 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSnakeGAN: A Universal Vocoder Leveraging DDSP Prior Knowledge and Periodic Inductive Bias
Sep 14, 2023



Generative adversarial network (GAN)-based neural vocoders have been widely used in audio synthesis tasks due to their high generation quality, efficient inference, and small computation footprint. However, it is still challenging to train a universal vocoder which can generalize well to out-of-domain (OOD) scenarios, such as unseen speaking styles, non-speech vocalization, singing, and musical pieces. In this work, we propose SnakeGAN, a GAN-based universal vocoder, which can synthesize high-fidelity audio in various OOD scenarios. SnakeGAN takes a coarse-grained signal generated by a differentiable digital signal processing (DDSP) model as prior knowledge, aiming at recovering high-fidelity waveform from a Mel-spectrogram. We introduce periodic nonlinearities through the Snake activation function and anti-aliased representation into the generator, which further brings the desired inductive bias for audio synthesis and significantly improves the extrapolation capacity for universal vocoding in unseen scenarios. To validate the effectiveness of our proposed method, we train SnakeGAN with only speech data and evaluate its performance for various OOD distributions with both subjective and objective metrics. Experimental results show that SnakeGAN significantly outperforms the compared approaches and can generate high-fidelity audio samples including unseen speakers with unseen styles, singing voices, instrumental pieces, and nonverbal vocalization.
Joint Multi-scale Cross-lingual Speaking Style Transfer with Bidirectional Attention Mechanism for Automatic Dubbing
May 09, 2023Automatic dubbing, which generates a corresponding version of the input speech in another language, could be widely utilized in many real-world scenarios such as video and game localization. In addition to synthesizing the translated scripts, automatic dubbing needs to further transfer the speaking style in the original language to the dubbed speeches to give audiences the impression that the characters are speaking in their native tongue. However, state-of-the-art automatic dubbing systems only model the transfer on duration and speaking rate, neglecting the other aspects in speaking style such as emotion, intonation and emphasis which are also crucial to fully perform the characters and speech understanding. In this paper, we propose a joint multi-scale cross-lingual speaking style transfer framework to simultaneously model the bidirectional speaking style transfer between languages at both global (i.e. utterance level) and local (i.e. word level) scales. The global and local speaking styles in each language are extracted and utilized to predicted the global and local speaking styles in the other language with an encoder-decoder framework for each direction and a shared bidirectional attention mechanism for both directions. A multi-scale speaking style enhanced FastSpeech 2 is then utilized to synthesize the predicted the global and local speaking styles to speech for each language. Experiment results demonstrate the effectiveness of our proposed framework, which outperforms a baseline with only duration transfer in both objective and subjective evaluations.
Content-Dependent Fine-Grained Speaker Embedding for Zero-Shot Speaker Adaptation in Text-to-Speech Synthesis
Apr 03, 2022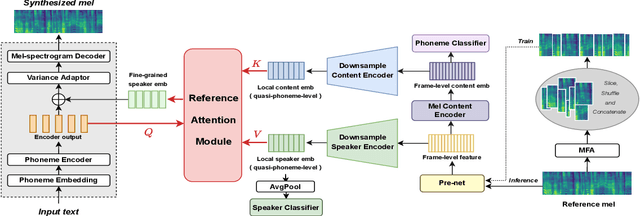

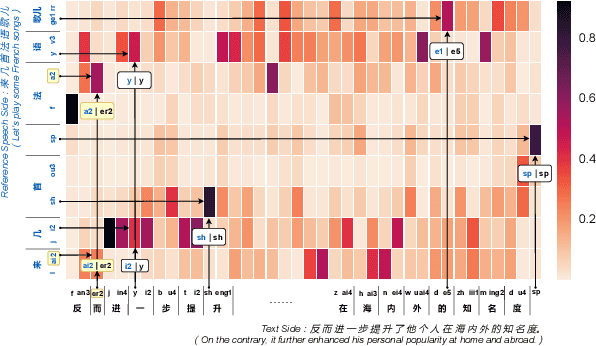

Zero-shot speaker adaptation aims to clone an unseen speaker's voice without any adaptation time and parameters. Previous researches usually use a speaker encoder to extract a global fixed speaker embedding from reference speech, and several attempts have tried variable-length speaker embedding. However, they neglect to transfer the personal pronunciation characteristics related to phoneme content, leading to poor speaker similarity in terms of detailed speaking styles and pronunciation habits. To improve the ability of the speaker encoder to model personal pronunciation characteristics, we propose content-dependent fine-grained speaker embedding for zero-shot speaker adaptation. The corresponding local content embeddings and speaker embeddings are extracted from a reference speech, respectively. Instead of modeling the temporal relations, a reference attention module is introduced to model the content relevance between the reference speech and the input text, and to generate the fine-grained speaker embedding for each phoneme encoder output. The experimental results show that our proposed method can improve speaker similarity of synthesized speeches, especially for unseen speakers.