 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMMAE: A Massive Multitask Audio Editing Benchmark
Jun 05, 2026We introduce MMAE, a Massive Multitask Audio Editing benchmark, serving as the first comprehensive evaluation testbed designed for general-purpose instruction-based audio editing. Spurred by the shift toward intelligent creation, interactive editing has rapidly expanded from visual domains, pioneered by models like Nano-banana 2 for images and Gemini-Omni for video, into audio. However, the current evaluation infrastructure lags severely, remaining highly fragmented and restricted to specific subdomains or basic operations. Unlike existing benchmarks that are limited in scope, MMAE extends to a broad spectrum of real-world scenarios, encompassing 7 distinct audio modalities, including sound, speech, music, and their mixtures. Furthermore, we establish a comprehensive taxonomy spanning 6 levels of task complexity, from basic modifications to multi-hop reasoning and multi-round editing, 2 levels of granularity, and 8 distinct operation types. Meticulously curated through human-agent collaboration, MMAE comprises 2,000 high-fidelity samples paired with a pioneering rubric-based evaluation framework. By decomposing free-form tasks into 17,741 verifiable criteria, this robust rubric-based paradigm enables a precise, multi-dimensional assessment of both instruction following and context consistency. Our extensive evaluation of leading models reveals that current systems remain far from achieving reliable edits. Strikingly, the Exact Match Rate (EMR) consistently falls below 5% and plummets to an absolute 0% in complex, mixed-modality tasks, exposing critical bottlenecks in precise execution and structural robustness. We hope MMAE will serve as a catalyst for future advances in the intelligent creation community, providing a clear diagnostic roadmap and establishing a standardized, long-lasting evaluation paradigm for next-generation audio editing systems.
WavTTS: Towards High-Quality Zero-Shot TTS via Direct Raw Waveform Modeling
Jun 02, 2026Recently, diffusion models operating on VAE latents or mel-spectrograms have become the dominant paradigm for zero-shot TTS. Although these compressed representations improve generation efficiency, they inevitably suffer from information loss and non-end-to-end training. Theoretically, directly modeling raw waveforms circumvents these issues; however, this direction remains underexplored and is often deemed difficult due to the extremely long sequence length of audio signals. To overcome this, we propose WavTTS, the first raw waveform generative TTS model that substantially narrows the gap with latent-space generative models. Built upon the flow matching with Diffusion Transformer (DiT), WavTTS directly models speech waveforms via a simple patchification strategy, while integrating multi-scale mel-spectrogram supervision to provide perceptual guidance during training. Furthermore, we investigate the impact of prediction targets and noise scheduling in waveform diffusion, and develop an effective schedule design to improve generation quality. Evaluations on open-source benchmarks demonstrate that WavTTS closely approaches the performance of current state-of-the-art latent generative zero-shot TTS models, while substantially outperforming previous end-to-end speech generation models. Our findings demonstrate the feasibility of scaling diffusion-based TTS directly in the waveform space, opening a new direction for end-to-end speech generation.
Audio ControlNet for Fine-Grained Audio Generation and Editing
Feb 04, 2026We study the fine-grained text-to-audio (T2A) generation task. While recent models can synthesize high-quality audio from text descriptions, they often lack precise control over attributes such as loudness, pitch, and sound events. Unlike prior approaches that retrain models for specific control types, we propose to train ControlNet models on top of pre-trained T2A backbones to achieve controllable generation over loudness, pitch, and event roll. We introduce two designs, T2A-ControlNet and T2A-Adapter, and show that the T2A-Adapter model offers a more efficient structure with strong control ability. With only 38M additional parameters, T2A-Adapter achieves state-of-the-art performance on the AudioSet-Strong in both event-level and segment-level F1 scores. We further extend this framework to audio editing, proposing T2A-Editor for removing and inserting audio events at time locations specified by instructions. Models, code, dataset pipelines, and benchmarks will be released to support future research on controllable audio generation and editing.
