 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe ML-SUPERB 2.0 Challenge: Towards Inclusive ASR Benchmarking for All Language Varieties
Sep 08, 2025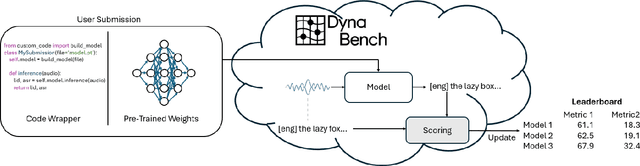
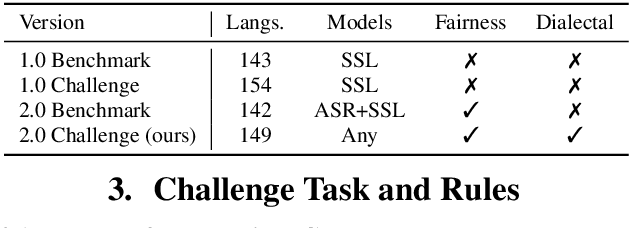
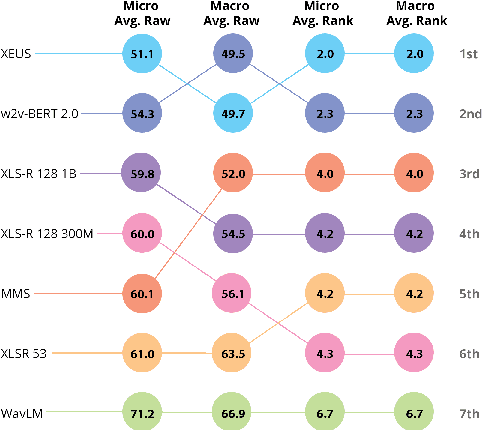
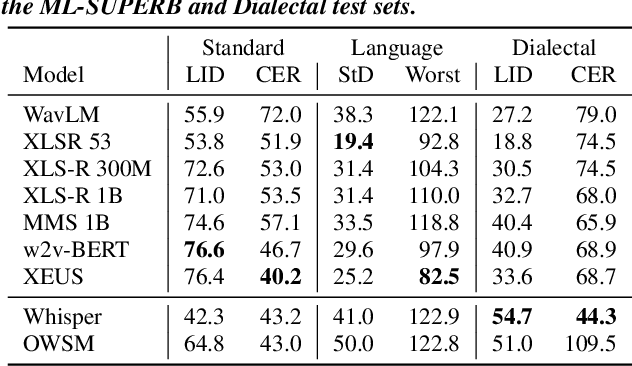
Recent improvements in multilingual ASR have not been equally distributed across languages and language varieties. To advance state-of-the-art (SOTA) ASR models, we present the Interspeech 2025 ML-SUPERB 2.0 Challenge. We construct a new test suite that consists of data from 200+ languages, accents, and dialects to evaluate SOTA multilingual speech models. The challenge also introduces an online evaluation server based on DynaBench, allowing for flexibility in model design and architecture for participants. The challenge received 5 submissions from 3 teams, all of which outperformed our baselines. The best-performing submission achieved an absolute improvement in LID accuracy of 23% and a reduction in CER of 18% when compared to the best baseline on a general multilingual test set. On accented and dialectal data, the best submission obtained 30.2% lower CER and 15.7% higher LID accuracy, showing the importance of community challenges in making speech technologies more inclusive.
GMU Systems for the IWSLT 2025 Low-Resource Speech Translation Shared Task
May 27, 2025This paper describes the GMU systems for the IWSLT 2025 low-resource speech translation shared task. We trained systems for all language pairs, except for Levantine Arabic. We fine-tuned SeamlessM4T-v2 for automatic speech recognition (ASR), machine translation (MT), and end-to-end speech translation (E2E ST). The ASR and MT models are also used to form cascaded ST systems. Additionally, we explored various training paradigms for E2E ST fine-tuning, including direct E2E fine-tuning, multi-task training, and parameter initialization using components from fine-tuned ASR and/or MT models. Our results show that (1) direct E2E fine-tuning yields strong results; (2) initializing with a fine-tuned ASR encoder improves ST performance on languages SeamlessM4T-v2 has not been trained on; (3) multi-task training can be slightly helpful.
