 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeU-Style: Cascading U-nets with Multi-level Speaker and Style Modeling for Zero-Shot Voice Cloning
Oct 06, 2023
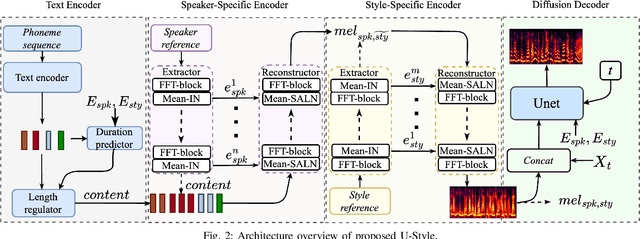
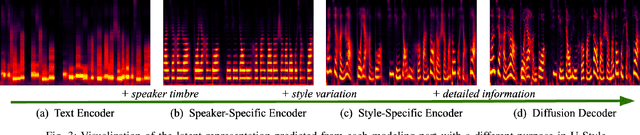
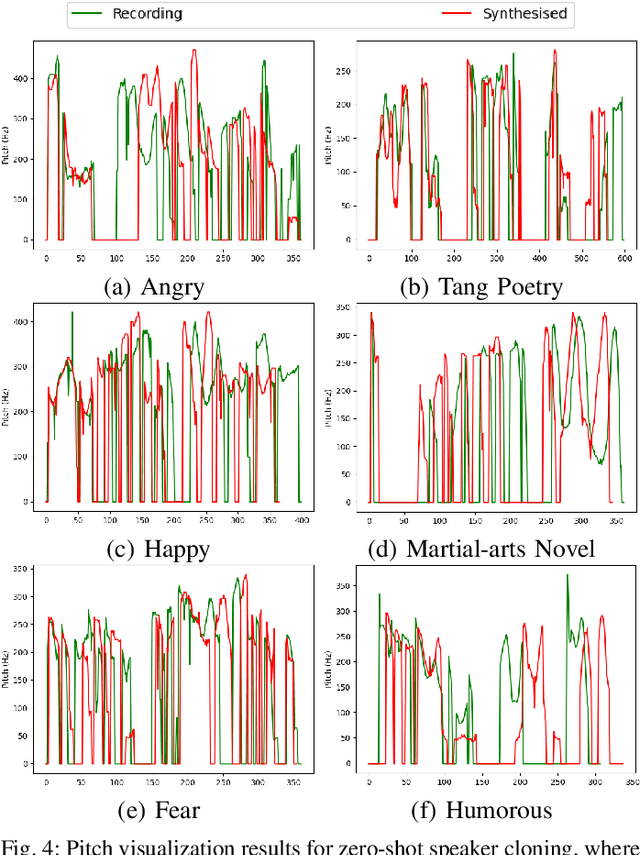
Zero-shot speaker cloning aims to synthesize speech for any target speaker unseen during TTS system building, given only a single speech reference of the speaker at hand. Although more practical in real applications, the current zero-shot methods still produce speech with undesirable naturalness and speaker similarity. Moreover, endowing the target speaker with arbitrary speaking styles in the zero-shot setup has not been considered. This is because the unique challenge of zero-shot speaker and style cloning is to learn the disentangled speaker and style representations from only short references representing an arbitrary speaker and an arbitrary style. To address this challenge, we propose U-Style, which employs Grad-TTS as the backbone, particularly cascading a speaker-specific encoder and a style-specific encoder between the text encoder and the diffusion decoder. Thus, leveraging signal perturbation, U-Style is explicitly decomposed into speaker- and style-specific modeling parts, achieving better speaker and style disentanglement. To improve unseen speaker and style modeling ability, these two encoders conduct multi-level speaker and style modeling by skip-connected U-nets, incorporating the representation extraction and information reconstruction process. Besides, to improve the naturalness of synthetic speech, we adopt mean-based instance normalization and style adaptive layer normalization in these encoders to perform representation extraction and condition adaptation, respectively. Experiments show that U-Style significantly surpasses the state-of-the-art methods in unseen speaker cloning regarding naturalness and speaker similarity. Notably, U-Style can transfer the style from an unseen source speaker to another unseen target speaker, achieving flexible combinations of desired speaker timbre and style in zero-shot voice cloning.
