 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEgoAVU: Egocentric Audio-Visual Understanding
Feb 05, 2026Understanding egocentric videos plays a vital role for embodied intelligence. Recent multi-modal large language models (MLLMs) can accept both visual and audio inputs. However, due to the challenge of obtaining text labels with coherent joint-modality information, whether MLLMs can jointly understand both modalities in egocentric videos remains under-explored. To address this problem, we introduce EgoAVU, a scalable data engine to automatically generate egocentric audio-visual narrations, questions, and answers. EgoAVU enriches human narrations with multimodal context and generates audio-visual narrations through cross-modal correlation modeling. Token-based video filtering and modular, graph-based curation ensure both data diversity and quality. Leveraging EgoAVU, we construct EgoAVU-Instruct, a large-scale training dataset of 3M samples, and EgoAVU-Bench, a manually verified evaluation split covering diverse tasks. EgoAVU-Bench clearly reveals the limitations of existing MLLMs: they bias heavily toward visual signals, often neglecting audio cues or failing to correspond audio with the visual source. Finetuning MLLMs on EgoAVU-Instruct effectively addresses this issue, enabling up to 113% performance improvement on EgoAVU-Bench. Such benefits also transfer to other benchmarks such as EgoTempo and EgoIllusion, achieving up to 28% relative performance gain. Code will be released to the community.
SLAP: Scalable Language-Audio Pretraining with Variable-Duration Audio and Multi-Objective Training
Jan 18, 2026Contrastive language-audio pretraining (CLAP) has achieved notable success in learning semantically rich audio representations and is widely adopted for various audio-related tasks. However, current CLAP models face several key limitations. First, they are typically trained on relatively small datasets, often comprising a few million audio samples. Second, existing CLAP models are restricted to short and fixed duration, which constrains their usage in real-world scenarios with variable-duration audio. Third, the standard contrastive training objective operates on global representations, which may hinder the learning of dense, fine-grained audio features. To address these challenges, we introduce Scalable Language-Audio Pretraining (SLAP), which scales language-audio pretraining to 109 million audio-text pairs with variable audio durations and incorporates multiple training objectives. SLAP unifies contrastive loss with additional self-supervised and captioning losses in a single-stage training, facilitating the learning of richer dense audio representations. The proposed SLAP model achieves new state-of-the-art performance on audio-text retrieval and zero-shot audio classification tasks, demonstrating its effectiveness across diverse benchmarks.
First-Shot Unsupervised Anomalous Sound Detection With Unknown Anomalies Estimated by Metadata-Assisted Audio Generation
Oct 22, 2023



First-shot (FS) unsupervised anomalous sound detection (ASD) is a brand-new task introduced in DCASE 2023 Challenge Task 2, where the anomalous sounds for the target machine types are unseen in training. Existing methods often rely on the availability of normal and abnormal sound data from the target machines. However, due to the lack of anomalous sound data for the target machine types, it becomes challenging when adapting the existing ASD methods to the first-shot task. In this paper, we propose a new framework for the first-shot unsupervised ASD, where metadata-assisted audio generation is used to estimate unknown anomalies, by utilising the available machine information (i.e., metadata and sound data) to fine-tune a text-to-audio generation model for generating the anomalous sounds that contain unique acoustic characteristics accounting for each different machine types. We then use the method of Time-Weighted Frequency domain audio Representation with Gaussian Mixture Model (TWFR-GMM) as the backbone to achieve the first-shot unsupervised ASD. Our proposed FS-TWFR-GMM method achieves competitive performance amongst top systems in DCASE 2023 Challenge Task 2, while requiring only 1% model parameters for detection, as validated in our experiments.
FoleyGen: Visually-Guided Audio Generation
Sep 19, 2023Recent advancements in audio generation have been spurred by the evolution of large-scale deep learning models and expansive datasets. However, the task of video-to-audio (V2A) generation continues to be a challenge, principally because of the intricate relationship between the high-dimensional visual and auditory data, and the challenges associated with temporal synchronization. In this study, we introduce FoleyGen, an open-domain V2A generation system built on a language modeling paradigm. FoleyGen leverages an off-the-shelf neural audio codec for bidirectional conversion between waveforms and discrete tokens. The generation of audio tokens is facilitated by a single Transformer model, which is conditioned on visual features extracted from a visual encoder. A prevalent problem in V2A generation is the misalignment of generated audio with the visible actions in the video. To address this, we explore three novel visual attention mechanisms. We further undertake an exhaustive evaluation of multiple visual encoders, each pretrained on either single-modal or multi-modal tasks. The experimental results on VGGSound dataset show that our proposed FoleyGen outperforms previous systems across all objective metrics and human evaluations.
