 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAudioLDM: Text-to-Audio Generation with Latent Diffusion Models
Paper and Code
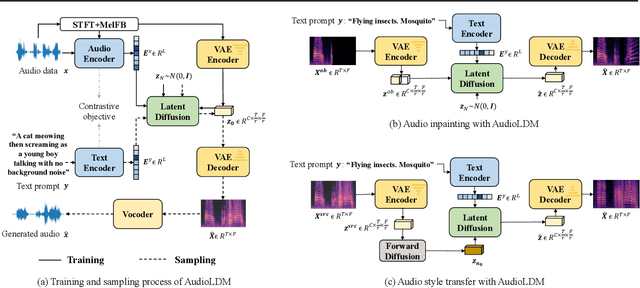
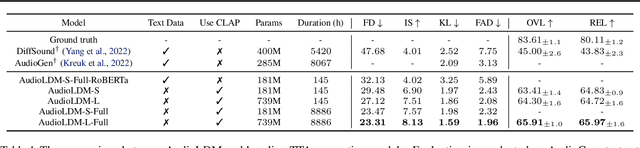
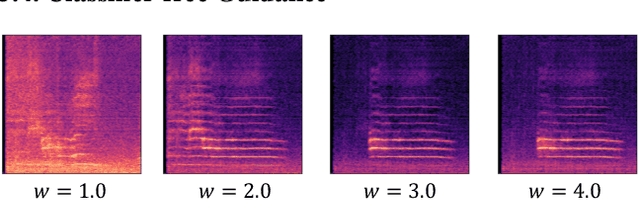
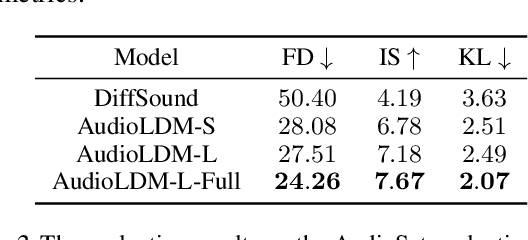
Text-to-audio (TTA) system has recently gained attention for its ability to synthesize general audio based on text descriptions. However, previous studies in TTA have limited generation quality with high computational costs. In this study, we propose AudioLDM, a TTA system that is built on a latent space to learn the continuous audio representations from contrastive language-audio pretraining (CLAP) latents. The pretrained CLAP models enable us to train LDMs with audio embedding while providing text embedding as a condition during sampling. By learning the latent representations of audio signals and their compositions without modeling the cross-modal relationship, AudioLDM is advantageous in both generation quality and computational efficiency. Trained on AudioCaps with a single GPU, AudioLDM achieves state-of-the-art TTA performance measured by both objective and subjective metrics (e.g., frechet distance). Moreover, AudioLDM is the first TTA system that enables various text-guided audio manipulations (e.g., style transfer) in a zero-shot fashion. Our implementation and demos are available at https://audioldm.github.io.