AudioSR: Versatile Audio Super-resolution at Scale
Sep 13, 2023Audio super-resolution is a fundamental task that predicts high-frequency components for low-resolution audio, enhancing audio quality in digital applications. Previous methods have limitations such as the limited scope of audio types (e.g., music, speech) and specific bandwidth settings they can handle (e.g., 4kHz to 8kHz). In this paper, we introduce a diffusion-based generative model, AudioSR, that is capable of performing robust audio super-resolution on versatile audio types, including sound effects, music, and speech. Specifically, AudioSR can upsample any input audio signal within the bandwidth range of 2kHz to 16kHz to a high-resolution audio signal at 24kHz bandwidth with a sampling rate of 48kHz. Extensive objective evaluation on various audio super-resolution benchmarks demonstrates the strong result achieved by the proposed model. In addition, our subjective evaluation shows that AudioSR can acts as a plug-and-play module to enhance the generation quality of a wide range of audio generative models, including AudioLDM, Fastspeech2, and MusicGen. Our code and demo are available at https://audioldm.github.io/audiosr.
MSM-VC: High-fidelity Source Style Transfer for Non-Parallel Voice Conversion by Multi-scale Style Modeling
Sep 03, 2023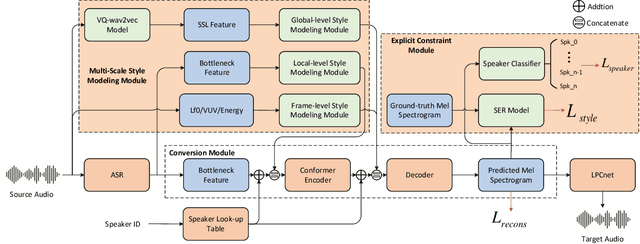



In addition to conveying the linguistic content from source speech to converted speech, maintaining the speaking style of source speech also plays an important role in the voice conversion (VC) task, which is essential in many scenarios with highly expressive source speech, such as dubbing and data augmentation. Previous work generally took explicit prosodic features or fixed-length style embedding extracted from source speech to model the speaking style of source speech, which is insufficient to achieve comprehensive style modeling and target speaker timbre preservation. Inspired by the style's multi-scale nature of human speech, a multi-scale style modeling method for the VC task, referred to as MSM-VC, is proposed in this paper. MSM-VC models the speaking style of source speech from different levels. To effectively convey the speaking style and meanwhile prevent timbre leakage from source speech to converted speech, each level's style is modeled by specific representation. Specifically, prosodic features, pre-trained ASR model's bottleneck features, and features extracted by a model trained with a self-supervised strategy are adopted to model the frame, local, and global-level styles, respectively. Besides, to balance the performance of source style modeling and target speaker timbre preservation, an explicit constraint module consisting of a pre-trained speech emotion recognition model and a speaker classifier is introduced to MSM-VC. This explicit constraint module also makes it possible to simulate the style transfer inference process during the training to improve the disentanglement ability and alleviate the mismatch between training and inference. Experiments performed on the highly expressive speech corpus demonstrate that MSM-VC is superior to the state-of-the-art VC methods for modeling source speech style while maintaining good speech quality and speaker similarity.
