 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Audio Generation with Visual Enhanced Caption
Paper and Code
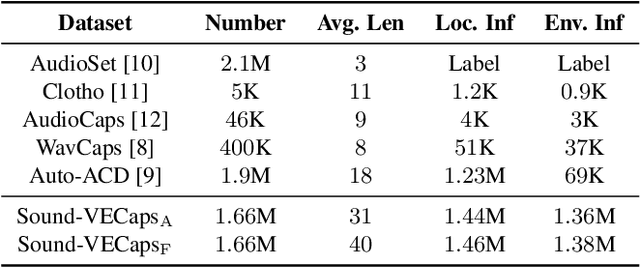

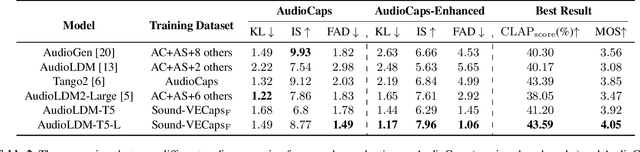

Generative models have shown significant achievements in audio generation tasks. However, existing models struggle with complex and detailed prompts, leading to potential performance degradation. We hypothesize that this problem stems from the low quality and relatively small quantity of training data. In this work, we aim to create a large-scale audio dataset with rich captions for improving audio generation models. We develop an automated pipeline to generate detailed captions for audio-visual datasets by transforming predicted visual captions, audio captions, and tagging labels into comprehensive descriptions using a Large Language Model (LLM). We introduce Sound-VECaps, a dataset comprising 1.66M high-quality audio-caption pairs with enriched details including audio event orders, occurred places and environment information. We demonstrate that training with Sound-VECaps significantly enhances the capability of text-to-audio generation models to comprehend and generate audio from complex input prompts, improving overall system performance. Furthermore, we conduct ablation studies of Sound-VECaps across several audio-language tasks, suggesting its potential in advancing audio-text representation learning. Our dataset and models are available online.