RepCodec: A Speech Representation Codec for Speech Tokenization
Aug 31, 2023



With recent rapid growth of large language models (LLMs), discrete speech tokenization has played an important role for injecting speech into LLMs. However, this discretization gives rise to a loss of information, consequently impairing overall performance. To improve the performance of these discrete speech tokens, we present RepCodec, a novel speech representation codec for semantic speech tokenization. In contrast to audio codecs which reconstruct the raw audio, RepCodec learns a vector quantization codebook through reconstructing speech representations from speech encoders like HuBERT or data2vec. Together, the speech encoder, the codec encoder and the vector quantization codebook form a pipeline for converting speech waveforms into semantic tokens. The extensive experiments illustrate that RepCodec, by virtue of its enhanced information retention capacity, significantly outperforms the widely used k-means clustering approach in both speech understanding and generation. Furthermore, this superiority extends across various speech encoders and languages, affirming the robustness of RepCodec. We believe our method can facilitate large language modeling research on speech processing.
WavCaps: A ChatGPT-Assisted Weakly-Labelled Audio Captioning Dataset for Audio-Language Multimodal Research
Mar 30, 2023



The advancement of audio-language (AL) multimodal learning tasks has been significant in recent years. However, researchers face challenges due to the costly and time-consuming collection process of existing audio-language datasets, which are limited in size. To address this data scarcity issue, we introduce WavCaps, the first large-scale weakly-labelled audio captioning dataset, comprising approximately 400k audio clips with paired captions. We sourced audio clips and their raw descriptions from web sources and a sound event detection dataset. However, the online-harvested raw descriptions are highly noisy and unsuitable for direct use in tasks such as automated audio captioning. To overcome this issue, we propose a three-stage processing pipeline for filtering noisy data and generating high-quality captions, where ChatGPT, a large language model, is leveraged to filter and transform raw descriptions automatically. We conduct a comprehensive analysis of the characteristics of WavCaps dataset and evaluate it on multiple downstream