 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKnowledge Distillation for Efficient Audio-Visual Video Captioning
Jun 16, 2023


Automatically describing audio-visual content with texts, namely video captioning, has received significant attention due to its potential applications across diverse fields. Deep neural networks are the dominant methods, offering state-of-the-art performance. However, these methods are often undeployable in low-power devices like smartphones due to the large size of the model parameters. In this paper, we propose to exploit simple pooling front-end and down-sampling algorithms with knowledge distillation for audio and visual attributes using a reduced number of audio-visual frames. With the help of knowledge distillation from the teacher model, our proposed method greatly reduces the redundant information in audio-visual streams without losing critical contexts for caption generation. Extensive experimental evaluations on the MSR-VTT dataset demonstrate that our proposed approach significantly reduces the inference time by about 80% with a small sacrifice (less than 0.02%) in captioning accuracy.
Dual Transformer Decoder based Features Fusion Network for Automated Audio Captioning
May 30, 2023Automated audio captioning (AAC) which generates textual descriptions of audio content. Existing AAC models achieve good results but only use the high-dimensional representation of the encoder. There is always insufficient information learning of high-dimensional methods owing to high-dimensional representations having a large amount of information. In this paper, a new encoder-decoder model called the Low- and High-Dimensional Feature Fusion (LHDFF) is proposed. LHDFF uses a new PANNs encoder called Residual PANNs (RPANNs) to fuse low- and high-dimensional features. Low-dimensional features contain limited information about specific audio scenes. The fusion of low- and high-dimensional features can improve model performance by repeatedly emphasizing specific audio scene information. To fully exploit the fused features, LHDFF uses a dual transformer decoder structure to generate captions in parallel. Experimental results show that LHDFF outperforms existing audio captioning models.
Visually-Aware Audio Captioning With Adaptive Audio-Visual Attention
Oct 28, 2022Audio captioning is the task of generating captions that describe the content of audio clips. In the real world, many objects produce similar sounds. It is difficult to identify these auditory ambiguous sound events with access to audio information only. How to accurately recognize ambiguous sounds is a major challenge for audio captioning systems. In this work, inspired by the audio-visual multi-modal perception of human beings, we propose visually-aware audio captioning, which makes use of visual information to help the recognition of ambiguous sounding objects. Specifically, we introduce an off-the-shelf visual encoder to process the video inputs, and incorporate the extracted visual features into an audio captioning system. Furthermore, to better exploit complementary contexts from redundant audio-visual streams, we propose an audio-visual attention mechanism that integrates audio and visual information adaptively according to their confidence levels. Experimental results on AudioCaps, the largest publicly available audio captioning dataset, show that the proposed method achieves significant improvement over a strong baseline audio captioning system and is on par with the state-of-the-art result.
