 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeU-Style: Cascading U-nets with Multi-level Speaker and Style Modeling for Zero-Shot Voice Cloning
Paper and Code
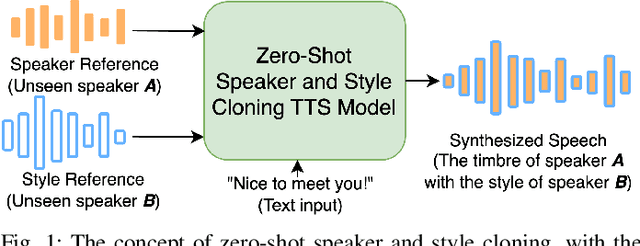
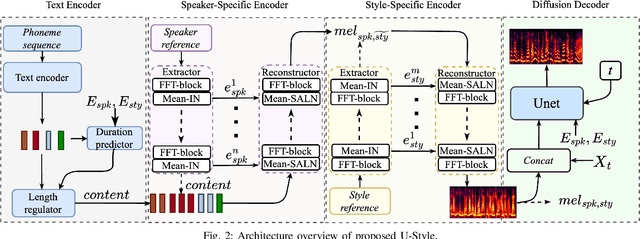
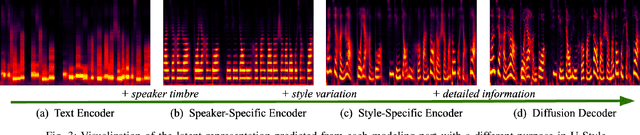
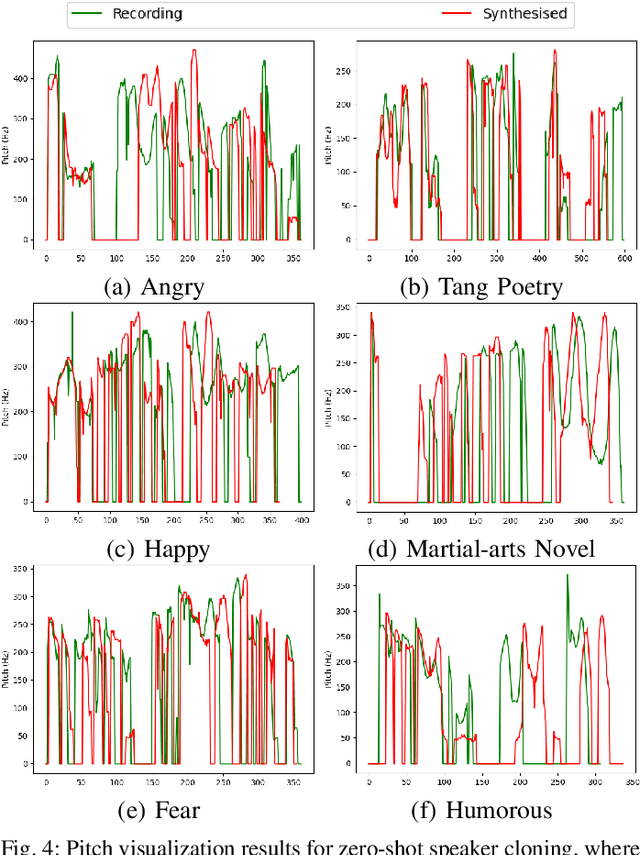
Zero-shot speaker cloning aims to synthesize speech for any target speaker unseen during TTS system building, given only a single speech reference of the speaker at hand. Although more practical in real applications, the current zero-shot methods still produce speech with undesirable naturalness and speaker similarity. Moreover, endowing the target speaker with arbitrary speaking styles in the zero-shot setup has not been considered. This is because the unique challenge of zero-shot speaker and style cloning is to learn the disentangled speaker and style representations from only short references representing an arbitrary speaker and an arbitrary style. To address this challenge, we propose U-Style, which employs Grad-TTS as the backbone, particularly cascading a speaker-specific encoder and a style-specific encoder between the text encoder and the diffusion decoder. Thus, leveraging signal perturbation, U-Style is explicitly decomposed into speaker- and style-specific modeling parts, achieving better speaker and style disentanglement. To improve unseen speaker and style modeling ability, these two encoders conduct multi-level speaker and style modeling by skip-connected U-nets, incorporating the representation extraction and information reconstruction process. Besides, to improve the naturalness of synthetic speech, we adopt mean-based instance normalization and style adaptive layer normalization in these encoders to perform representation extraction and condition adaptation, respectively. Experiments show that U-Style significantly surpasses the state-of-the-art methods in unseen speaker cloning regarding naturalness and speaker similarity. Notably, U-Style can transfer the style from an unseen source speaker to another unseen target speaker, achieving flexible combinations of desired speaker timbre and style in zero-shot voice cloning.