Enhance audio generation controllability through representation similarity regularization
Sep 15, 2023



This paper presents an innovative approach to enhance control over audio generation by emphasizing the alignment between audio and text representations during model training. In the context of language model-based audio generation, the model leverages input from both textual and audio token representations to predict subsequent audio tokens. However, the current configuration lacks explicit regularization to ensure the alignment between the chosen text representation and the language model's predictions. Our proposal involves the incorporation of audio and text representation regularization, particularly during the classifier-free guidance (CFG) phase, where the text condition is excluded from cross attention during language model training. The aim of this proposed representation regularization is to minimize discrepancies in audio and text similarity compared to other samples within the same training batch. Experimental results on both music and audio generation tasks demonstrate that our proposed methods lead to improvements in objective metrics for both audio and music generation, as well as an enhancement in the human perception for audio generation.
AudioLDM 2: Learning Holistic Audio Generation with Self-supervised Pretraining
Aug 10, 2023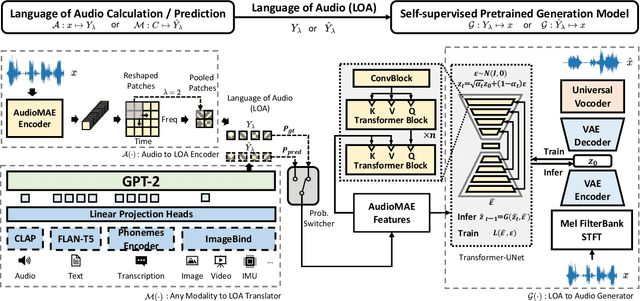
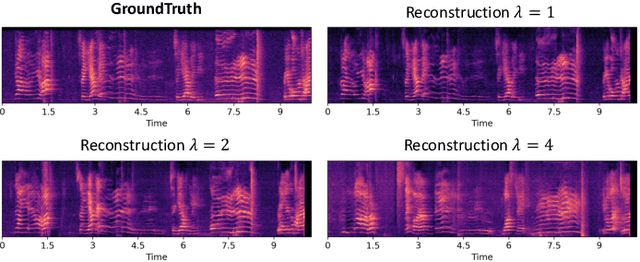
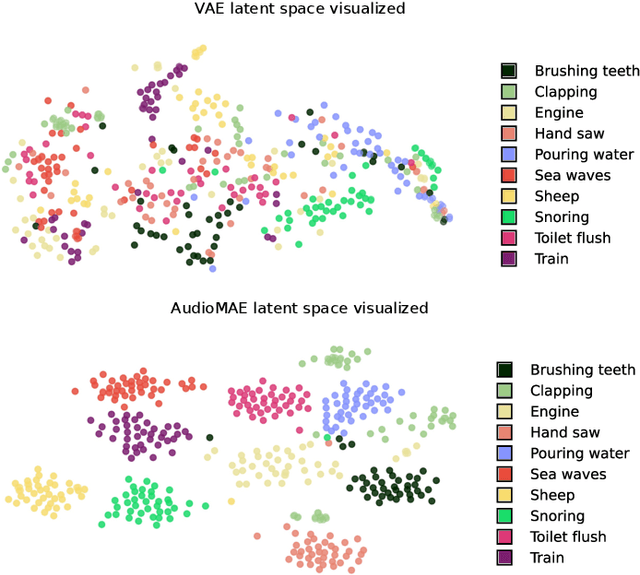
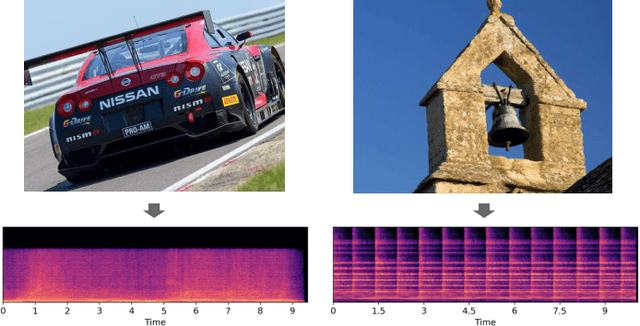
Although audio generation shares commonalities across different types of audio, such as speech, music, and sound effects, designing models for each type requires careful consideration of specific objectives and biases that can significantly differ from those of other types. To bring us closer to a unified perspective of audio generation, this paper proposes a framework that utilizes the same learning method for speech, music, and sound effect generation. Our framework introduces a general representation of audio, called language of audio (LOA). Any audio can be translated into LOA based on AudioMAE, a self-supervised pre-trained representation learning model. In the generation process, we translate any modalities into LOA by using a GPT-2 model, and we perform self-supervised audio generation learning with a latent diffusion model conditioned on LOA. The proposed framework naturally brings advantages such as in-context learning abilities and reusable self-supervised pretrained AudioMAE and latent diffusion models. Experiments on the major benchmarks of text-to-audio, text-to-music, and text-to-speech demonstrate new state-of-the-art or competitive performance to previous approaches. Our demo and code are available at https://audioldm.github.io/audioldm2.
