 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDynamic Differential Linear Attention: Enhancing Linear Diffusion Transformer for High-Quality Image Generation
Jan 20, 2026Diffusion transformers (DiTs) have emerged as a powerful architecture for high-fidelity image generation, yet the quadratic cost of self-attention poses a major scalability bottleneck. To address this, linear attention mechanisms have been adopted to reduce computational cost; unfortunately, the resulting linear diffusion transformers (LiTs) models often come at the expense of generative performance, frequently producing over-smoothed attention weights that limit expressiveness. In this work, we introduce Dynamic Differential Linear Attention (DyDiLA), a novel linear attention formulation that enhances the effectiveness of LiTs by mitigating the oversmoothing issue and improving generation quality. Specifically, the novelty of DyDiLA lies in three key designs: (i) dynamic projection module, which facilitates the decoupling of token representations by learning with dynamically assigned knowledge; (ii) dynamic measure kernel, which provides a better similarity measurement to capture fine-grained semantic distinctions between tokens by dynamically assigning kernel functions for token processing; and (iii) token differential operator, which enables more robust query-to-key retrieval by calculating the differences between the tokens and their corresponding information redundancy produced by dynamic measure kernel. To capitalize on DyDiLA, we introduce a refined LiT, termed DyDi-LiT, that systematically incorporates our advancements. Extensive experiments show that DyDi-LiT consistently outperforms current state-of-the-art (SOTA) models across multiple metrics, underscoring its strong practical potential.
Shushing! Let's Imagine an Authentic Speech from the Silent Video
Mar 19, 2025Vision-guided speech generation aims to produce authentic speech from facial appearance or lip motions without relying on auditory signals, offering significant potential for applications such as dubbing in filmmaking and assisting individuals with aphonia. Despite recent progress, existing methods struggle to achieve unified cross-modal alignment across semantics, timbre, and emotional prosody from visual cues, prompting us to propose Consistent Video-to-Speech (CV2S) as an extended task to enhance cross-modal consistency. To tackle emerging challenges, we introduce ImaginTalk, a novel cross-modal diffusion framework that generates faithful speech using only visual input, operating within a discrete space. Specifically, we propose a discrete lip aligner that predicts discrete speech tokens from lip videos to capture semantic information, while an error detector identifies misaligned tokens, which are subsequently refined through masked language modeling with BERT. To further enhance the expressiveness of the generated speech, we develop a style diffusion transformer equipped with a face-style adapter that adaptively customizes identity and prosody dynamics across both the channel and temporal dimensions while ensuring synchronization with lip-aware semantic features. Extensive experiments demonstrate that ImaginTalk can generate high-fidelity speech with more accurate semantic details and greater expressiveness in timbre and emotion compared to state-of-the-art baselines. Demos are shown at our project page: https://imagintalk.github.io.
Emotional Face-to-Speech
Feb 03, 2025



How much can we infer about an emotional voice solely from an expressive face? This intriguing question holds great potential for applications such as virtual character dubbing and aiding individuals with expressive language disorders. Existing face-to-speech methods offer great promise in capturing identity characteristics but struggle to generate diverse vocal styles with emotional expression. In this paper, we explore a new task, termed emotional face-to-speech, aiming to synthesize emotional speech directly from expressive facial cues. To that end, we introduce DEmoFace, a novel generative framework that leverages a discrete diffusion transformer (DiT) with curriculum learning, built upon a multi-level neural audio codec. Specifically, we propose multimodal DiT blocks to dynamically align text and speech while tailoring vocal styles based on facial emotion and identity. To enhance training efficiency and generation quality, we further introduce a coarse-to-fine curriculum learning algorithm for multi-level token processing. In addition, we develop an enhanced predictor-free guidance to handle diverse conditioning scenarios, enabling multi-conditional generation and disentangling complex attributes effectively. Extensive experimental results demonstrate that DEmoFace generates more natural and consistent speech compared to baselines, even surpassing speech-driven methods. Demos are shown at https://demoface-ai.github.io/.
DreamVideo-2: Zero-Shot Subject-Driven Video Customization with Precise Motion Control
Oct 17, 2024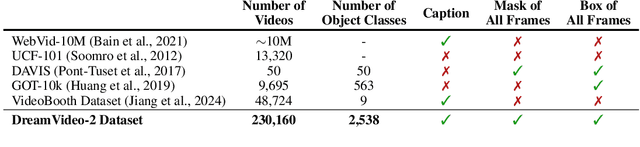
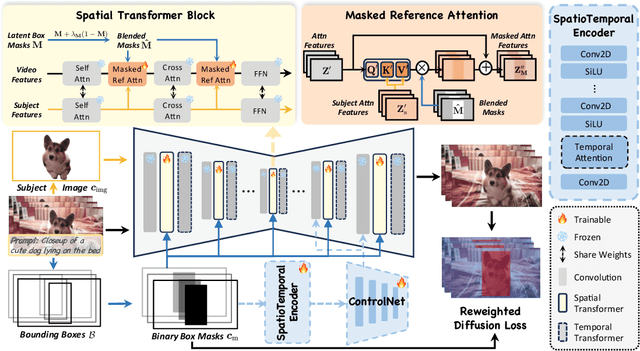


