 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhich Speech Representation Better Matches Text-Native Reasoning? A Study of Speech-Text Alignment on Frame Rate and Representation
Jun 10, 2026Spoken dialogue models typically start from text LLM backbones, yet reasoning often degrades when conditioning on speech instead of text. We attribute part of this modality gap to a temporal-granularity mismatch: speech tokens are temporally redundant and far longer than text under matched semantics, diluting per-token semantic density and weakening text-native reasoning dynamics. We study speech token design as a representation selection problem and sweep frame rates under a frozen LLM backbone with a fixed information rate. To make low frame rates feasible, we introduce factorized FSQ and a lightweight non-autoregressive audio LM head, scaling capacity to nearly 300\,bits/frame without sacrificing efficient prediction. With the bottleneck removed, we sweep frame rates (50$\rightarrow$2.08\,Hz) and alignment depth, and observe a consistent best regime for speech QA at 4.17\,Hz with intermediate-layer representation alignment.
ARCHI-TTS: A flow-matching-based Text-to-Speech Model with Self-supervised Semantic Aligner and Accelerated Inference
Feb 05, 2026Although diffusion-based, non-autoregressive text-to-speech (TTS) systems have demonstrated impressive zero-shot synthesis capabilities, their efficacy is still hindered by two key challenges: the difficulty of text-speech alignment modeling and the high computational overhead of the iterative denoising process. To address these limitations, we propose ARCHI-TTS that features a dedicated semantic aligner to ensure robust temporal and semantic consistency between text and audio. To overcome high computational inference costs, ARCHI-TTS employs an efficient inference strategy that reuses encoder features across denoising steps, drastically accelerating synthesis without performance degradation. An auxiliary CTC loss applied to the condition encoder further enhances the semantic understanding. Experimental results demonstrate that ARCHI-TTS achieves a WER of 1.98% on LibriSpeech-PC test-clean, and 1.47%/1.42% on SeedTTS test-en/test-zh with a high inference efficiency, consistently outperforming recent state-of-the-art TTS systems.
Improving Audio Generation with Visual Enhanced Caption
Jul 05, 2024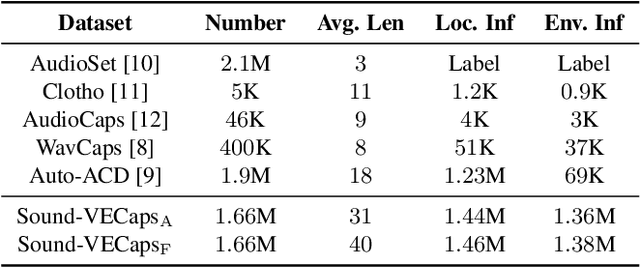

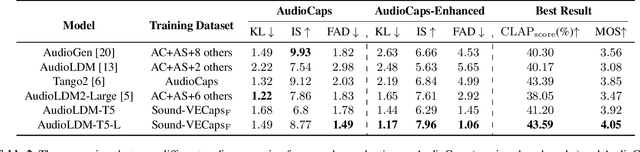

Generative models have shown significant achievements in audio generation tasks. However, existing models struggle with complex and detailed prompts, leading to potential performance degradation. We hypothesize that this problem stems from the low quality and relatively small quantity of training data. In this work, we aim to create a large-scale audio dataset with rich captions for improving audio generation models. We develop an automated pipeline to generate detailed captions for audio-visual datasets by transforming predicted visual captions, audio captions, and tagging labels into comprehensive descriptions using a Large Language Model (LLM). We introduce Sound-VECaps, a dataset comprising 1.66M high-quality audio-caption pairs with enriched details including audio event orders, occurred places and environment information. We demonstrate that training with Sound-VECaps significantly enhances the capability of text-to-audio generation models to comprehend and generate audio from complex input prompts, improving overall system performance. Furthermore, we conduct ablation studies of Sound-VECaps across several audio-language tasks, suggesting its potential in advancing audio-text representation learning. Our dataset and models are available online.
Seed-TTS: A Family of High-Quality Versatile Speech Generation Models
Jun 04, 2024



We introduce Seed-TTS, a family of large-scale autoregressive text-to-speech (TTS) models capable of generating speech that is virtually indistinguishable from human speech. Seed-TTS serves as a foundation model for speech generation and excels in speech in-context learning, achieving performance in speaker similarity and naturalness that matches ground truth human speech in both objective and subjective evaluations. With fine-tuning, we achieve even higher subjective scores across these metrics. Seed-TTS offers superior controllability over various speech attributes such as emotion and is capable of generating highly expressive and diverse speech for speakers in the wild. Furthermore, we propose a self-distillation method for speech factorization, as well as a reinforcement learning approach to enhance model robustness, speaker similarity, and controllability. We additionally present a non-autoregressive (NAR) variant of the Seed-TTS model, named $\text{Seed-TTS}_\text{DiT}$, which utilizes a fully diffusion-based architecture. Unlike previous NAR-based TTS systems, $\text{Seed-TTS}_\text{DiT}$ does not depend on pre-estimated phoneme durations and performs speech generation through end-to-end processing. We demonstrate that this variant achieves comparable performance to the language model-based variant and showcase its effectiveness in speech editing. We encourage readers to listen to demos at \url{https://bytedancespeech.github.io/seedtts_tech_report}.
Controllable and Lossless Non-Autoregressive End-to-End Text-to-Speech
Jul 13, 2022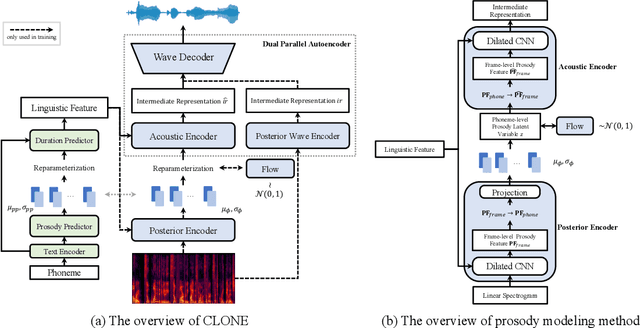
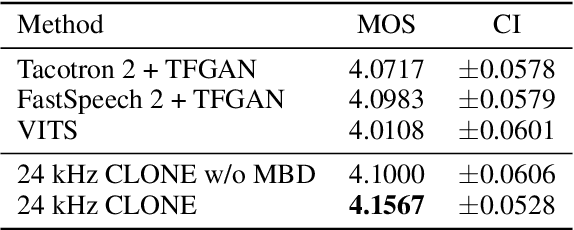
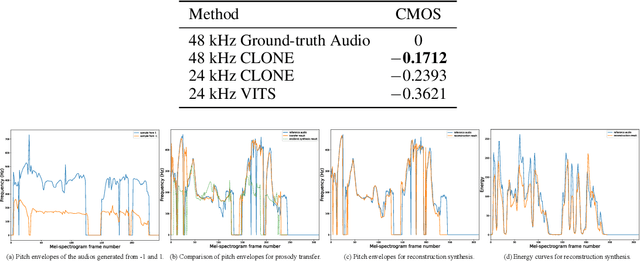