Dual Transformer Decoder based Features Fusion Network for Automated Audio Captioning
May 30, 2023Automated audio captioning (AAC) which generates textual descriptions of audio content. Existing AAC models achieve good results but only use the high-dimensional representation of the encoder. There is always insufficient information learning of high-dimensional methods owing to high-dimensional representations having a large amount of information. In this paper, a new encoder-decoder model called the Low- and High-Dimensional Feature Fusion (LHDFF) is proposed. LHDFF uses a new PANNs encoder called Residual PANNs (RPANNs) to fuse low- and high-dimensional features. Low-dimensional features contain limited information about specific audio scenes. The fusion of low- and high-dimensional features can improve model performance by repeatedly emphasizing specific audio scene information. To fully exploit the fused features, LHDFF uses a dual transformer decoder structure to generate captions in parallel. Experimental results show that LHDFF outperforms existing audio captioning models.
WavCaps: A ChatGPT-Assisted Weakly-Labelled Audio Captioning Dataset for Audio-Language Multimodal Research
Mar 30, 2023



The advancement of audio-language (AL) multimodal learning tasks has been significant in recent years. However, researchers face challenges due to the costly and time-consuming collection process of existing audio-language datasets, which are limited in size. To address this data scarcity issue, we introduce WavCaps, the first large-scale weakly-labelled audio captioning dataset, comprising approximately 400k audio clips with paired captions. We sourced audio clips and their raw descriptions from web sources and a sound event detection dataset. However, the online-harvested raw descriptions are highly noisy and unsuitable for direct use in tasks such as automated audio captioning. To overcome this issue, we propose a three-stage processing pipeline for filtering noisy data and generating high-quality captions, where ChatGPT, a large language model, is leveraged to filter and transform raw descriptions automatically. We conduct a comprehensive analysis of the characteristics of WavCaps dataset and evaluate it on multiple downstream audio-language multimodal learning tasks. The systems trained on WavCaps outperform previous state-of-the-art (SOTA) models by a significant margin. Our aspiration is for the WavCaps dataset we have proposed to facilitate research in audio-language multimodal learning and demonstrate the potential of utilizing ChatGPT to enhance academic research. Our dataset and codes are available at https://github.com/XinhaoMei/WavCaps.
AudioLDM: Text-to-Audio Generation with Latent Diffusion Models
Feb 16, 2023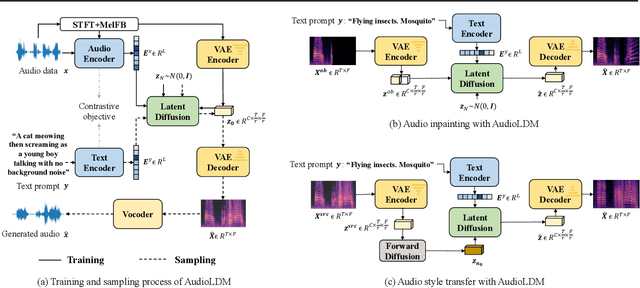
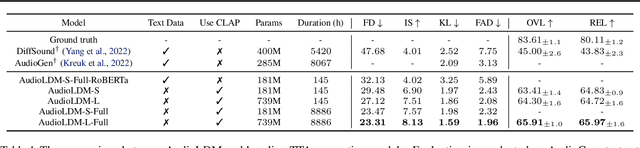
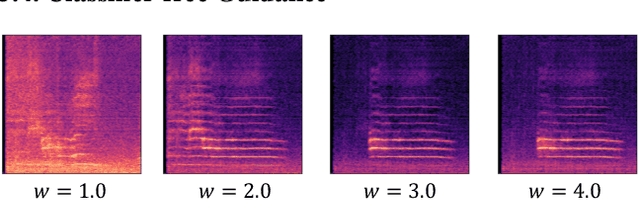
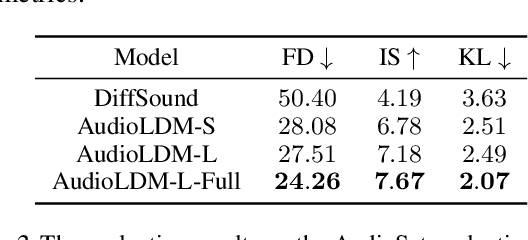
Text-to-audio (TTA) system has recently gained attention for its ability to synthesize general audio based on text descriptions. However, previous studies in TTA have limited generation quality with high computational costs. In this study, we propose AudioLDM, a TTA system that is built on a latent space to learn the continuous audio representations from contrastive language-audio pretraining (CLAP) latents. The pretrained CLAP models enable us to train LDMs with audio embedding while providing text embedding as a condition during sampling. By learning the latent representations of audio signals and their compositions without modeling the cross-modal relationship, AudioLDM is advantageous in both generation quality and computational efficiency. Trained on AudioCaps with a single GPU, AudioLDM achieves state-of-the-art TTA performance measured by both objective and subjective metrics (e.g., frechet distance). Moreover, AudioLDM is the first TTA system that enables various text-guided audio manipulations (e.g., style transfer) in a zero-shot fashion. Our implementation and demos are available at https://audioldm.github.io.