Recent advances in customized video generation have enabled users to create videos tailored to both specific subjects and motion trajectories. However, existing methods often require complicated test-time fine-tuning and struggle with balancing subject learning and motion control, limiting their real-world applications. In this paper, we present DreamVideo-2, a zero-shot video customization framework capable of generating videos with a specific subject and motion trajectory, guided by a single image and a bounding box sequence, respectively, and without the need for test-time fine-tuning. Specifically, we introduce reference attention, which leverages the model's inherent capabilities for subject learning, and devise a mask-guided motion module to achieve precise motion control by fully utilizing the robust motion signal of box masks derived from bounding boxes. While these two components achieve their intended functions, we empirically observe that motion control tends to dominate over subject learning. To address this, we propose two key designs: 1) the masked reference attention, which integrates a blended latent mask modeling scheme into reference attention to enhance subject representations at the desired positions, and 2) a reweighted diffusion loss, which differentiates the contributions of regions inside and outside the bounding boxes to ensure a balance between subject and motion control. Extensive experimental results on a newly curated dataset demonstrate that DreamVideo-2 outperforms state-of-the-art methods in both subject customization and motion control. The dataset, code, and models will be made publicly available.
AP-LDM: Attentive and Progressive Latent Diffusion Model for Training-Free High-Resolution Image Generation
Oct 08, 2024


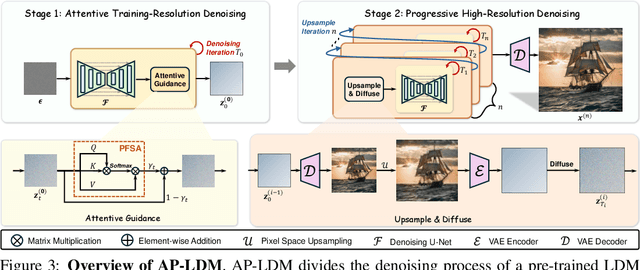
Latent diffusion models (LDMs), such as Stable Diffusion, often experience significant structural distortions when directly generating high-resolution (HR) images that exceed their original training resolutions. A straightforward and cost-effective solution is to adapt pre-trained LDMs for HR image generation; however, existing methods often suffer from poor image quality and long inference time. In this paper, we propose an Attentive and Progressive LDM (AP-LDM), a novel, training-free framework aimed at enhancing HR image quality while accelerating the generation process. AP-LDM decomposes the denoising process of LDMs into two stages: (i) attentive training-resolution denoising, and (ii) progressive high-resolution denoising. The first stage generates a latent representation of a higher-quality training-resolution image through the proposed attentive guidance, which utilizes a novel parameter-free self-attention mechanism to enhance the structural consistency. The second stage progressively performs upsampling in pixel space, alleviating the severe artifacts caused by latent space upsampling. Leveraging the effective initialization from the first stage enables denoising at higher resolutions with significantly fewer steps, enhancing overall efficiency. Extensive experimental results demonstrate that AP-LDM significantly outperforms state-of-the-art methods, delivering up to a 5x speedup in HR image generation, thereby highlighting its substantial advantages for real-world applications. Code is available at https://github.com/kmittle/AP-LDM.
DepMamba: Progressive Fusion Mamba for Multimodal Depression Detection
Sep 24, 2024



