 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePolyVoice: Language Models for Speech to Speech Translation
Paper and Code
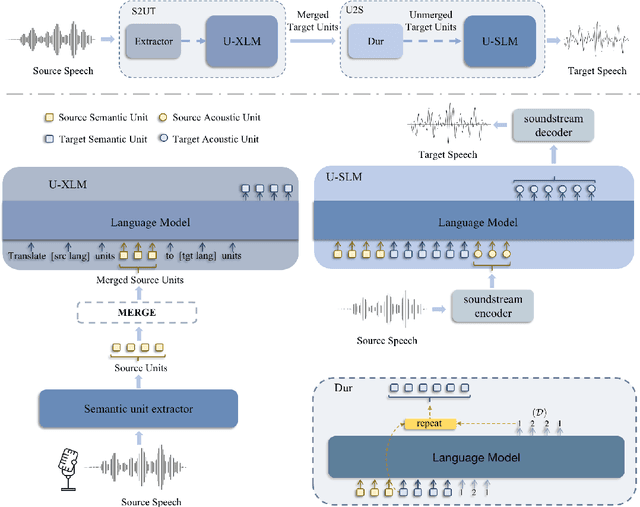

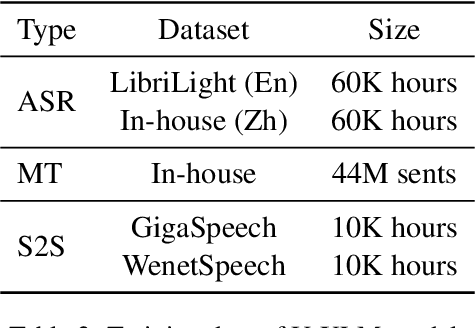
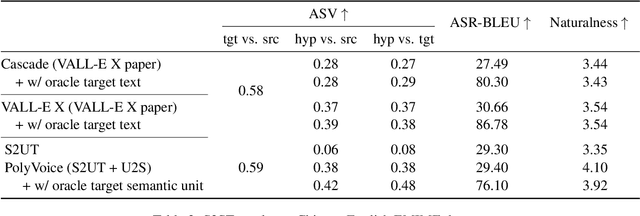
We propose PolyVoice, a language model-based framework for speech-to-speech translation (S2ST) system. Our framework consists of two language models: a translation language model and a speech synthesis language model. We use discretized speech units, which are generated in a fully unsupervised way, and thus our framework can be used for unwritten languages. For the speech synthesis part, we adopt the existing VALL-E X approach and build a unit-based audio language model. This grants our framework the ability to preserve the voice characteristics and the speaking style of the original speech. We examine our system on Chinese $\rightarrow$ English and English $\rightarrow$ Spanish pairs. Experimental results show that our system can generate speech with high translation quality and audio quality. Speech samples are available at https://speechtranslation.github.io/polyvoice.