DiCLET-TTS: Diffusion Model based Cross-lingual Emotion Transfer for Text-to-Speech -- A Study between English and Mandarin
Sep 02, 2023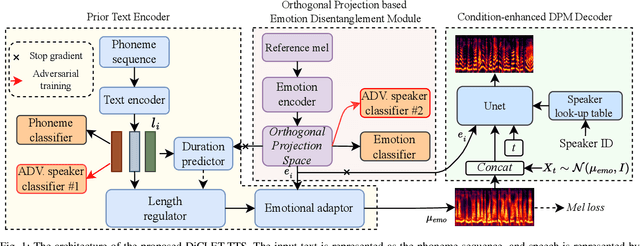
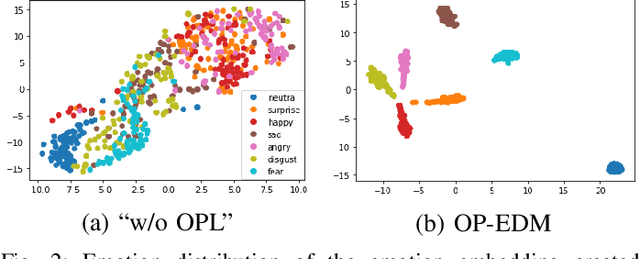
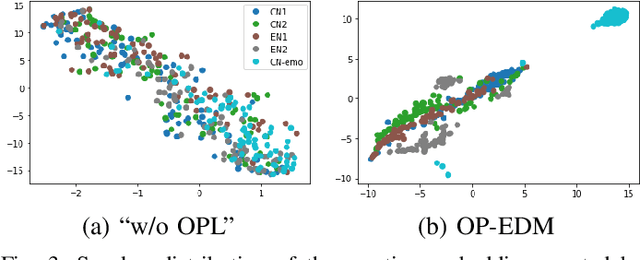
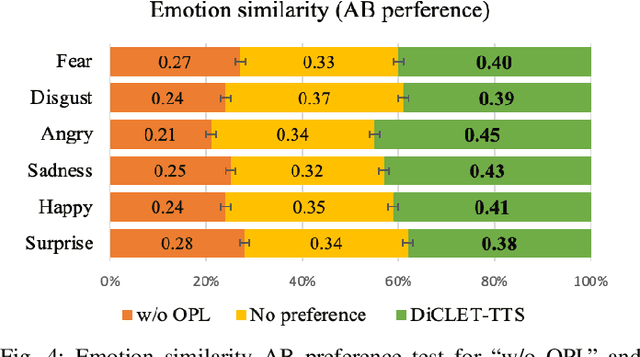
While the performance of cross-lingual TTS based on monolingual corpora has been significantly improved recently, generating cross-lingual speech still suffers from the foreign accent problem, leading to limited naturalness. Besides, current cross-lingual methods ignore modeling emotion, which is indispensable paralinguistic information in speech delivery. In this paper, we propose DiCLET-TTS, a Diffusion model based Cross-Lingual Emotion Transfer method that can transfer emotion from a source speaker to the intra- and cross-lingual target speakers. Specifically, to relieve the foreign accent problem while improving the emotion expressiveness, the terminal distribution of the forward diffusion process is parameterized into a speaker-irrelevant but emotion-related linguistic prior by a prior text encoder with the emotion embedding as a condition. To address the weaker emotional expressiveness problem caused by speaker disentanglement in emotion embedding, a novel orthogonal projection based emotion disentangling module (OP-EDM) is proposed to learn the speaker-irrelevant but emotion-discriminative embedding. Moreover, a condition-enhanced DPM decoder is introduced to strengthen the modeling ability of the speaker and the emotion in the reverse diffusion process to further improve emotion expressiveness in speech delivery. Cross-lingual emotion transfer experiments show the superiority of DiCLET-TTS over various competitive models and the good design of OP-EDM in learning speaker-irrelevant but emotion-discriminative embedding.
AudioLDM 2: Learning Holistic Audio Generation with Self-supervised Pretraining
Aug 10, 2023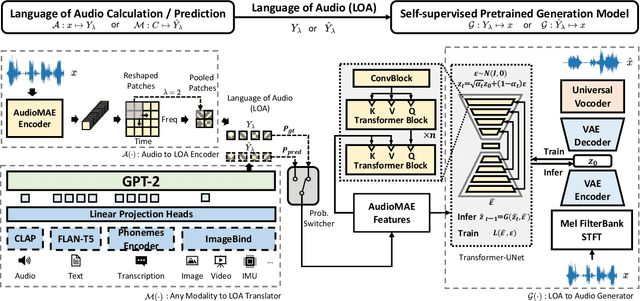
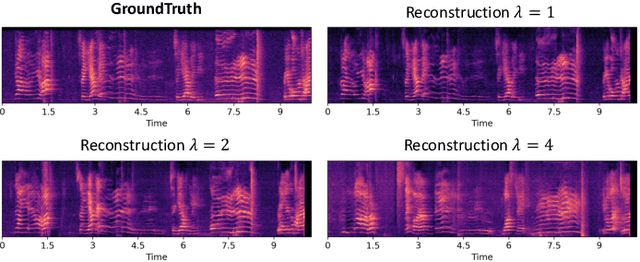
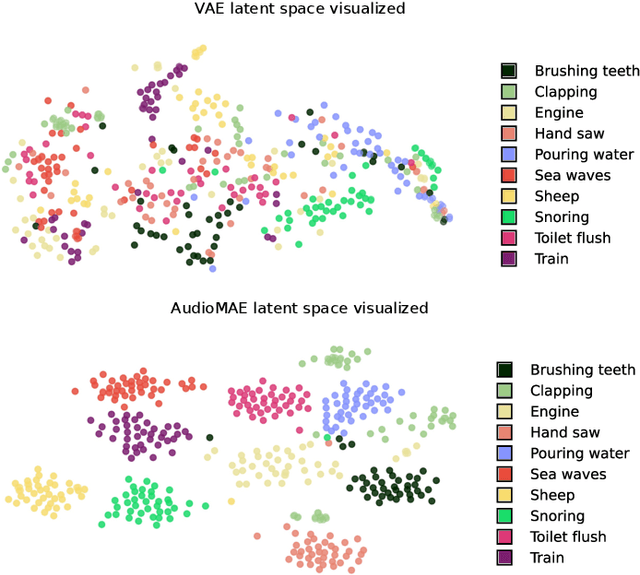
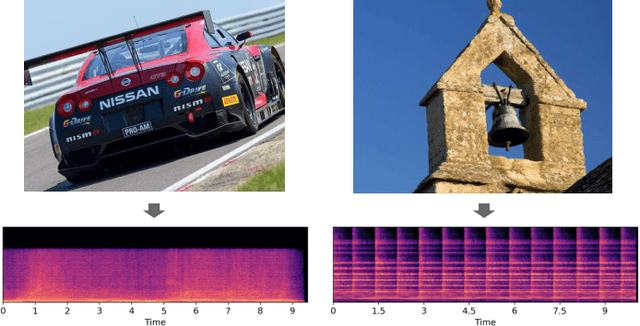
Although audio generation shares commonalities across different types of audio, such as speech, music, and sound effects, designing models for each type requires careful consideration of specific objectives and biases that can significantly differ from those of other types. To bring us closer to a unified perspective of audio generation, this paper proposes a framework that utilizes the same learning method for speech, music, and sound effect generation. Our framework introduces a general representation of audio, called language of audio (LOA). Any audio can be translated into