Leveraging Pre-trained BERT for Audio Captioning
Mar 27, 2022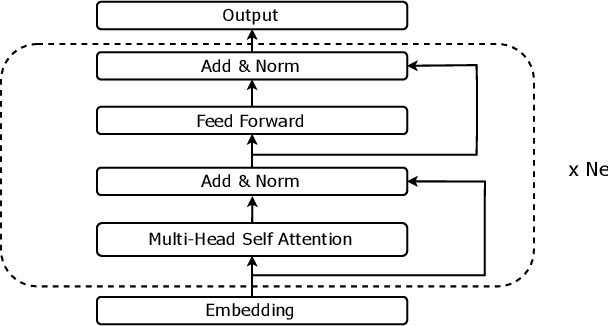
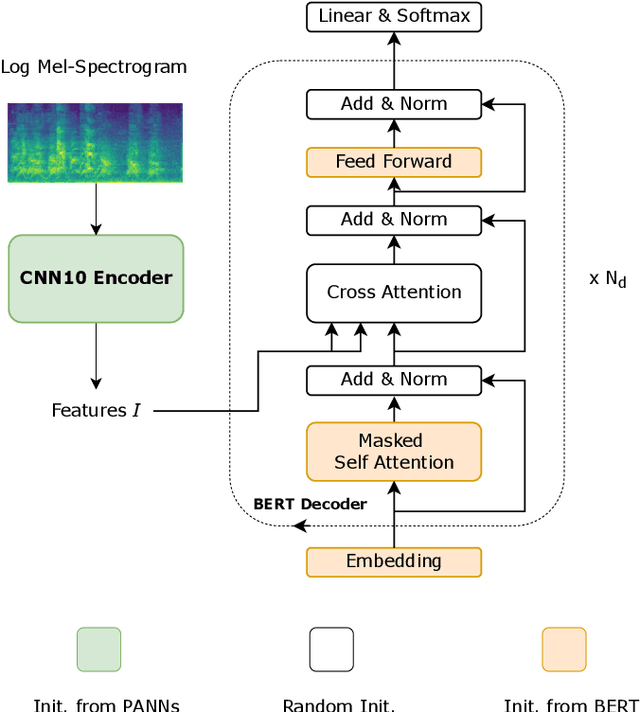
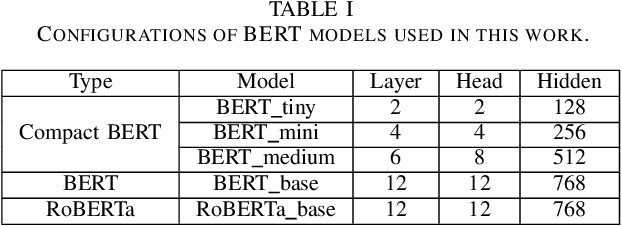
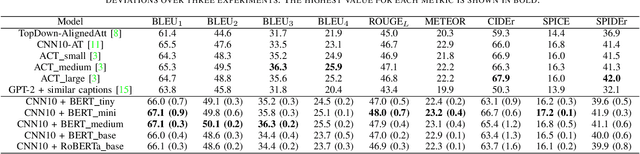
Audio captioning aims at using natural language to describe the content of an audio clip. Existing audio captioning systems are generally based on an encoder-decoder architecture, in which acoustic information is extracted by an audio encoder and then a language decoder is used to generate the captions. Training an audio captioning system often encounters the problem of data scarcity. Transferring knowledge from pre-trained audio models such as Pre-trained Audio Neural Networks (PANNs) have recently emerged as a useful method to mitigate this issue. However, there is less attention on exploiting pre-trained language models for the decoder, compared with the encoder. BERT is a pre-trained language model that has been extensively used in Natural Language Processing (NLP) tasks. Nevertheless, the potential of BERT as the language decoder for audio captioning has not been investigated. In this study, we demonstrate the efficacy of the pre-trained BERT model for audio captioning. Specifically, we apply PANNs as the encoder and initialize the decoder from the public pre-trained BERT models. We conduct an empirical study on the use of these BERT models for the decoder in the audio captioning model. Our models achieve competitive results with the existing audio captioning methods on the AudioCaps dataset.
Deep Neural Decision Forest for Acoustic Scene Classification
Mar 07, 2022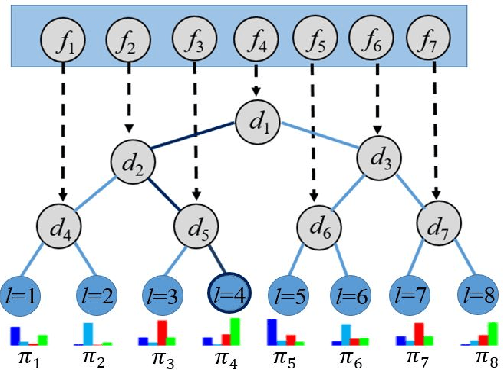
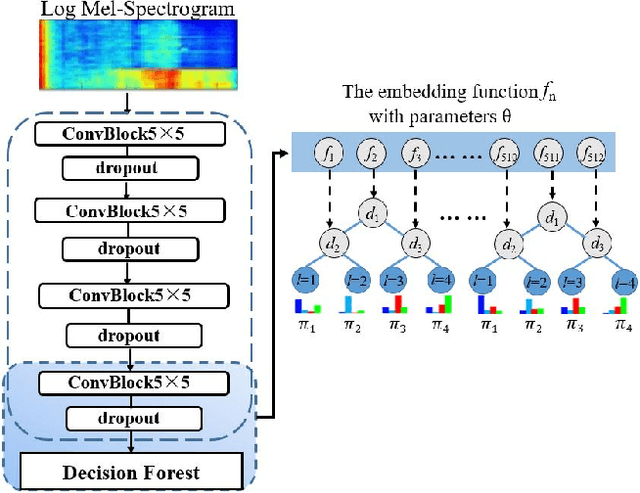

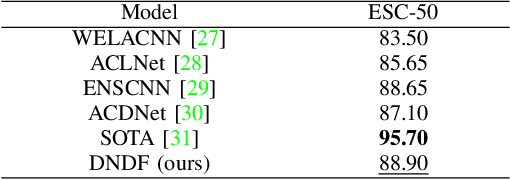
Acoustic scene classification (ASC) aims to classify an audio clip based on the characteristic of the recording environment. In this regard, deep learning based approaches have emerged as a useful tool for ASC problems. Conventional approaches to improving the classification accuracy include integrating auxiliary methods such as attention mechanism, pre-trained models and ensemble multiple sub-networks. However, due to the complexity of audio clips captured from different environments, it is difficult to distinguish their categories without using any auxiliary methods for existing deep learning models using only a single classifier. In this paper, we propose a novel approach for ASC using deep neural decision forest (DNDF). DNDF combines a fixed number of convolutional layers and a decision forest as the final classifier. The decision forest consists of a fixed number of decision tree classifiers, which have been shown to offer better classification performance than a single classifier in some datasets. In particular, the decision forest differs substantially from traditional random forests as it is stochastic, differentiable, and capable of using the back-propagation to update and learn feature representations in neural network. Experimental results on the DCASE2019 and ESC-50 datasets demonstrate that our proposed DNDF method improves the ASC performance in terms of classification accuracy and shows competitive performance as compared with state-of-the-art baselines.
