 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTargeted Adversarial Training for Natural Language Understanding
Apr 12, 2021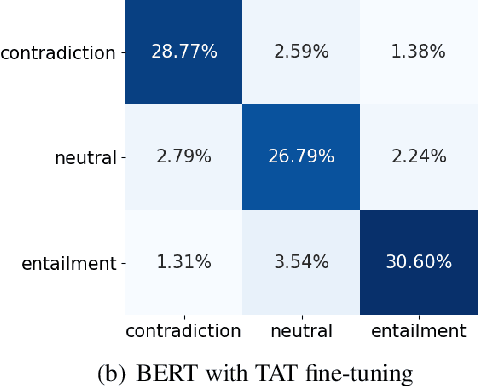
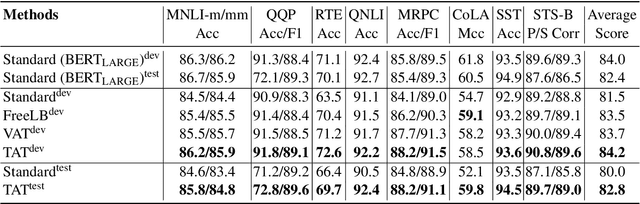
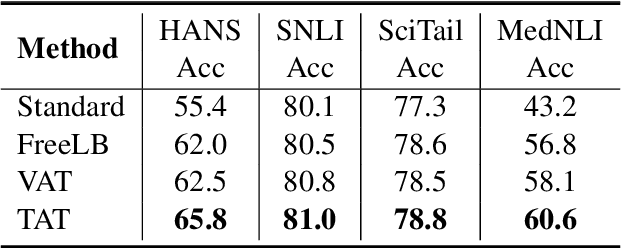
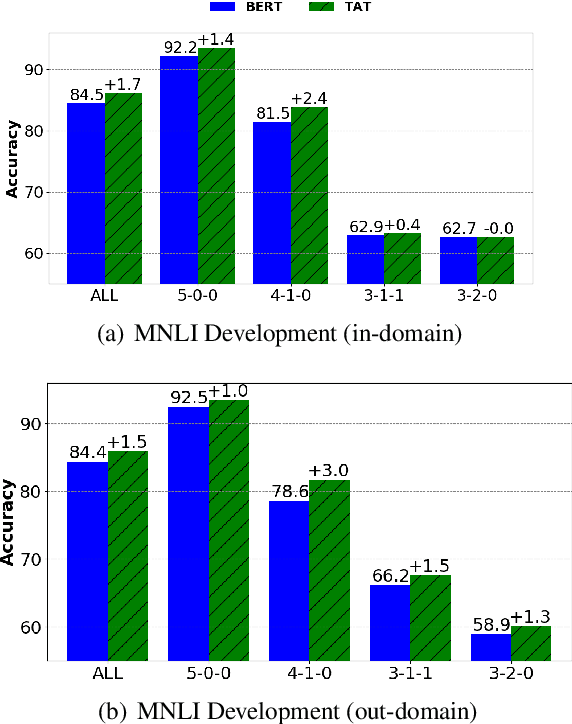
We present a simple yet effective Targeted Adversarial Training (TAT) algorithm to improve adversarial training for natural language understanding. The key idea is to introspect current mistakes and prioritize adversarial training steps to where the model errs the most. Experiments show that TAT can significantly improve accuracy over standard adversarial training on GLUE and attain new state-of-the-art zero-shot results on XNLI. Our code will be released at: https://github.com/namisan/mt-dnn.