LOA based on AudioMAE, a self-supervised pre-trained representation learning model. In the generation process, we translate any modalities into LOA by using a GPT-2 model, and we perform self-supervised audio generation learning with a latent diffusion model conditioned on LOA. The proposed framework naturally brings advantages such as in-context learning abilities and reusable self-supervised pretrained AudioMAE and latent diffusion models. Experiments on the major benchmarks of text-to-audio, text-to-music, and text-to-speech demonstrate new state-of-the-art or competitive performance to previous approaches. Our demo and code are available at https://audioldm.github.io/audioldm2.
LM-VC: Zero-shot Voice Conversion via Speech Generation based on Language Models
Jun 18, 2023Language model (LM) based audio generation frameworks, e.g., AudioLM, have recently achieved new state-of-the-art performance in zero-shot audio generation. In this paper, we explore the feasibility of LMs for zero-shot voice conversion. An intuitive approach is to follow AudioLM - Tokenizing speech into semantic and acoustic tokens respectively by HuBERT and SoundStream, and converting source semantic tokens to target acoustic tokens conditioned on acoustic tokens of the target speaker. However, such an approach encounters several issues: 1) the linguistic content contained in semantic tokens may get dispersed during multi-layer modeling while the lengthy speech input in the voice conversion task makes contextual learning even harder; 2) the semantic tokens still contain speaker-related information, which may be leaked to the target speech, lowering the target speaker similarity; 3) the generation diversity in the sampling of the LM can lead to unexpected outcomes during inference, leading to unnatural pronunciation and speech quality degradation. To mitigate these problems, we propose LM-VC, a two-stage language modeling approach that generates coarse acoustic tokens for recovering the source linguistic content and target speaker's timbre, and then reconstructs the fine for acoustic details as converted speech. Specifically, to enhance content preservation and facilitates better disentanglement, a masked prefix LM with a mask prediction strategy is used for coarse acoustic modeling. This model is encouraged to recover the masked content from the surrounding context and generate target speech based on the target speaker's utterance and corrupted semantic tokens. Besides, to further alleviate the sampling error in the generation, an external LM, which employs window attention to capture the local acoustic relations, is introduced to participate in the coarse acoustic modeling.