Depression is a common mental disorder that affects millions of people worldwide. Although promising, current multimodal methods hinge on aligned or aggregated multimodal fusion, suffering two significant limitations: (i) inefficient long-range temporal modeling, and (ii) sub-optimal multimodal fusion between intermodal fusion and intramodal processing. In this paper, we propose an audio-visual progressive fusion Mamba for multimodal depression detection, termed DepMamba. DepMamba features two core designs: hierarchical contextual modeling and progressive multimodal fusion. On the one hand, hierarchical modeling introduces convolution neural networks and Mamba to extract the local-to-global features within long-range sequences. On the other hand, the progressive fusion first presents a multimodal collaborative State Space Model (SSM) extracting intermodal and intramodal information for each modality, and then utilizes a multimodal enhanced SSM for modality cohesion. Extensive experimental results on two large-scale depression datasets demonstrate the superior performance of our DepMamba over existing state-of-the-art methods. Code is available at https://github.com/Jiaxin-Ye/DepMamba.
EmoBox: Multilingual Multi-corpus Speech Emotion Recognition Toolkit and Benchmark
Jun 11, 2024Speech emotion recognition (SER) is an important part of human-computer interaction, receiving extensive attention from both industry and academia. However, the current research field of SER has long suffered from the following problems: 1) There are few reasonable and universal splits of the datasets, making comparing different models and methods difficult. 2) No commonly used benchmark covers numerous corpus and languages for researchers to refer to, making reproduction a burden. In this paper, we propose EmoBox, an out-of-the-box multilingual multi-corpus speech emotion recognition toolkit, along with a benchmark for both intra-corpus and cross-corpus settings. For intra-corpus settings, we carefully designed the data partitioning for different datasets. For cross-corpus settings, we employ a foundation SER model, emotion2vec, to mitigate annotation errors and obtain a test set that is fully balanced in speakers and emotions distributions. Based on EmoBox, we present the intra-corpus SER results of 10 pre-trained speech models on 32 emotion datasets with 14 languages, and the cross-corpus SER results on 4 datasets with the fully balanced test sets. To the best of our knowledge, this is the largest SER benchmark, across language scopes and quantity scales. We hope that our toolkit and benchmark can facilitate the research of SER in the community.
emotion2vec: Self-Supervised Pre-Training for Speech Emotion Representation
Dec 23, 2023



We propose emotion2vec, a universal speech emotion representation model. emotion2vec is pre-trained on open-source unlabeled emotion data through self-supervised online distillation, combining utterance-level loss and frame-level loss during pre-training. emotion2vec outperforms state-of-the-art pre-trained universal models and emotion specialist models by only training linear layers for the speech emotion recognition task on the mainstream IEMOCAP dataset. In addition, emotion2vec shows consistent improvements among 10 different languages of speech emotion recognition datasets. emotion2vec also shows excellent results on other emotion tasks, such as song emotion recognition, emotion prediction in conversation, and sentiment analysis. Comparison experiments, ablation experiments, and visualization comprehensively demonstrate the universal capability of the proposed emotion2vec. To the best of our knowledge, emotion2vec is the first universal representation model in various emotion-related tasks, filling a gap in the field.
Emo-DNA: Emotion Decoupling and Alignment Learning for Cross-Corpus Speech Emotion Recognition
Aug 04, 2023



Cross-corpus speech emotion recognition (SER) seeks to generalize the ability of inferring speech emotion from a well-labeled corpus to an unlabeled one, which is a rather challenging task due to the significant discrepancy between two corpora. Existing methods, typically based on unsupervised domain adaptation (UDA), struggle to learn corpus-invariant features by global distribution alignment, but unfortunately, the resulting features are mixed with corpus-specific features or not class-discriminative. To tackle these challenges, we propose a novel Emotion Decoupling aNd Alignment learning framework (EMO-DNA) for cross-corpus SER, a novel UDA method to learn emotion-relevant corpus-invariant features. The novelties of EMO-DNA are two-fold: contrastive emotion decoupling and dual-level emotion alignment. On one hand, our contrastive emotion decoupling achieves decoupling learning via a contrastive decoupling loss to strengthen the separability of emotion-relevant features from corpus-specific ones. On the other hand, our dual-level emotion alignment introduces an adaptive threshold pseudo-labeling to select confident target samples for class-level alignment, and performs corpus-level alignment to jointly guide model for learning class-discriminative corpus-invariant features across corpora. Extensive experimental results demonstrate the superior performance of EMO-DNA over the state-of-the-art methods in several cross-corpus scenarios. Source code is available at https://github.com/Jiaxin-Ye/Emo-DNA.
Online Prototype Learning for Online Continual Learning
Aug 01, 2023Online continual learning (CL) studies the problem of learning continuously from a single-pass data stream while adapting to new data and mitigating catastrophic forgetting. Recently, by storing a small subset of old data, replay-based methods have shown promising performance. Unlike previous methods that focus on sample storage or knowledge distillation against catastrophic forgetting, this paper aims to understand why the online learning models fail to generalize well from a new perspective of shortcut learning. We identify shortcut learning as the key limiting factor for online CL, where the learned features may be biased, not generalizable to new tasks, and may have an adverse impact on knowledge distillation. To tackle this issue, we present the online prototype learning (OnPro) framework for online CL. First, we propose online prototype equilibrium to learn representative features against shortcut learning and discriminative features to avoid class confusion, ultimately achieving an equilibrium status that separates all seen classes well while learning new classes. Second, with the feedback of online prototypes, we devise a novel adaptive prototypical feedback mechanism to sense the classes that are easily misclassified and then enhance their boundaries. Extensive experimental results on widely-used benchmark datasets demonstrate the superior performance of OnPro over the state-of-the-art baseline methods. Source code is available at https://github.com/weilllllls/OnPro.