Towards Generating Diverse Audio Captions via Adversarial Training
Dec 05, 2022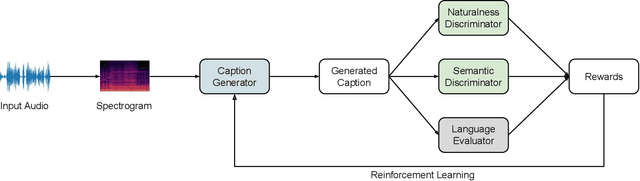
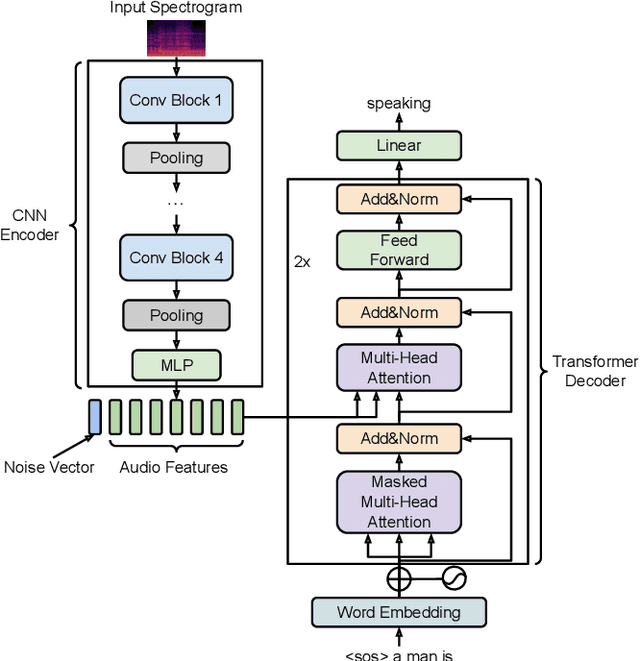
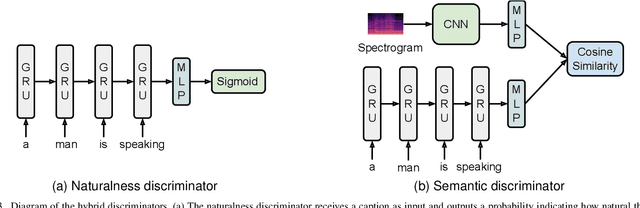
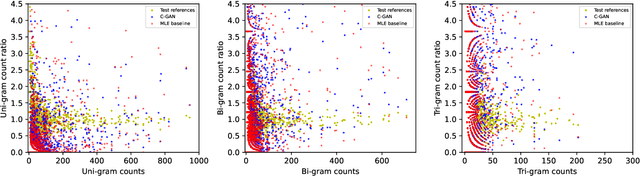
Automated audio captioning is a cross-modal translation task for describing the content of audio clips with natural language sentences. This task has attracted increasing attention and substantial progress has been made in recent years. Captions generated by existing models are generally faithful to the content of audio clips, however, these machine-generated captions are often deterministic (e.g., generating a fixed caption for a given audio clip), simple (e.g., using common words and simple grammar), and generic (e.g., generating the same caption for similar audio clips). When people are asked to describe the content of an audio clip, different people tend to focus on different sound events and describe an audio clip diversely from various aspects using distinct words and grammar. We believe that an audio captioning system should have the ability to generate diverse captions, either for a fixed audio clip, or across similar audio clips. To this end, we propose an adversarial training framework based on a conditional generative adversarial network (C-GAN) to improve diversity of audio captioning systems. A caption generator and two hybrid discriminators compete and are learned jointly, where the caption generator can be any standard encoder-decoder captioning model used to generate captions, and the hybrid discriminators assess the generated captions from different criteria, such as their naturalness and semantics. We conduct experiments on the Clotho dataset. The results show that our proposed model can generate captions with better diversity as compared to state-of-the-art methods.