 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultimodal Entity Linking for Tweets
Apr 07, 2021

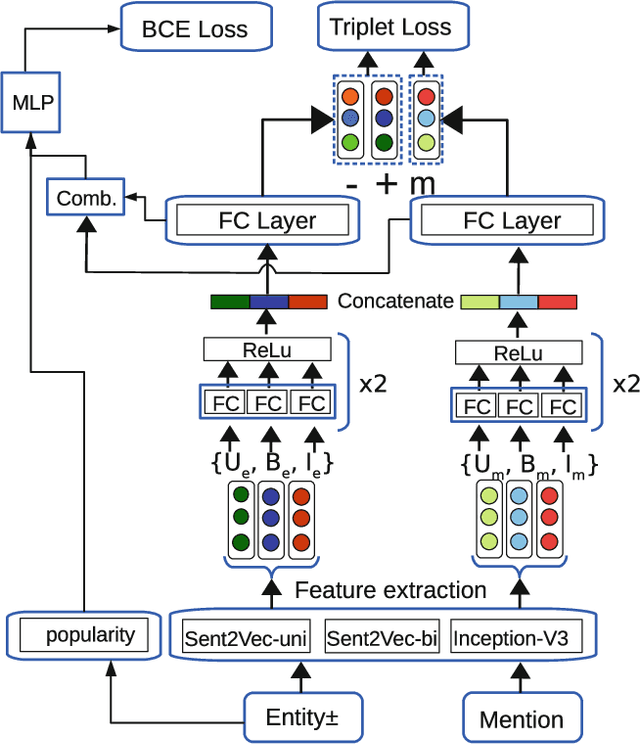

In many information extraction applications, entity linking (EL) has emerged as a crucial task that allows leveraging information about named entities from a knowledge base. In this paper, we address the task of multimodal entity linking (MEL), an emerging research field in which textual and visual information is used to map an ambiguous mention to an entity in a knowledge base (KB). First, we propose a method for building a fully annotated Twitter dataset for MEL, where entities are defined in a Twitter KB. Then, we propose a model for jointly learning a representation of both mentions and entities from their textual and visual contexts. We demonstrate the effectiveness of the proposed model by evaluating it on the proposed dataset and highlight the importance of leveraging visual information when it is available.
How to Pre-Train Your Model? Comparison of Different Pre-Training Models for Biomedical Question Answering
Nov 02, 2019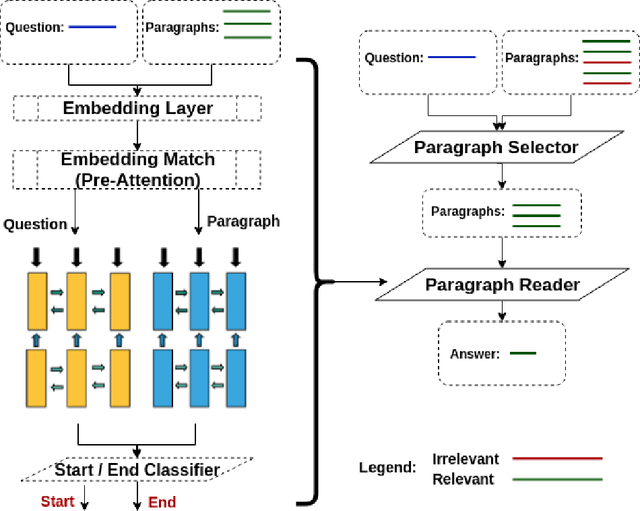
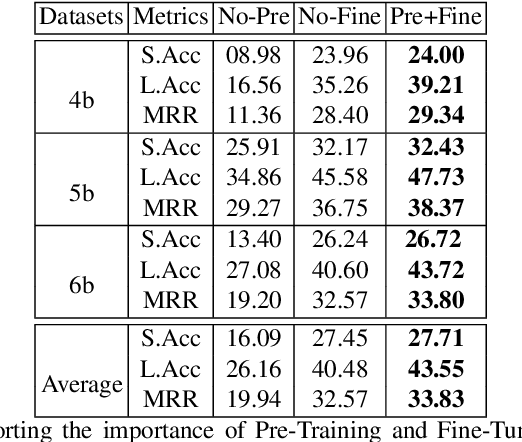
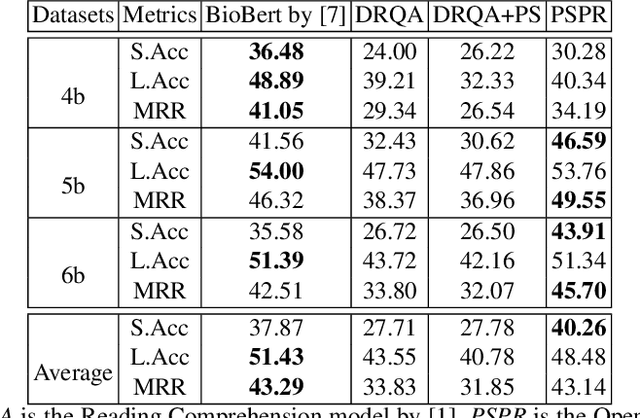
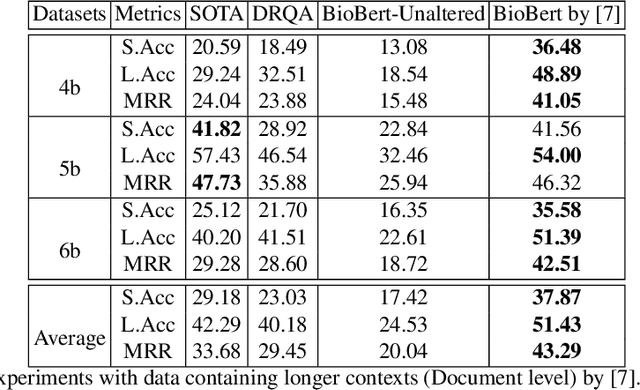
Using deep learning models on small scale datasets would result in overfitting. To overcome this problem, the process of pre-training a model and fine-tuning it to the small scale dataset has been used extensively in domains such as image processing. Similarly for question answering, pre-training and fine-tuning can be done in several ways. Commonly reading comprehension models are used for pre-training, but we show that other types of pre-training can work better. We compare two pre-training models based on reading comprehension and open domain question answering models and determine the performance when fine-tuned and tested over BIOASQ question answering dataset. We find open domain question answering model to be a better fit for this task rather than reading comprehension model.
Système d'aide à l'accès lexical : trouver le mot qu'on a sur le bout de la langue
Jan 20, 2012
The study of the Tip of the Tongue phenomenon (TOT) provides valuable clues and insights concerning the organisation of the mental lexicon (meaning, number of syllables, relation with other words, etc.). This paper describes a tool based on psycho-linguistic observations concerning the TOT phenomenon. We've built it to enable a speaker/writer to find the word he is looking for, word he may know, but which he is unable to access in time. We try to simulate the TOT phenomenon by creating a situation where the system knows the target word, yet is unable to access it. In order to find the target word we make use of the paradigmatic and syntagmatic associations stored in the linguistic databases. Our experiment allows the following conclusion: a tool like SVETLAN, capable to structure (automatically) a dictionary by domains can be used sucessfully to help the speaker/writer to find the word he is looking for, if it is combined with a database rich in terms of paradigmatic links like EuroWordNet.