 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn analysis of the utility of explicit negative examples to improve the syntactic abilities of neural language models
Paper and Code
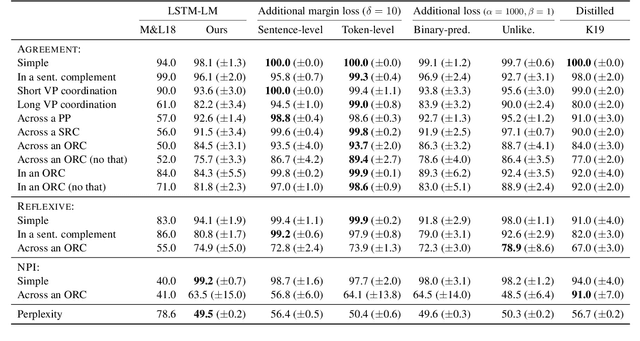
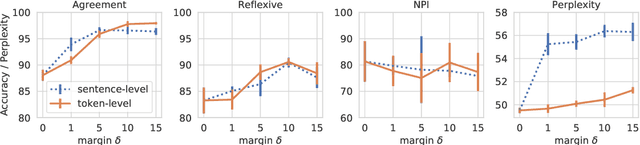
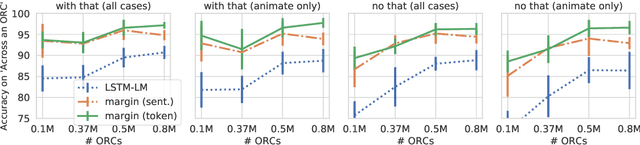

We explore the utilities of explicit negative examples in training neural language models. Negative examples here are incorrect words in a sentence, such as "barks" in "*The dogs barks". Neural language models are commonly trained only on positive examples, a set of sentences in the training data, but recent studies suggest that the models trained in this way are not capable of robustly handling complex syntactic constructions, such as long-distance agreement. In this paper, using English data, we first demonstrate that appropriately using negative examples about particular constructions (e.g., subject-verb agreement) will boost the model's robustness on them, with a negligible loss of perplexity. The key to our success is an additional margin loss between the log-likelihoods of a correct word and an incorrect word. We then provide a detailed analysis of the trained models. One of our findings is the difficulty of object-relative clauses for RNNs. We find that even with our direct learning signals the models still suffer from resolving agreement across an object-relative clause. Augmentation of training sentences involving the constructions somewhat helps, but the accuracy still does not reach the level of subject-relative clauses. Although not directly cognitively appealing, our method can be a tool to analyze the true architectural limitation of neural models on challenging linguistic constructions.