PolyVoice: Language Models for Speech to Speech Translation
Jun 13, 2023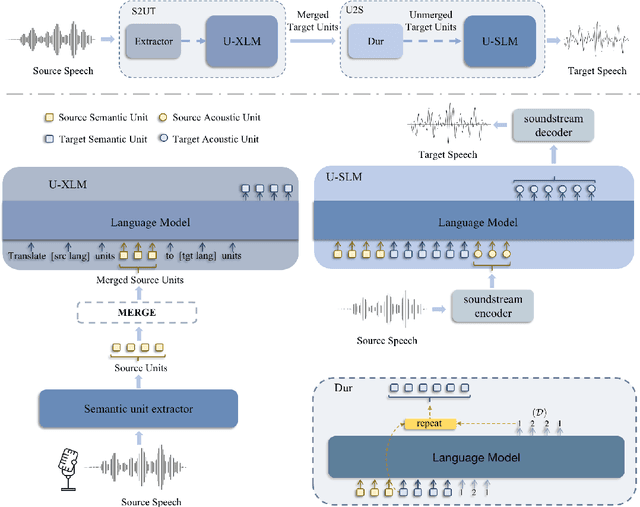

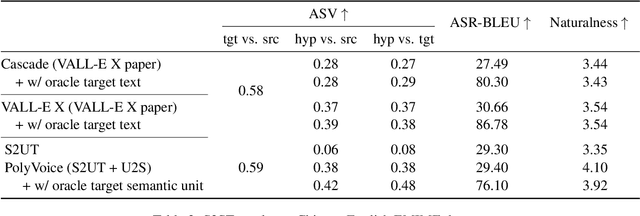
We propose PolyVoice, a language model-based framework for speech-to-speech translation (S2ST) system. Our framework consists of two language models: a translation language model and a speech synthesis language model. We use discretized speech units, which are generated in a fully unsupervised way, and thus our framework can be used for unwritten languages. For the speech synthesis part, we adopt the existing VALL-E X approach and build a unit-based audio language model. This grants our framework the ability to preserve the voice characteristics and the speaking style of the original speech. We examine our system on Chinese $\rightarrow$ English and English $\rightarrow$ Spanish pairs. Experimental results show that our system can generate speech with high translation quality and audio quality. Speech samples are available at https://speechtranslation.github.io/polyvoice.
Efficient Neural Music Generation
May 25, 2023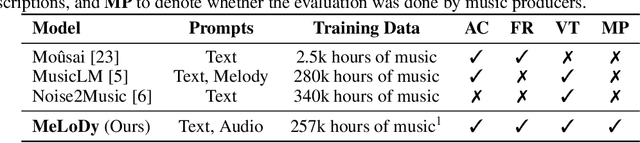
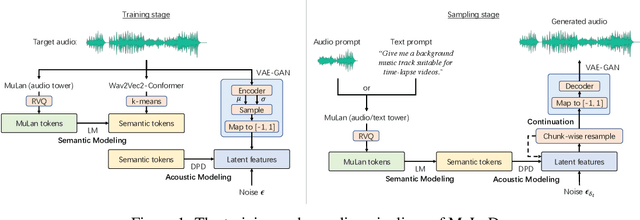
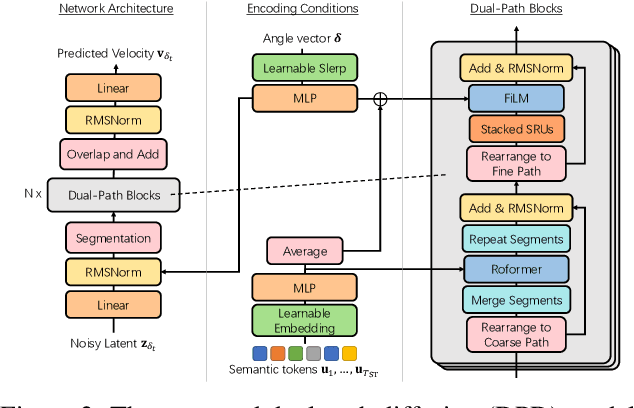

Recent progress in music generation has been remarkably advanced by the state-of-the-art MusicLM, which comprises a hierarchy of three LMs, respectively, for semantic, coarse acoustic, and fine acoustic modelings. Yet, sampling with the MusicLM requires processing through these LMs one by one to obtain the fine-grained acoustic tokens, making it computationally expensive and prohibitive for a real-time generation. Efficient music generation with a quality on par with MusicLM remains a significant challenge. In this paper, we present MeLoDy (M for music; L for LM; D for diffusion), an LM-guided diffusion model that generates music audios of state-of-the-art quality meanwhile reducing 95.7% or 99.6% forward passes in MusicLM, respectively, for sampling 10s or 30s music. MeLoDy inherits the highest-level LM from MusicLM for semantic modeling, and applies a novel dual-path diffusion (DPD) model and an audio VAE-GAN to efficiently decode the conditioning semantic tokens into waveform. DPD is proposed to simultaneously model the coarse and fine acoustics by incorporating the semantic information into segments of latents effectively via cross-attention at each denoising step. Our experimental results suggest the superiority of MeLoDy, not only in its practical advantages on sampling speed and infinitely continuable generation, but also in its state-of-the-art musicality, audio quality, and text correlation. Our samples are available at https://Efficient-MeLoDy.github.io/.
Multi-level Temporal-channel Speaker Retrieval for Robust Zero-shot Voice Conversion
