 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOne-Step Token-to-Waveform Generation with MeanFlow in Latent Space
Jun 16, 2026Neural audio codecs are central to modern LLM-based Text-to-Speech (TTS) and multimodal systems. As low-bitrate semantic codecs gain prominence, the Token-to-Waveform (Token2Wav) decoder becomes a bottleneck determining both perceptual quality and system efficiency. Conventional multi-step flow-matching decoders offer superior quality but suffer from high inference latency due to iterative sampling, creating a severe quality-speed trade-off. In this paper, we propose a novel Token2Wav architecture that overcomes this limitation by applying MeanFlow in a highly compressed latent space. By modeling the average velocity rather than the instantaneous velocity field, MeanFlow enables true one-step generation. Operating in the latent domain mitigates the memory and stability issues of waveform-level flows, yielding up to a 17$\times$ improvement in Real-Time Factor (RTF) compared to multi-step baselines with negligible quality degradation. Furthermore, we introduce refinement strategies that mitigate latent mismatch, including decoder-only fine-tuning with the MeanFlow generator frozen and end-to-end joint fine-tuning, improving fidelity without increasing inference-time cost. Code and demo are publicly available.
Natural Yet Challenging to Detect: Robust In-the-Wild TTS through EMA and Dual-Scoring Prompt Selection -- Submission for WildSpoof 2026 TTS Track
May 22, 2026In this technical report, we describe our submission for the WildSpoof Challenge TTS Track: Text-to-Speech with In-the-Wild Data. We introduce F5-TTS-DPS, a model built upon the F5-TTS architecture. Our approach integrates Exponential Moving Average (EMA) into supervised fine-tuning to stabilize training and improve generalization. To enhance synthesis fidelity, we leverage large language models (LLMs) and large audio language models (LALMs) for dual-scoring prompt selection, filtering reference audio and text prompts to ensure quality while addressing alignment issues in noisy datasets. Experimental evaluation demonstrates that F5-TTS-DPS achieves strong performance with UTMOS of 3.20 and speaker similarity of 0.51 on the development set. More importantly, our model achieves the best a-DCF scores of 0.1582, 0.5233, and 0.2562 across three advanced SASV systems among all submissions, indicating our synthesized speech is the most difficult to detect and exhibits the highest degree of naturalness and authenticity. Combined with competitive WER performance, these results validate the effectiveness of our approach in generating natural-sounding speech with strong spoofing capabilities.
ARCHI-TTS: A flow-matching-based Text-to-Speech Model with Self-supervised Semantic Aligner and Accelerated Inference
Feb 05, 2026Although diffusion-based, non-autoregressive text-to-speech (TTS) systems have demonstrated impressive zero-shot synthesis capabilities, their efficacy is still hindered by two key challenges: the difficulty of text-speech alignment modeling and the high computational overhead of the iterative denoising process. To address these limitations, we propose ARCHI-TTS that features a dedicated semantic aligner to ensure robust temporal and semantic consistency between text and audio. To overcome high computational inference costs, ARCHI-TTS employs an efficient inference strategy that reuses encoder features across denoising steps, drastically accelerating synthesis without performance degradation. An auxiliary CTC loss applied to the condition encoder further enhances the semantic understanding. Experimental results demonstrate that ARCHI-TTS achieves a WER of 1.98% on LibriSpeech-PC test-clean, and 1.47%/1.42% on SeedTTS test-en/test-zh with a high inference efficiency, consistently outperforming recent state-of-the-art TTS systems.
