 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLinear Reasoning vs. Proof by Cases: Obstacles for Large Language Models in FOL Problem Solving
Feb 24, 2026To comprehensively evaluate the mathematical reasoning capabilities of Large Language Models (LLMs), researchers have introduced abundant mathematical reasoning datasets. However, most existing datasets primarily focus on linear reasoning, neglecting other parts such as proof by contradiction and proof by cases, which are crucial for investigating LLMs' reasoning abilities. To address this limitation, we first introduce a novel first-order logic (FOL) dataset named PC-FOL, annotated by professional mathematicians, focusing on case-based reasoning problems. All instances in this dataset are equipped with a manually written natural language proof, clearly distinguishing it from conventional linear reasoning datasets. Our experimental results over leading LLMs demonstrate a substantial performance gap between linear reasoning and case-based reasoning problems. To further investigate this phenomenon, we provide a theoretical analysis grounded in graphical model, which provides an explanation for the observed disparity between the two types of reasoning problems. We hope this work can reveal the core challenges in the field of automated natural language mathematical proof generation, paving the way for future research.
GenDec: A robust generative Question-decomposition method for Multi-hop reasoning
Feb 17, 2024Multi-hop QA (MHQA) involves step-by-step reasoning to answer complex questions and find multiple relevant supporting facts. However, Existing large language models'(LLMs) reasoning ability in multi-hop question answering remains exploration, which is inadequate in answering multi-hop questions. Moreover, it is unclear whether LLMs follow a desired reasoning chain to reach the right final answer. In this paper, we propose a \textbf{gen}erative question \textbf{dec}omposition method (GenDec) from the perspective of explainable QA by generating independent and complete sub-questions based on incorporating additional extracted evidence for enhancing LLMs' reasoning ability in RAG. To demonstrate the impact, generalization, and robustness of Gendec, we conduct two experiments, the first is combining GenDec with small QA systems on paragraph retrieval and QA tasks. We secondly examine the reasoning capabilities of various state-of-the-art LLMs including GPT-4 and GPT-3.5 combined with GenDec. We experiment on the HotpotQA, 2WikihopMultiHopQA, MuSiQue, and PokeMQA datasets.
Efficient Neural Music Generation
May 25, 2023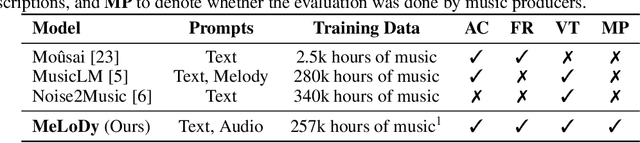
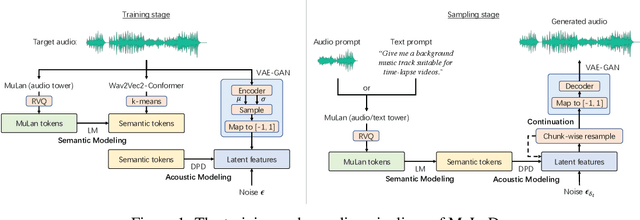
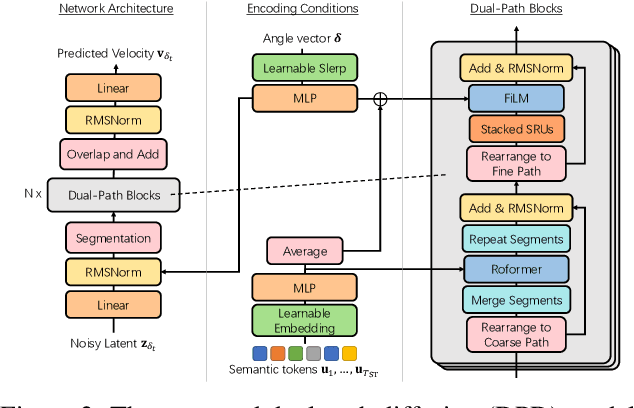