audio-language multimodal learning tasks. The systems trained on WavCaps outperform previous state-of-the-art (SOTA) models by a significant margin. Our aspiration is for the WavCaps dataset we have proposed to facilitate research in audio-language multimodal learning and demonstrate the potential of utilizing ChatGPT to enhance academic research. Our dataset and codes are available at https://github.com/XinhaoMei/WavCaps.
CoBERT: Self-Supervised Speech Representation Learning Through Code Representation Learning
Oct 08, 2022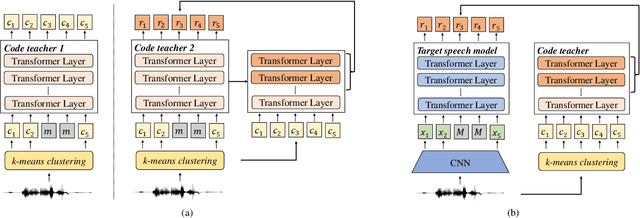
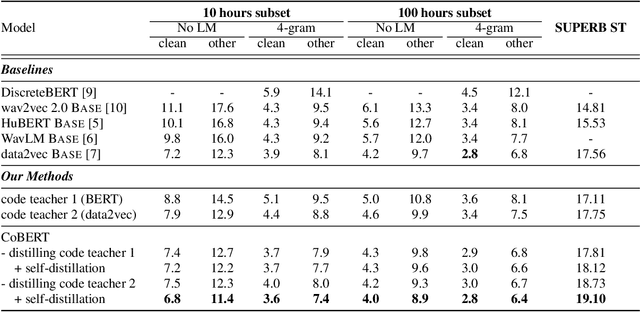
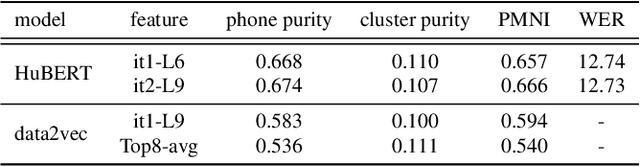
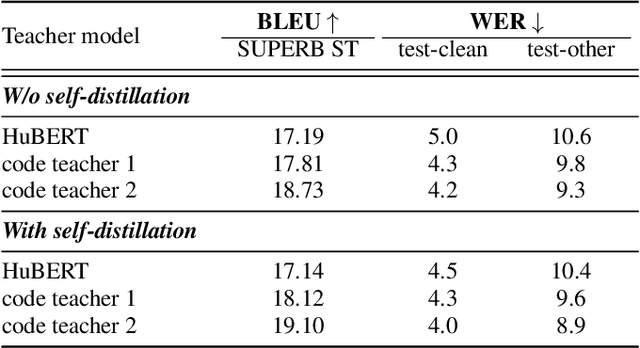
Speech is the surface form of a finite set of phonetic units, which can be represented by discrete codes. We propose the Code BERT (CoBERT) approach for self-supervised speech representation learning. The idea is to convert an utterance to a sequence of discrete codes, and perform code representation learning, where we predict the code representations based on a masked view of the original speech input. Unlike the prior self-distillation approaches of which the teacher and the student are of the same modality, our target model predicts representations from a different modality. CoBERT outperforms the most recent state-of-the-art performance on the ASR task and brings significant improvements on the SUPERB speech translation (ST) task.
GigaST: A 10,000-hour Pseudo Speech Translation Corpus
Apr 08, 2022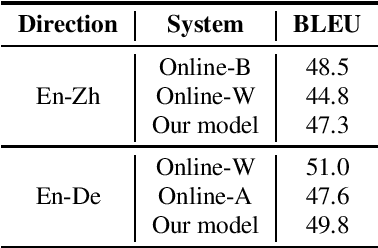
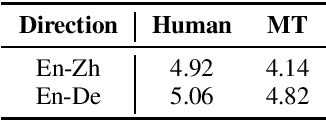
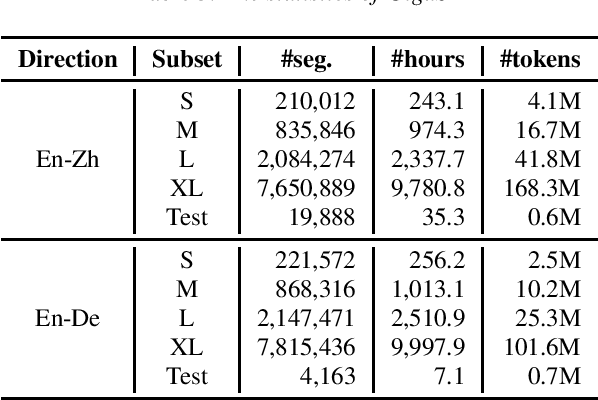
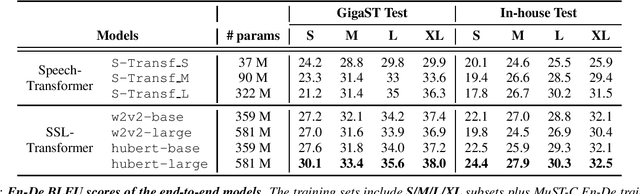
This paper introduces GigaST, a large-scale pseudo speech translation (ST) corpus. We create the corpus by translating the text in GigaSpeech, an English ASR corpus, into German and Chinese. The training set is translated by a strong machine translation system and the test set is translated by human. ST models trained with an addition of our corpus obtain new state-of-the-art results on the MuST-C English-German benchmark test set. We provide a detailed description of the translation process and verify its quality. We make the translated text data public and hope to facilitate research in speech translation. Additionally, we also release the training scripts on NeurST to make it easy to replicate our systems. GigaST dataset is available at https://st-benchmark.github.io/resources/GigaST.