 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePosterior Differential Regularization with f-divergence for Improving Model Robustness
Paper and Code
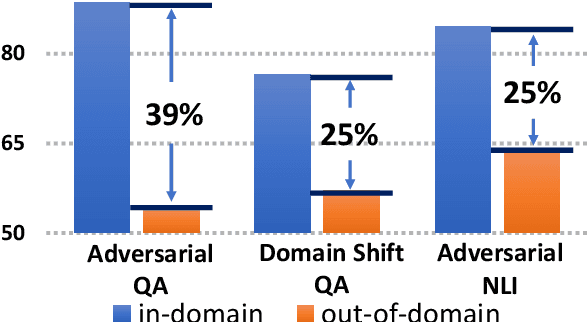

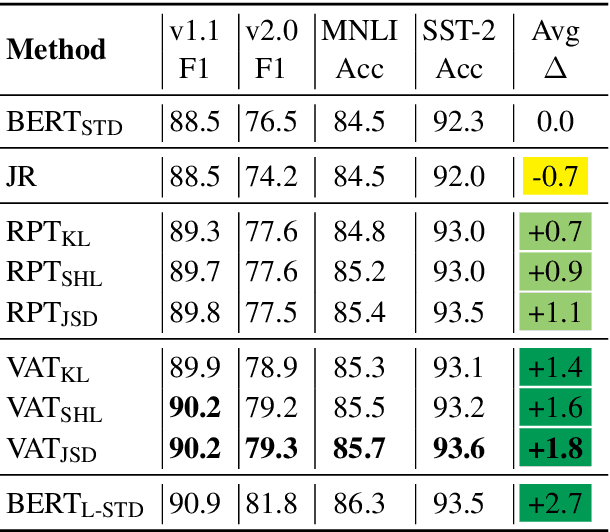
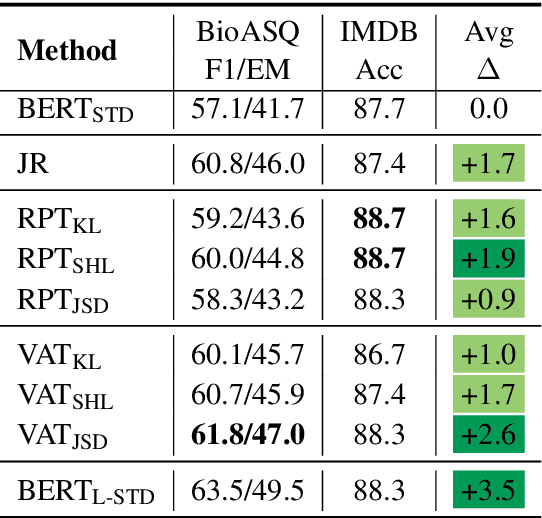
We address the problem of enhancing model robustness through regularization. Specifically, we focus on methods that regularize the model posterior difference between clean and noisy inputs. Theoretically, we provide a connection of two recent methods, Jacobian Regularization and Virtual Adversarial Training, under this framework. Additionally, we generalize the posterior differential regularization to the family of $f$-divergences and characterize the overall regularization framework in terms of Jacobian matrix. Empirically, we systematically compare those regularizations and standard BERT training on a diverse set of tasks to provide a comprehensive profile of their effect on model in-domain and out-of-domain generalization. For both fully supervised and semi-supervised settings, our experiments show that regularizing the posterior differential with $f$-divergence can result in well-improved model robustness. In particular, with a proper $f$-divergence, a BERT-base model can achieve comparable generalization as its BERT-large counterpart for in-domain, adversarial and domain shift scenarios, indicating the great potential of the proposed framework for boosting model generalization for NLP models.