Posterior Differential Regularization with f-divergence for Improving Model Robustness
Oct 23, 2020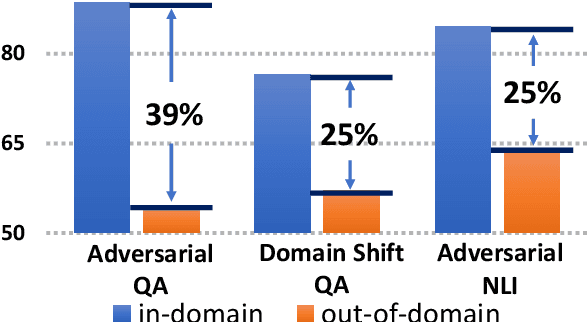

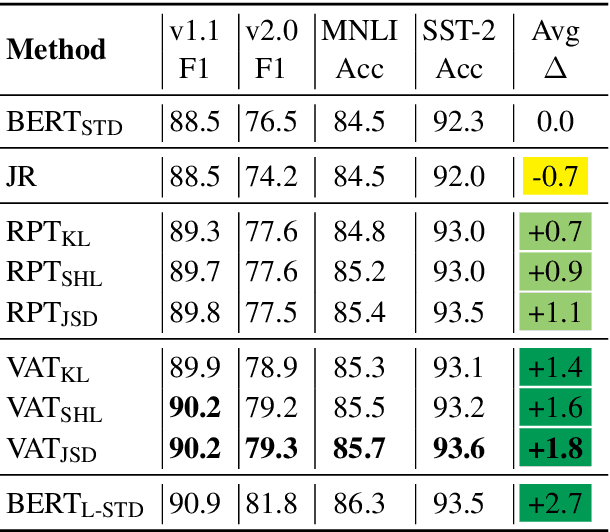
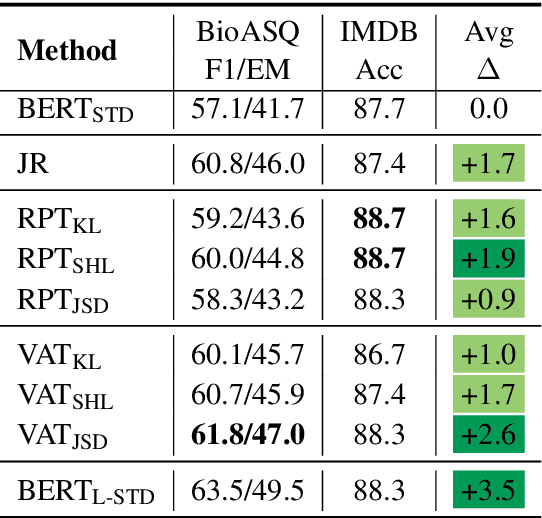
We address the problem of enhancing model robustness through regularization. Specifically, we focus on methods that regularize the model posterior difference between clean and noisy inputs. Theoretically, we provide a connection of two recent methods, Jacobian Regularization and Virtual Adversarial Training, under this framework. Additionally, we generalize the posterior differential regularization to the family of $f$-divergences and characterize the overall regularization framework in terms of Jacobian matrix. Empirically, we systematically compare those regularizations and standard BERT training on a diverse set of tasks to provide a comprehensive profile of their effect on model in-domain and out-of-domain generalization. For both fully supervised and semi-supervised settings, our experiments show that regularizing the posterior differential with $f$-divergence can result in well-improved model robustness. In particular, with a proper $f$-divergence, a BERT-base model can achieve comparable generalization as its BERT-large counterpart for in-domain, adversarial and domain shift scenarios, indicating the great potential of the proposed framework for boosting model generalization for NLP models.
Adversarial Training for Commonsense Inference
May 17, 2020

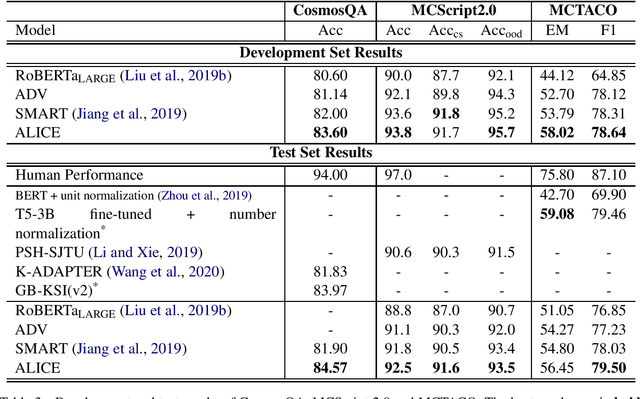
We propose an AdversariaL training algorithm for commonsense InferenCE (ALICE). We apply small perturbations to word embeddings and minimize the resultant adversarial risk to regularize the model. We exploit a novel combination of two different approaches to estimate these perturbations: 1) using the true label and 2) using the model prediction. Without relying on any human-crafted features, knowledge bases, or additional datasets other than the target datasets, our model boosts the fine-tuning performance of RoBERTa, achieving competitive results on multiple reading comprehension datasets that require commonsense inference.
* 6 pages, Accepted to ACL2020 RepL4NLP workshop