 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Parameter-Efficient Integration of Pre-Trained Language Models In Temporal Video Grounding
Paper and Code
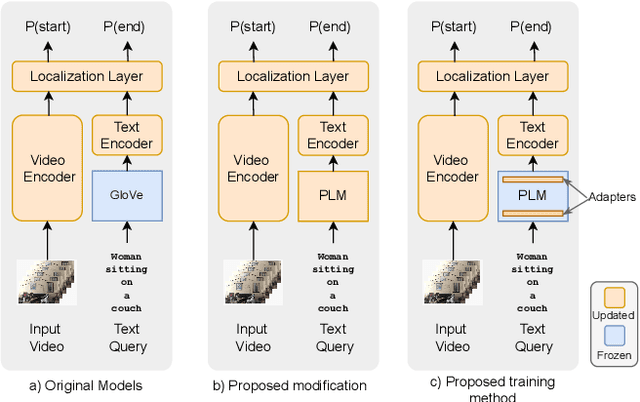
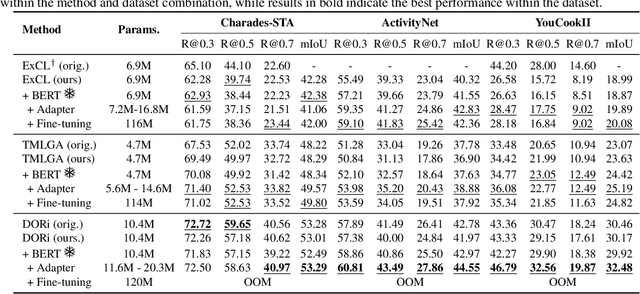
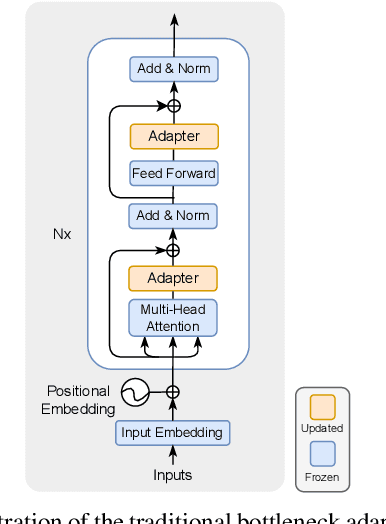
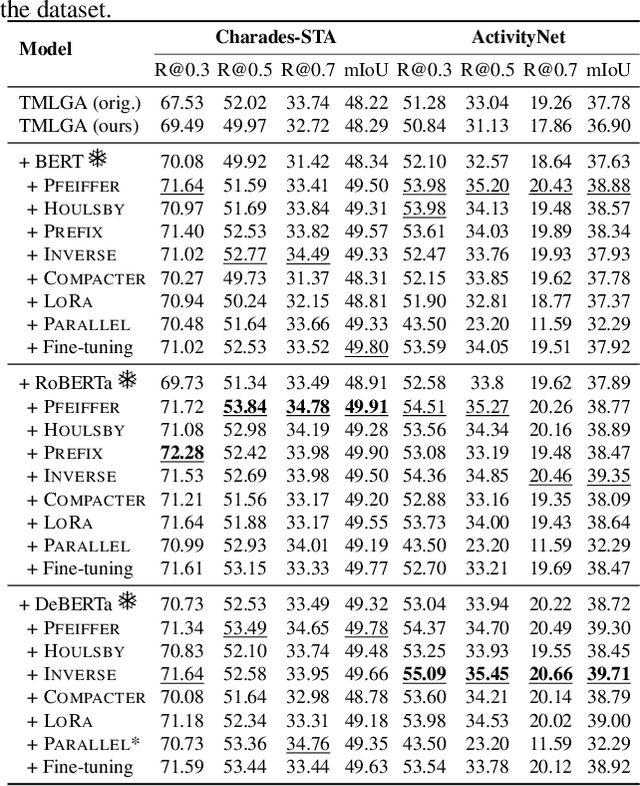
This paper explores the task of Temporal Video Grounding (TVG) where, given an untrimmed video and a query sentence, the goal is to recognize and determine temporal boundaries of action instances in the video described by the provided natural language queries. Recent works solve this task by directly encoding the query using large pre-trained language models (PLM). However, isolating the effects of the improved language representations is difficult, as these works also propose improvements in the visual inputs. Furthermore, these PLMs significantly increase the computational cost of training TVG models. Therefore, this paper studies the effects of PLMs in the TVG task and assesses the applicability of NLP parameter-efficient training alternatives based on adapters. We couple popular PLMs with a selection of existing approaches and test different adapters to reduce the impact of the additional parameters. Our results on three challenging datasets show that TVG models could greatly benefit from PLMs when these are fine-tuned for the task and that adapters are an effective alternative to full fine-tuning, even though they are not tailored for our task. Concretely, adapters helped save on computational cost, allowing PLM integration in larger TVG models and delivering results comparable to the state-of-the-art models. Finally, through benchmarking different types of adapters in TVG, our results shed light on what kind of adapters work best for each studied case.