SemanticAudio: Audio Generation and Editing in Semantic Space
Jan 29, 2026In recent years, Text-to-Audio Generation has achieved remarkable progress, offering sound creators powerful tools to transform textual inspirations into vivid audio. However, existing models predominantly operate directly in the acoustic latent space of a Variational Autoencoder (VAE), often leading to suboptimal alignment between generated audio and textual descriptions. In this paper, we introduce SemanticAudio, a novel framework that conducts both audio generation and editing directly in a high-level semantic space. We define this semantic space as a compact representation capturing the global identity and temporal sequence of sound events, distinct from fine-grained acoustic details. SemanticAudio employs a two-stage Flow Matching architecture: the Semantic Planner first generates these compact semantic features to sketch the global semantic layout, and the Acoustic Synthesizer subsequently produces high-fidelity acoustic latents conditioned on this semantic plan. Leveraging this decoupled design, we further introduce a training-free text-guided editing mechanism that enables precise attribute-level modifications on general audio without retraining. Specifically, this is achieved by steering the semantic generation trajectory via the difference of velocity fields derived from source and target text prompts. Extensive experiments demonstrate that SemanticAudio surpasses existing mainstream approaches in semantic alignment. Demo available at: https://semanticaudio1.github.io/
SLAM-LLM: A Modular, Open-Source Multimodal Large Language Model Framework and Best Practice for Speech, Language, Audio and Music Processing
Jan 14, 2026The recent surge in open-source Multimodal Large Language Models (MLLM) frameworks, such as LLaVA, provides a convenient kickoff for artificial intelligence developers and researchers. However, most of the MLLM frameworks take vision as the main input modality, and provide limited in-depth support for the modality of speech, audio, and music. This situation hinders the development of audio-language models, and forces researchers to spend a lot of effort on code writing and hyperparameter tuning. We present SLAM-LLM, an open-source deep learning framework designed to train customized MLLMs, focused on speech, language, audio, and music processing. SLAM-LLM provides a modular configuration of different encoders, projectors, LLMs, and parameter-efficient fine-tuning plugins. SLAM-LLM also includes detailed training and inference recipes for mainstream tasks, along with high-performance checkpoints like LLM-based Automatic Speech Recognition (ASR), Automated Audio Captioning (AAC), and Music Captioning (MC). Some of these recipes have already reached or are nearing state-of-the-art performance, and some relevant techniques have also been accepted by academic papers. We hope SLAM-LLM will accelerate iteration, development, data engineering, and model training for researchers. We are committed to continually pushing forward audio-based MLLMs through this open-source framework, and call on the community to contribute to the LLM-based speech, audio and music processing.
MeanAudio: Fast and Faithful Text-to-Audio Generation with Mean Flows
Aug 08, 2025Recent developments in diffusion- and flow- based models have significantly advanced Text-to-Audio Generation (TTA). While achieving great synthesis quality and controllability, current TTA systems still suffer from slow inference speed, which significantly limits their practical applicability. This paper presents MeanAudio, a novel MeanFlow-based model tailored for fast and faithful text-to-audio generation. Built on a Flux-style latent transformer, MeanAudio regresses the average velocity field during training, enabling fast generation by mapping directly from the start to the endpoint of the flow trajectory. By incorporating classifier-free guidance (CFG) into the training target, MeanAudio incurs no additional cost in the guided sampling process. To further stabilize training, we propose an instantaneous-to-mean curriculum with flow field mix-up, which encourages the model to first learn the foundational instantaneous dynamics, and then gradually adapt to mean flows. This strategy proves critical for enhancing training efficiency and generation quality. Experimental results demonstrate that MeanAudio achieves state-of-the-art performance in single-step audio generation. Specifically, it achieves a real time factor (RTF) of 0.013 on a single NVIDIA RTX 3090, yielding a 100x speedup over SOTA diffusion-based TTA systems. Moreover, MeanAudio also demonstrates strong performance in multi-step generation, enabling smooth and coherent transitions across successive synthesis steps.
Towards Reliable Large Audio Language Model
May 25, 2025Recent advancements in large audio language models (LALMs) have demonstrated impressive results and promising prospects in universal understanding and reasoning across speech, music, and general sound. However, these models still lack the ability to recognize their knowledge boundaries and refuse to answer questions they don't know proactively. While there have been successful attempts to enhance the reliability of LLMs, reliable LALMs remain largely unexplored. In this paper, we systematically investigate various approaches towards reliable LALMs, including training-free methods such as multi-modal chain-of-thought (MCoT), and training-based methods such as supervised fine-tuning (SFT). Besides, we identify the limitations of previous evaluation metrics and propose a new metric, the Reliability Gain Index (RGI), to assess the effectiveness of different reliable methods. Our findings suggest that both training-free and training-based methods enhance the reliability of LALMs to different extents. Moreover, we find that awareness of reliability is a "meta ability", which can be transferred across different audio modalities, although significant structural and content differences exist among sound, music, and speech.