Some recent studies have demonstrated the feasibility of single-stage neural text-to-speech, which does not need to generate mel-spectrograms but generates the raw waveforms directly from the text. Single-stage text-to-speech often faces two problems: a) the one-to-many mapping problem due to multiple speech variations and b) insufficiency of high frequency reconstruction due to the lack of supervision of ground-truth acoustic features during training. To solve the a) problem and generate more expressive speech, we propose a novel phoneme-level prosody modeling method based on a variational autoencoder with normalizing flows to model underlying prosodic information in speech. We also use the prosody predictor to support end-to-end expressive speech synthesis. Furthermore, we propose the dual parallel autoencoder to introduce supervision of the ground-truth acoustic features during training to solve the b) problem enabling our model to generate high-quality speech. We compare the synthesis quality with state-of-the-art text-to-speech systems on an internal expressive English dataset. Both qualitative and quantitative evaluations demonstrate the superiority and robustness of our method for lossless speech generation while also showing a strong capability in prosody modeling.
Basis-MelGAN: Efficient Neural Vocoder Based on Audio Decomposition
Jun 25, 2021
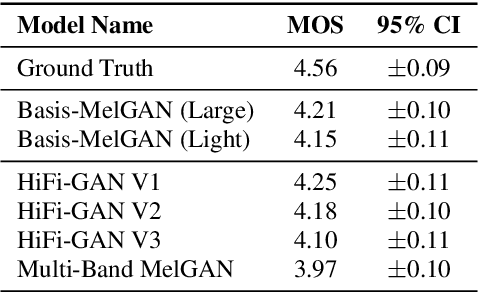
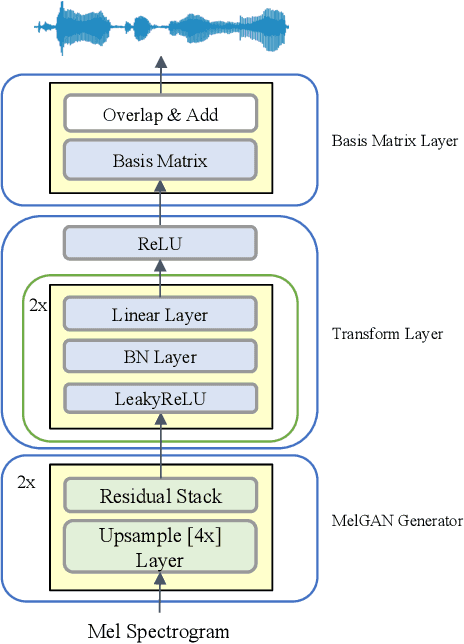
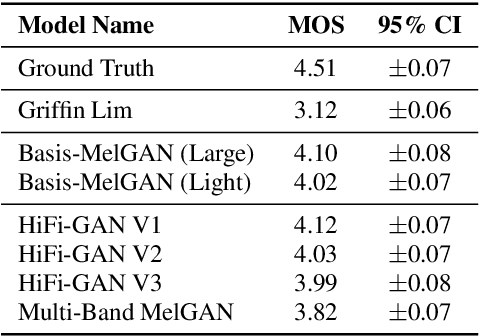
Recent studies have shown that neural vocoders based on generative adversarial network (GAN) can generate audios with high quality. While GAN based neural vocoders have shown to be computationally much more efficient than those based on autoregressive predictions, the real-time generation of the highest quality audio on CPU is still a very challenging task. One major computation of all GAN-based neural vocoders comes from the stacked upsampling layers, which were designed to match the length of the waveform's length of output and temporal resolution. Meanwhile, the computational complexity of upsampling networks is closely correlated with the numbers of samples generated for each window. To reduce the computation of upsampling layers, we propose a new GAN based neural vocoder called Basis-MelGAN where the raw audio samples are decomposed with a learned basis and their associated weights. As the prediction targets of Basis-MelGAN are the weight values associated with each learned basis instead of the raw audio samples, the upsampling layers in Basis-MelGAN can be designed with much simpler networks. Compared with other GAN based neural vocoders, the proposed Basis-MelGAN could produce comparable high-quality audio but significantly reduced computational complexity from HiFi-GAN V1's 17.74 GFLOPs to 7.95 GFLOPs.