May 12, 2023Zero-shot voice conversion (VC) converts source speech into the voice of any desired speaker using only one utterance of the speaker without requiring additional model updates. Typical methods use a speaker representation from a pre-trained speaker verification (SV) model or learn speaker representation during VC training to achieve zero-shot VC. However, existing speaker modeling methods overlook the variation of speaker information richness in temporal and frequency channel dimensions of speech. This insufficient speaker modeling hampers the ability of the VC model to accurately represent unseen speakers who are not in the training dataset. In this study, we present a robust zero-shot VC model with multi-level temporal-channel retrieval, referred to as MTCR-VC. Specifically, to flexibly adapt to the dynamic-variant speaker characteristic in the temporal and channel axis of the speech, we propose a novel fine-grained speaker modeling method, called temporal-channel retrieval (TCR), to find out when and where speaker information appears in speech. It retrieves variable-length speaker representation from both temporal and channel dimensions under the guidance of a pre-trained SV model. Besides, inspired by the hierarchical process of human speech production, the MTCR speaker module stacks several TCR blocks to extract speaker representations from multi-granularity levels. Furthermore, to achieve better speech disentanglement and reconstruction, we introduce a cycle-based training strategy to simulate zero-shot inference recurrently. We adopt perpetual constraints on three aspects, including content, style, and speaker, to drive this process. Experiments demonstrate that MTCR-VC is superior to the previous zero-shot VC methods in modeling speaker timbre while maintaining good speech naturalness.
Joint Multi-scale Cross-lingual Speaking Style Transfer with Bidirectional Attention Mechanism for Automatic Dubbing
May 09, 2023Automatic dubbing, which generates a corresponding version of the input speech in another language, could be widely utilized in many real-world scenarios such as video and game localization. In addition to synthesizing the translated scripts, automatic dubbing needs to further transfer the speaking style in the original language to the dubbed speeches to give audiences the impression that the characters are speaking in their native tongue. However, state-of-the-art automatic dubbing systems only model the transfer on duration and speaking rate, neglecting the other aspects in speaking style such as emotion, intonation and emphasis which are also crucial to fully perform the characters and speech understanding. In this paper, we propose a joint multi-scale cross-lingual speaking style transfer framework to simultaneously model the bidirectional speaking style transfer between languages at both global (i.e. utterance level) and local (i.e. word level) scales. The global and local speaking styles in each language are extracted and utilized to predicted the global and local speaking styles in the other language with an encoder-decoder framework for each direction and a shared bidirectional attention mechanism for both directions. A multi-scale speaking style enhanced FastSpeech 2 is then utilized to synthesize the predicted the global and local speaking styles to speech for each language. Experiment results demonstrate the effectiveness of our proposed framework, which outperforms a baseline with only duration transfer in both objective and subjective evaluations.