SemanticAudio: Audio Generation and Editing in Semantic Space
Jan 29, 2026In recent years, Text-to-Audio Generation has achieved remarkable progress, offering sound creators powerful tools to transform textual inspirations into vivid audio. However, existing models predominantly operate directly in the acoustic latent space of a Variational Autoencoder (VAE), often leading to suboptimal alignment between generated audio and textual descriptions. In this paper, we introduce SemanticAudio, a novel framework that conducts both audio generation and editing directly in a high-level semantic space. We define this semantic space as a compact representation capturing the global identity and temporal sequence of sound events, distinct from fine-grained acoustic details. SemanticAudio employs a two-stage Flow Matching architecture: the Semantic Planner first generates these compact semantic features to sketch the global semantic layout, and the Acoustic Synthesizer subsequently produces high-fidelity acoustic latents conditioned on this semantic plan. Leveraging this decoupled design, we further introduce a training-free text-guided editing mechanism that enables precise attribute-level modifications on general audio without retraining. Specifically, this is achieved by steering the semantic generation trajectory via the difference of velocity fields derived from source and target text prompts. Extensive experiments demonstrate that SemanticAudio surpasses existing mainstream approaches in semantic alignment. Demo available at: https://semanticaudio1.github.io/
DeepNuParc: A Novel Deep Clustering Framework for Fine-scale Parcellation of Brain Nuclei Using Diffusion MRI Tractography
Mar 10, 2025



Brain nuclei are clusters of anatomically distinct neurons that serve as important hubs for processing and relaying information in various neural circuits. Fine-scale parcellation of the brain nuclei is vital for a comprehensive understanding of its anatomico-functional correlations. Diffusion MRI tractography is an advanced imaging technique that can estimate the brain's white matter structural connectivity to potentially reveal the topography of the nuclei of interest for studying its subdivisions. In this work, we present a deep clustering pipeline, namely DeepNuParc, to perform automated, fine-scale parcellation of brain nuclei using diffusion MRI tractography. First, we