MMAR: A Challenging Benchmark for Deep Reasoning in Speech, Audio, Music, and Their Mix
May 19, 2025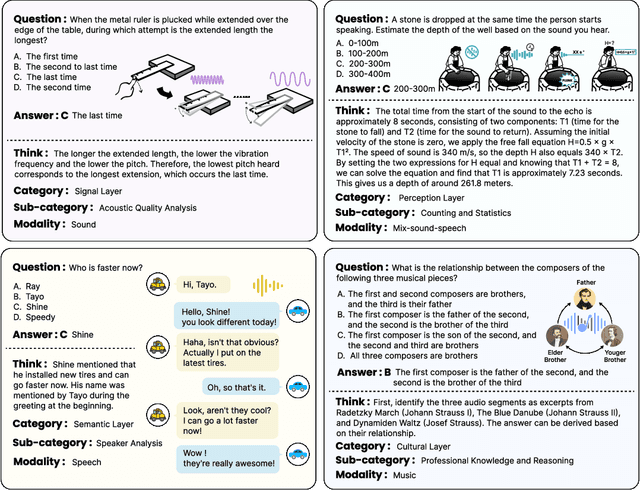

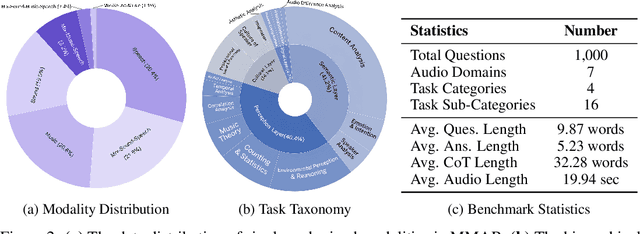
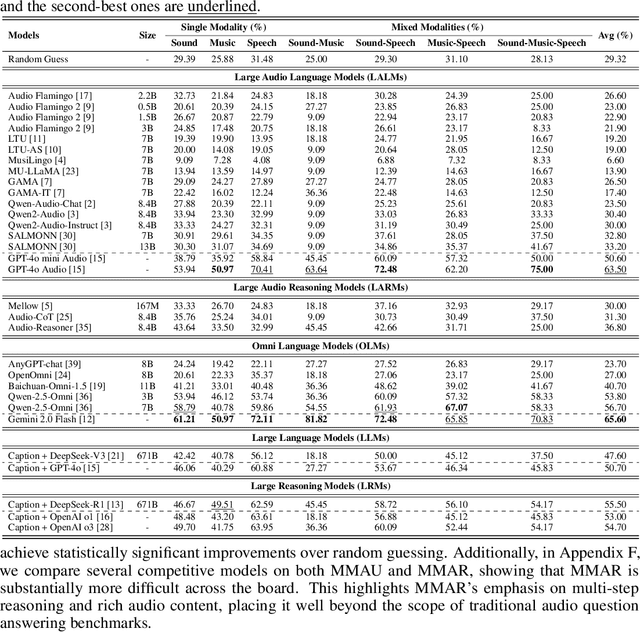
We introduce MMAR, a new benchmark designed to evaluate the deep reasoning capabilities of Audio-Language Models (ALMs) across massive multi-disciplinary tasks. MMAR comprises 1,000 meticulously curated audio-question-answer triplets, collected from real-world internet videos and refined through iterative error corrections and quality checks to ensure high quality. Unlike existing benchmarks that are limited to specific domains of sound, music, or speech, MMAR extends them to a broad spectrum of real-world audio scenarios, including mixed-modality combinations of sound, music, and speech. Each question in MMAR is hierarchically categorized across four reasoning layers: Signal, Perception, Semantic, and Cultural, with additional sub-categories within each layer to reflect task diversity and complexity. To further foster research in this area, we annotate every question with a Chain-of-Thought (CoT) rationale to promote future advancements in audio reasoning. Each item in the benchmark demands multi-step deep reasoning beyond surface-level understanding. Moreover, a part of the questions requires graduate-level perceptual and domain-specific knowledge, elevating the benchmark's difficulty and depth. We evaluate MMAR using a broad set of models, including Large Audio-Language Models (LALMs), Large Audio Reasoning Models (LARMs), Omni Language Models (OLMs), Large Language Models (LLMs), and Large Reasoning Models (LRMs), with audio caption inputs. The performance of these models on MMAR highlights the benchmark's challenging nature, and our analysis further reveals critical limitations of understanding and reasoning capabilities among current models. We hope MMAR will serve as a catalyst for future advances in this important but little-explored area.