Smartphone Based Colorimetric Detection via Machine Learning
Mar 17, 2017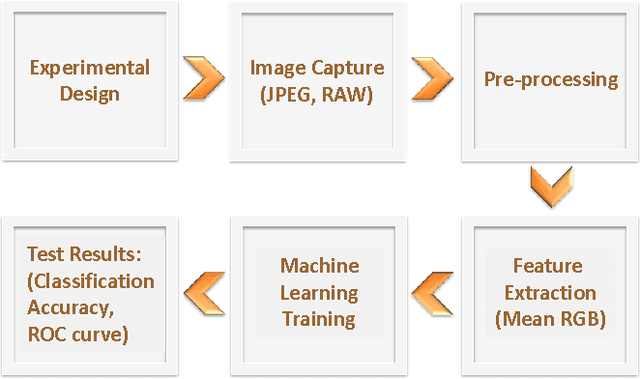
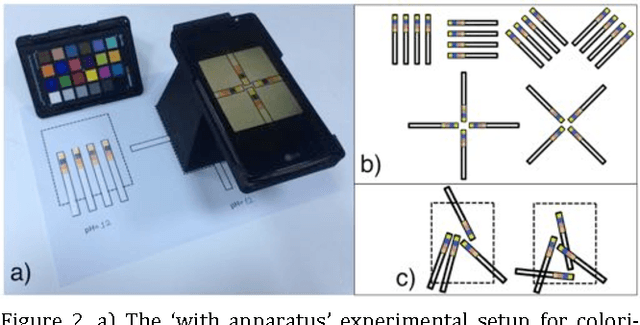

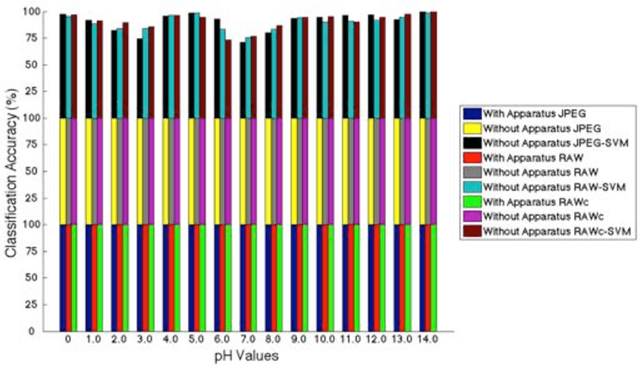
We report the application of machine learning to smartphone based colorimetric detection of pH values. The strip images were used as the training set for Least Squares-Support Vector Machine (LS-SVM) classifier algorithms that were able to successfully classify the distinct pH values. The difference in the obtained image formats was found not to significantly affect the performance of the proposed machine learning approach. Moreover, the influence of the illumination conditions on the perceived color of pH strips was investigated and further experiments were carried out to study effect of color change on the learning model. Test results on JPEG, RAW and RAW-corrected image formats captured in different lighting conditions lead to perfect classification accuracy, sensitivity and specificity, which proves that the colorimetric detection using machine learning based systems is able to adapt to various experimental conditions and is a great candidate for smartphone based sensing in paper-based colorimetric assays.