 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMSM-VC: High-fidelity Source Style Transfer for Non-Parallel Voice Conversion by Multi-scale Style Modeling
Paper and Code
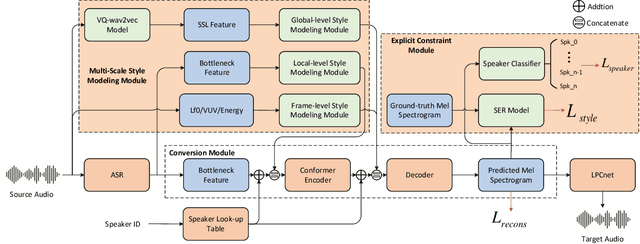



In addition to conveying the linguistic content from source speech to converted speech, maintaining the speaking style of source speech also plays an important role in the voice conversion (VC) task, which is essential in many scenarios with highly expressive source speech, such as dubbing and data augmentation. Previous work generally took explicit prosodic features or fixed-length style embedding extracted from source speech to model the speaking style of source speech, which is insufficient to achieve comprehensive style modeling and target speaker timbre preservation. Inspired by the style's multi-scale nature of human speech, a multi-scale style modeling method for the VC task, referred to as MSM-VC, is proposed in this paper. MSM-VC models the speaking style of source speech from different levels. To effectively convey the speaking style and meanwhile prevent timbre leakage from source speech to converted speech, each level's style is modeled by specific representation. Specifically, prosodic features, pre-trained ASR model's bottleneck features, and features extracted by a model trained with a self-supervised strategy are adopted to model the frame, local, and global-level styles, respectively. Besides, to balance the performance of source style modeling and target speaker timbre preservation, an explicit constraint module consisting of a pre-trained speech emotion recognition model and a speaker classifier is introduced to MSM-VC. This explicit constraint module also makes it possible to simulate the style transfer inference process during the training to improve the disentanglement ability and alleviate the mismatch between training and inference. Experiments performed on the highly expressive speech corpus demonstrate that MSM-VC is superior to the state-of-the-art VC methods for modeling source speech style while maintaining good speech quality and speaker similarity.