URO-Bench: A Comprehensive Benchmark for End-to-End Spoken Dialogue Models
Feb 25, 2025
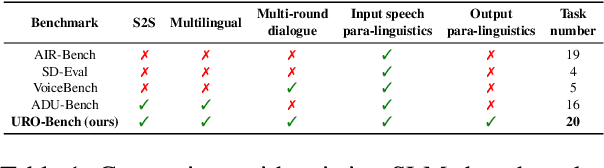

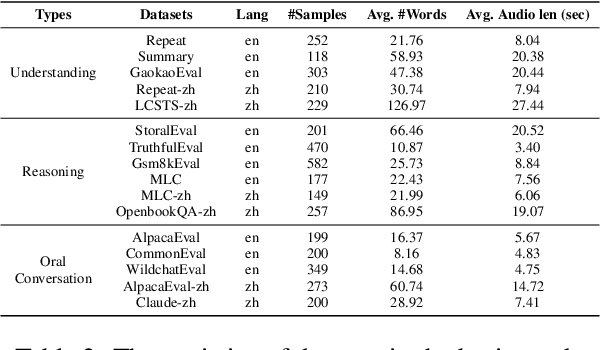
In recent years, with advances in large language models (LLMs), end-to-end spoken dialogue models (SDMs) have made significant strides. Compared to text-based LLMs, the evaluation of SDMs needs to take speech-related aspects into account, such as paralinguistic information and speech quality. However, there is still a lack of comprehensive evaluations for SDMs in speech-to-speech (S2S) scenarios. To address this gap, we propose URO-Bench, an extensive benchmark for SDMs. Notably, URO-Bench is the first S2S benchmark that covers evaluations about multilingualism, multi-round dialogues, and paralinguistics. Our benchmark is divided into two difficulty levels: basic track and pro track, consisting of 16 and 20 datasets respectively, evaluating the model's abilities in Understanding, Reasoning, and Oral conversation. Evaluations on our proposed benchmark reveal that current open-source SDMs perform rather well in daily QA tasks, but lag behind their backbone LLMs in terms of instruction-following ability and also suffer from catastrophic forgetting. Their performance in advanced evaluations of paralinguistic information and audio understanding remains subpar, highlighting the need for further research in this direction. We hope that URO-Bench can effectively facilitate the development of spoken dialogue models by providing a multifaceted evaluation of existing models and helping to track progress in this area.
SLAM-Omni: Timbre-Controllable Voice Interaction System with Single-Stage Training
Dec 20, 2024
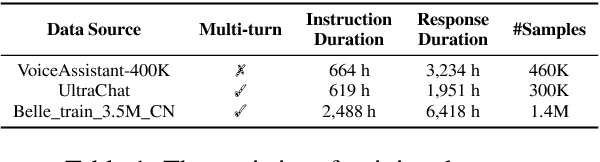

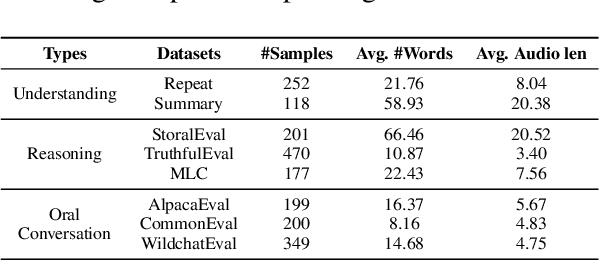
Recent advancements highlight the potential of end-to-end real-time spoken dialogue systems, showcasing their low latency and high quality. In this paper, we introduce SLAM-Omni, a timbre-controllable, end-to-end voice interaction system with single-stage training. SLAM-Omni achieves zero-shot timbre control by modeling spoken language with semantic tokens and decoupling speaker information to a vocoder. By predicting grouped speech semantic tokens at each step, our method significantly reduces the sequence length of audio tokens, accelerating both training and inference. Additionally, we propose historical text prompting to compress dialogue history, facilitating efficient multi-round interactions. Comprehensive evaluations reveal that SLAM-Omni outperforms prior models of similar scale, requiring only 15 hours of training on 4 GPUs with limited data. Notably, it is the first spoken dialogue system to achieve competitive performance with a single-stage training approach, eliminating the need for pre-training on TTS or ASR tasks. Further experiments validate its multilingual and multi-turn dialogue capabilities on larger datasets.