Recent progress in music generation has been remarkably advanced by the state-of-the-art MusicLM, which comprises a hierarchy of three LMs, respectively, for semantic, coarse acoustic, and fine acoustic modelings. Yet, sampling with the MusicLM requires processing through these LMs one by one to obtain the fine-grained acoustic tokens, making it computationally expensive and prohibitive for a real-time generation. Efficient music generation with a quality on par with MusicLM remains a significant challenge. In this paper, we present MeLoDy (M for music; L for LM; D for diffusion), an LM-guided diffusion model that generates music audios of state-of-the-art quality meanwhile reducing 95.7% or 99.6% forward passes in MusicLM, respectively, for sampling 10s or 30s music. MeLoDy inherits the highest-level LM from MusicLM for semantic modeling, and applies a novel dual-path diffusion (DPD) model and an audio VAE-GAN to efficiently decode the conditioning semantic tokens into waveform. DPD is proposed to simultaneously model the coarse and fine acoustics by incorporating the semantic information into segments of latents effectively via cross-attention at each denoising step. Our experimental results suggest the superiority of MeLoDy, not only in its practical advantages on sampling speed and infinitely continuable generation, but also in its state-of-the-art musicality, audio quality, and text correlation. Our samples are available at https://Efficient-MeLoDy.github.io/.
AUTM Flow: Atomic Unrestricted Time Machine for Monotonic Normalizing Flows
Jun 05, 2022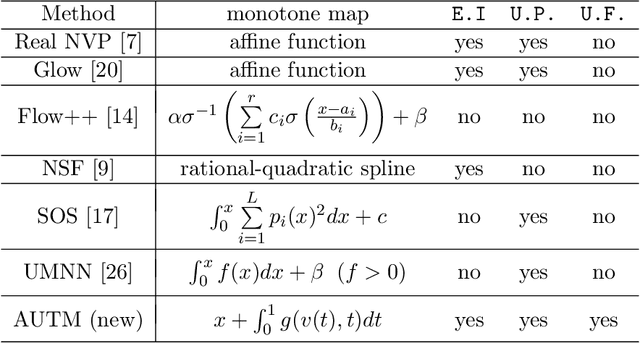
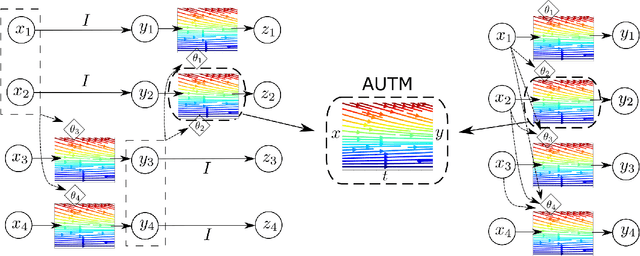
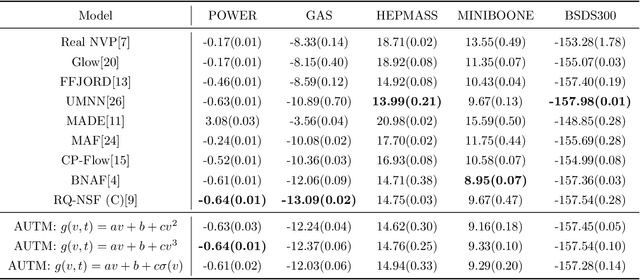

Nonlinear monotone transformations are used extensively in normalizing flows to construct invertible triangular mappings from simple distributions to complex ones. In existing literature, monotonicity is usually enforced by restricting function classes or model parameters and the inverse transformation is often approximated by root-finding algorithms as a closed-form inverse is unavailable. In this paper, we introduce a new integral-based approach termed "Atomic Unrestricted Time Machine (AUTM)", equipped with unrestricted integrands and easy-to-compute explicit inverse. AUTM offers a versatile and efficient way to the design of normalizing flows with explicit inverse and unrestricted function classes or parameters. Theoretically, we present a constructive proof that AUTM is universal: all monotonic normalizing flows can be viewed as limits of AUTM flows. We provide a concrete example to show how to approximate any given monotonic normalizing flow using AUTM flows with guaranteed convergence. The result implies that AUTM can be used to transform an existing flow into a new one equipped with explicit inverse and unrestricted parameters. The performance of the new approach is evaluated on high dimensional density estimation, variational inference and image generation. Experiments demonstrate superior speed and memory efficiency of AUTM.
Generating a Doppelganger Graph: Resembling but Distinct
Jan 23, 2021

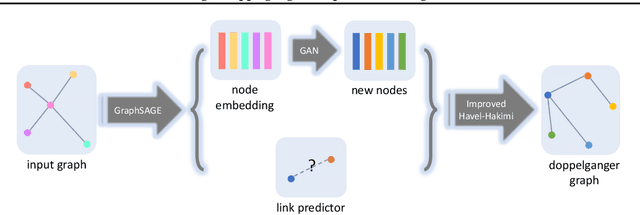

Deep generative models, since their inception, have become increasingly more capable of generating novel and perceptually realistic signals (e.g., images and sound waves). With the emergence of deep models for graph structured data, natural interests seek extensions of these generative models for graphs. Successful extensions were seen recently in the case of learning from a collection of graphs (e.g., protein data banks), but the learning from a single graph has been largely under explored. The latter case, however, is important in practice. For example, graphs in financial and healthcare systems contain so much confidential information that their public accessibility is nearly impossible, but open science in these fields can only advance when similar data are available for benchmarking. In this work, we propose an approach to generating a doppelganger graph that resembles a given one in many graph properties but nonetheless can hardly be used to reverse engineer the original one, in the sense of a near zero edge overlap. The approach is an orchestration of graph representation learning, generative adversarial networks, and graph realization algorithms. Through comparison with several graph generative models (either parameterized by neural networks or not), we demonstrate that our result barely reproduces the given graph but closely matches its properties. We further show that downstream tasks, such as node classification, on the generated graphs reach similar performance to the use of the original ones.