incorporate a newly proposed deep learning approach to enable accurate segmentation of the nuclei of interest directly on the dMRI data. Next, we design a novel streamline clustering-based structural connectivity feature for a robust representation of voxels within the nuclei. Finally, we improve the popular joint dimensionality reduction and k-means clustering approach to enable nuclei parcellation at a finer scale. We demonstrate DeepNuParc on two important brain structures, i.e. the amygdala and the thalamus, that are known to have multiple anatomically and functionally distinct nuclei subdivisions. Experimental results show that DeepNuParc enables consistent parcellation of the nuclei into multiple parcels across multiple subjects and achieves good correspondence with the widely used coarse-scale atlases. Our codes are available at https://github.com/HarlandZZC/deep_nuclei_parcellation.
A Novel Deep Clustering Framework for Fine-Scale Parcellation of Amygdala Using dMRI Tractography
Nov 25, 2023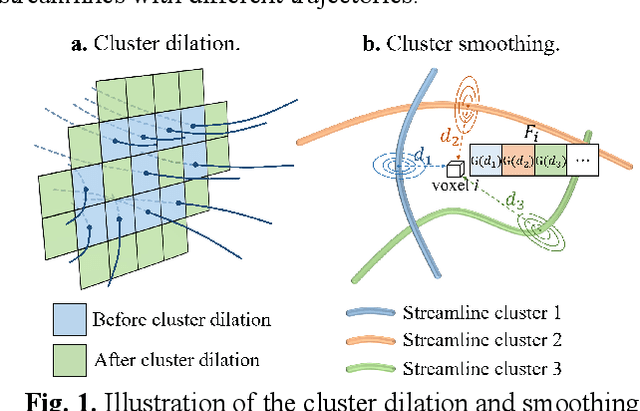
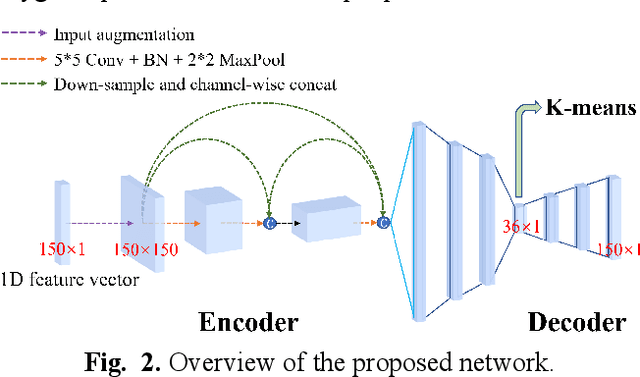
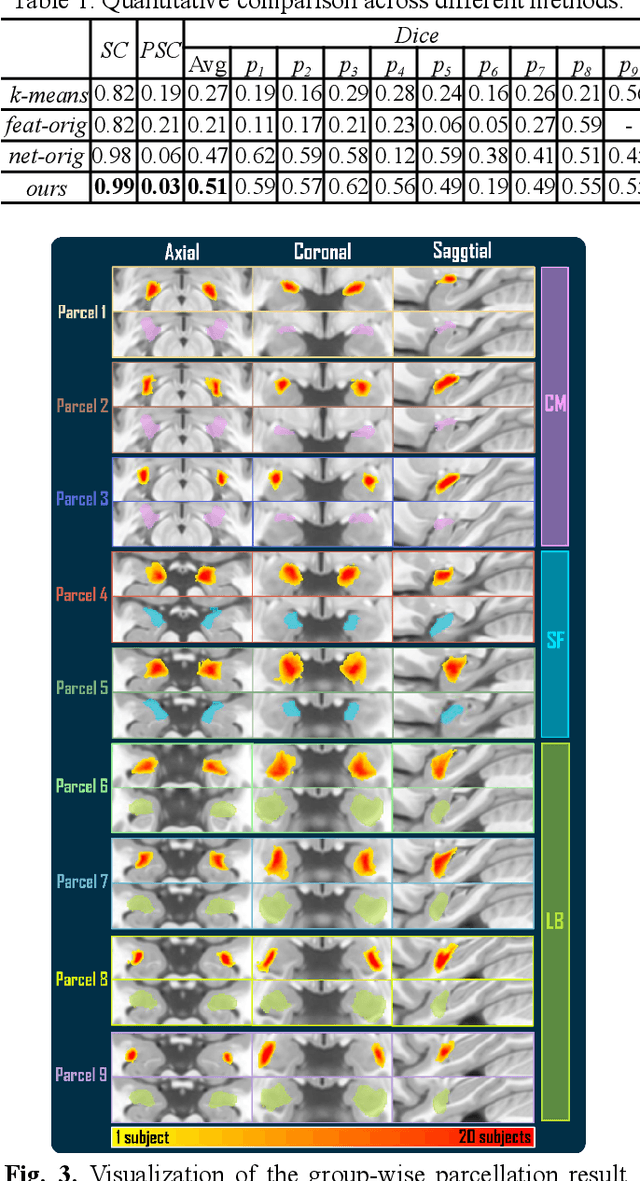
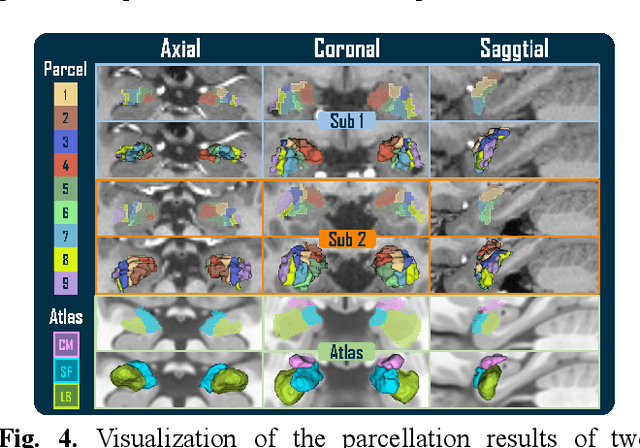
The amygdala plays a vital role in emotional processing and exhibits structural diversity that necessitates fine-scale parcellation for a comprehensive understanding of its anatomico-functional correlations. Diffusion MRI tractography is an advanced imaging technique that can estimate the brain's white matter structural connectivity to potentially reveal the topography of the amygdala for studying its subdivisions. In this work, we present a deep clustering pipeline to perform automated, fine-scale parcellation of the amygdala using diffusion MRI tractography. First, we incorporate a newly proposed deep learning approach to enable accurate segmentation of the amygdala directly on the dMRI data. Next, we design a novel streamline clustering-based structural connectivity feature for a robust representation of voxels within the amygdala. Finally, we improve the popular joint dimensionality reduction and k-means clustering approach to enable amygdala parcellation at a finer scale. With the proposed method, we obtain nine unique amygdala parcels. Experiments show that these parcels can be consistently identified across subjects and have good correspondence to the widely used coarse-scale amygdala parcellation.