 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLarge Language Models are Perplexed by some Political Parties
Jun 04, 2026Large Language Models (LLMs) are increasingly used, including in political applications, but their political fairness has been little studied. We assess it using perplexity, posing that a fair model should give equal probability to all political groups. However, we find, across ten LLMs and three datasets covering 37 languages, that LLMs are more perplexed by the texts of far right and nationalist parties than of social-democratic parties. We find this to be consistent with previous work on translation fairness, to the point that perplexity correlates with downstream translation metrics. Our method is applicable to both base LLMs as well as their instruction-tuned counterpart, and we find that both are highly correlated, suggesting that the political fairness of LLMs stems from their pretraining, and is hardly affected by instruction-tuning.
Assessing the Political Fairness of Multilingual LLMs: A Case Study based on a 21-way Multiparallel EuroParl Dataset
Oct 23, 2025The political biases of Large Language Models (LLMs) are usually assessed by simulating their answers to English surveys. In this work, we propose an alternative framing of political biases, relying on principles of fairness in multilingual translation. We systematically compare the translation quality of speeches in the European Parliament (EP), observing systematic differences with majority parties from left, center, and right being better translated than outsider parties. This study is made possible by a new, 21-way multiparallel version of EuroParl, the parliamentary proceedings of the EP, which includes the political affiliations of each speaker. The dataset consists of 1.5M sentences for a total of 40M words and 249M characters. It covers three years, 1000+ speakers, 7 countries, 12 EU parties, 25 EU committees, and hundreds of national parties.
Cross-modal Retrieval for Knowledge-based Visual Question Answering
Jan 11, 2024Knowledge-based Visual Question Answering about Named Entities is a challenging task that requires retrieving information from a multimodal Knowledge Base. Named entities have diverse visual representations and are therefore difficult to recognize. We argue that cross-modal retrieval may help bridge the semantic gap between an entity and its depictions, and is foremost complementary with mono-modal retrieval. We provide empirical evidence through experiments with a multimodal dual encoder, namely CLIP, on the recent ViQuAE, InfoSeek, and Encyclopedic-VQA datasets. Additionally, we study three different strategies to fine-tune such a model: mono-modal, cross-modal, or joint training. Our method, which combines mono-and cross-modal retrieval, is competitive with billion-parameter models on the three datasets, while being conceptually simpler and computationally cheaper.
Multimodal Inverse Cloze Task for Knowledge-based Visual Question Answering
Jan 11, 2023


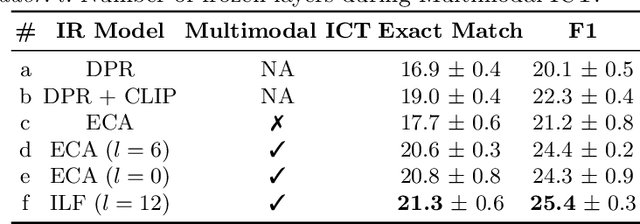
We present a new pre-training method, Multimodal Inverse Cloze Task, for Knowledge-based Visual Question Answering about named Entities (KVQAE). KVQAE is a recently introduced task that consists in answering questions about named entities grounded in a visual context using a Knowledge Base. Therefore, the interaction between the modalities is paramount to retrieve information and must be captured with complex fusion models. As these models require a lot of training data, we design this pre-training task from existing work in textual Question Answering. It consists in considering a sentence as a pseudo-question and its context as a pseudo-relevant passage and is extended by considering images near texts in multimodal documents. Our method is applicable to different neural network architectures and leads to a 9% relative-MRR and 15% relative-F1 gain for retrieval and reading comprehension, respectively, over a no-pre-training baseline.