 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBasis-MelGAN: Efficient Neural Vocoder Based on Audio Decomposition
Paper and Code

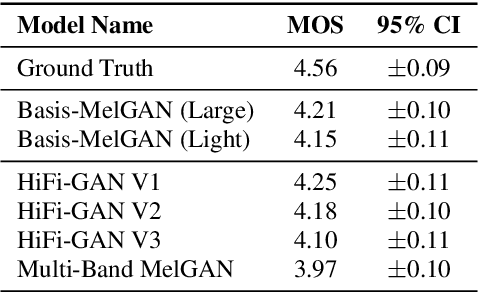
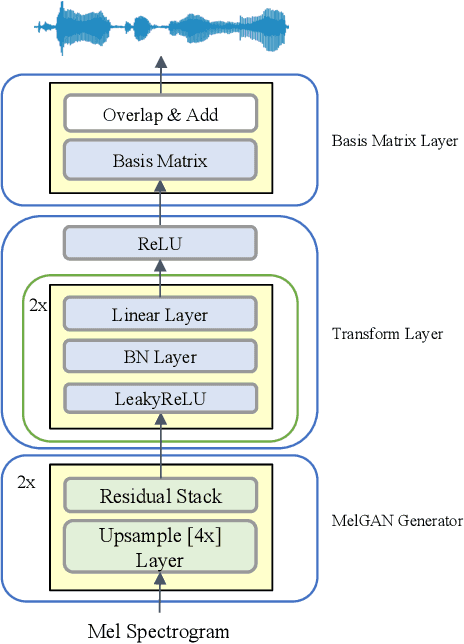
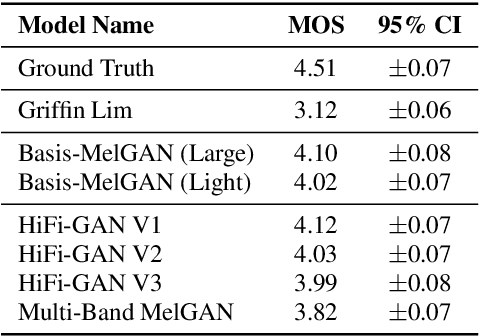
Recent studies have shown that neural vocoders based on generative adversarial network (GAN) can generate audios with high quality. While GAN based neural vocoders have shown to be computationally much more efficient than those based on autoregressive predictions, the real-time generation of the highest quality audio on CPU is still a very challenging task. One major computation of all GAN-based neural vocoders comes from the stacked upsampling layers, which were designed to match the length of the waveform's length of output and temporal resolution. Meanwhile, the computational complexity of upsampling networks is closely correlated with the numbers of samples generated for each window. To reduce the computation of upsampling layers, we propose a new GAN based neural vocoder called Basis-MelGAN where the raw audio samples are decomposed with a learned basis and their associated weights. As the prediction targets of Basis-MelGAN are the weight values associated with each learned basis instead of the raw audio samples, the upsampling layers in Basis-MelGAN can be designed with much simpler networks. Compared with other GAN based neural vocoders, the proposed Basis-MelGAN could produce comparable high-quality audio but significantly reduced computational complexity from HiFi-GAN V1's 17.74 GFLOPs to 7.95 GFLOPs.