representations by adding hand-crafted features during training. Our model achieved competitive results and ranked among the top-10 systems in both sub-tasks.
Targeted Adversarial Training for Natural Language Understanding
Apr 12, 2021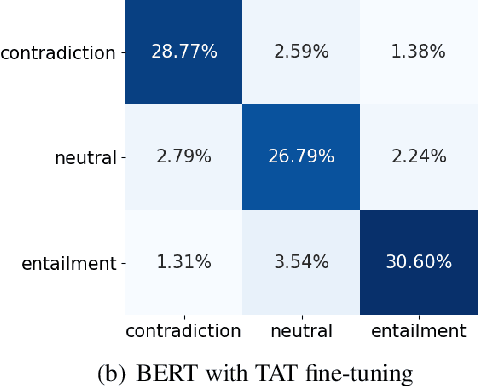
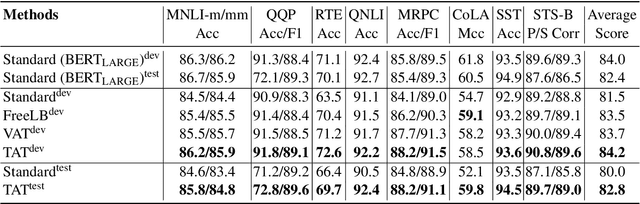
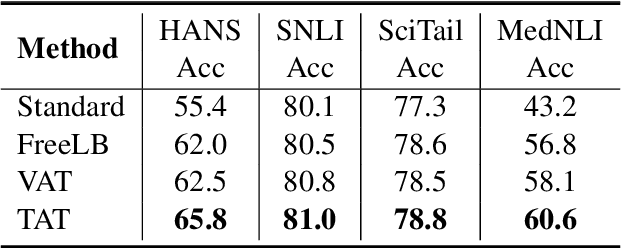
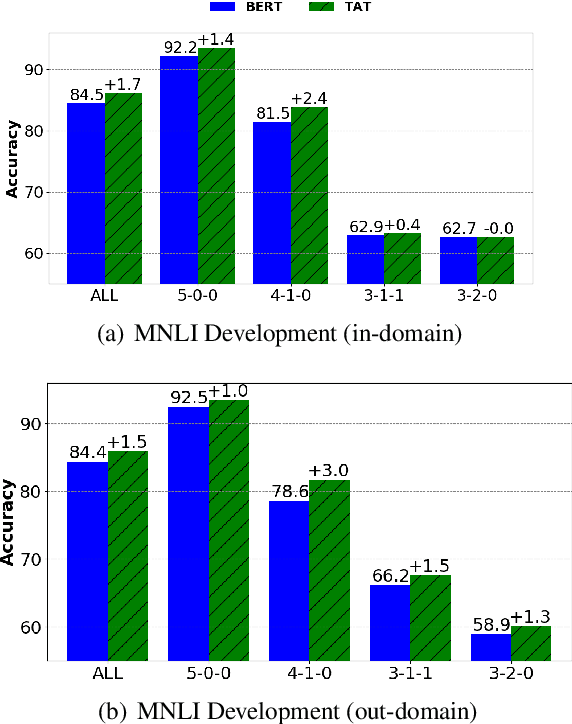
We present a simple yet effective Targeted Adversarial Training (TAT) algorithm to improve adversarial training for natural language understanding. The key idea is to introspect current mistakes and prioritize adversarial training steps to where the model errs the most. Experiments show that TAT can significantly improve accuracy over standard adversarial training on GLUE and attain new state-of-the-art zero-shot results on XNLI. Our code will be released at: https://github.com/namisan/mt-dnn.