 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDynamic Differential Linear Attention: Enhancing Linear Diffusion Transformer for High-Quality Image Generation
Jan 20, 2026Diffusion transformers (DiTs) have emerged as a powerful architecture for high-fidelity image generation, yet the quadratic cost of self-attention poses a major scalability bottleneck. To address this, linear attention mechanisms have been adopted to reduce computational cost; unfortunately, the resulting linear diffusion transformers (LiTs) models often come at the expense of generative performance, frequently producing over-smoothed attention weights that limit expressiveness. In this work, we introduce Dynamic Differential Linear Attention (DyDiLA), a novel linear attention formulation that enhances the effectiveness of LiTs by mitigating the oversmoothing issue and improving generation quality. Specifically, the novelty of DyDiLA lies in three key designs: (i) dynamic projection module, which facilitates the decoupling of token representations by learning with dynamically assigned knowledge; (ii) dynamic measure kernel, which provides a better similarity measurement to capture fine-grained semantic distinctions between tokens by dynamically assigning kernel functions for token processing; and (iii) token differential operator, which enables more robust query-to-key retrieval by calculating the differences between the tokens and their corresponding information redundancy produced by dynamic measure kernel. To capitalize on DyDiLA, we introduce a refined LiT, termed DyDi-LiT, that systematically incorporates our advancements. Extensive experiments show that DyDi-LiT consistently outperforms current state-of-the-art (SOTA) models across multiple metrics, underscoring its strong practical potential.
Emotional Face-to-Speech
Feb 03, 2025



How much can we infer about an emotional voice solely from an expressive face? This intriguing question holds great potential for applications such as virtual character dubbing and aiding individuals with expressive language disorders. Existing face-to-speech methods offer great promise in capturing identity characteristics but struggle to generate diverse vocal styles with emotional expression. In this paper, we explore a new task, termed emotional face-to-speech, aiming to synthesize emotional speech directly from expressive facial cues. To that end, we introduce DEmoFace, a novel generative framework that leverages a discrete diffusion transformer (DiT) with curriculum learning, built upon a multi-level neural audio codec. Specifically, we propose multimodal DiT blocks to dynamically align text and speech while tailoring vocal styles based on facial emotion and identity. To enhance training efficiency and generation quality, we further introduce a coarse-to-fine curriculum learning algorithm for multi-level token processing. In addition, we develop an enhanced predictor-free guidance to handle diverse conditioning scenarios, enabling multi-conditional generation and disentangling complex attributes effectively. Extensive experimental results demonstrate that DEmoFace generates more natural and consistent speech compared to baselines, even surpassing speech-driven methods. Demos are shown at https://demoface-ai.github.io/.
AP-LDM: Attentive and Progressive Latent Diffusion Model for Training-Free High-Resolution Image Generation
Oct 08, 2024


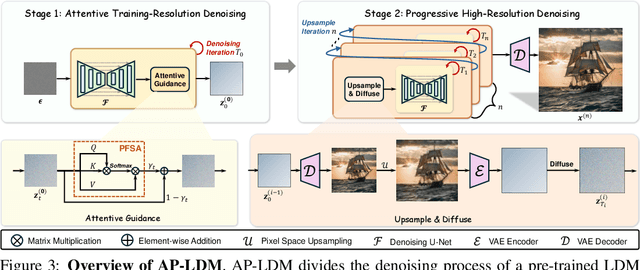
Latent diffusion models (LDMs), such as Stable Diffusion, often experience significant structural distortions when directly generating high-resolution (HR) images that exceed their original training resolutions. A straightforward and cost-effective solution is to adapt pre-trained LDMs for HR image generation; however, existing methods often suffer from poor image quality and long inference time. In this paper, we propose an Attentive and Progressive LDM (AP-LDM), a novel, training-free framework aimed at enhancing HR image quality while accelerating the generation process. AP-LDM decomposes the denoising process of LDMs into two stages: (i) attentive training-resolution denoising, and (ii) progressive high-resolution denoising. The first stage generates a latent representation of a higher-quality training-resolution image through the proposed attentive guidance, which utilizes a novel parameter-free self-attention mechanism to enhance the structural consistency. The second stage progressively performs upsampling in pixel space, alleviating the severe artifacts caused by latent space upsampling. Leveraging the effective initialization from the first stage enables denoising at higher resolutions with significantly fewer steps, enhancing overall efficiency. Extensive experimental results demonstrate that AP-LDM significantly outperforms state-of-the-art methods, delivering up to a 5x speedup in HR image generation, thereby highlighting its substantial advantages for real-world applications. Code is available at https://github.com/kmittle/AP-LDM.
NBMOD: Find It and Grasp It in Noisy Background
Jun 17, 2023

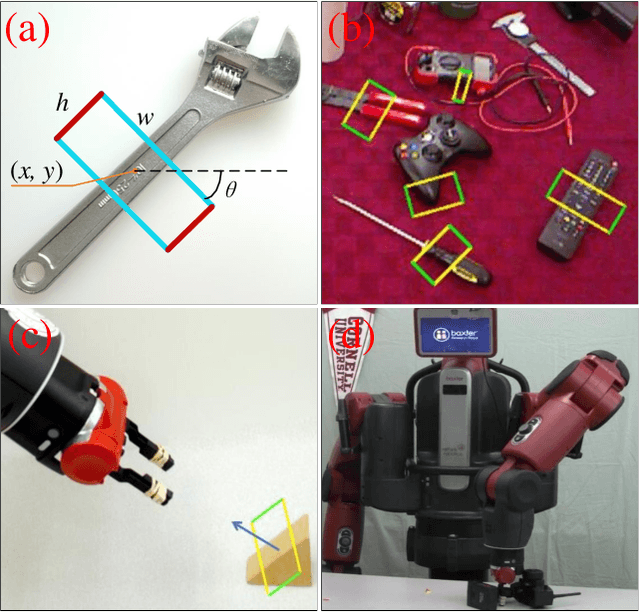

Grasping objects is a fundamental yet important capability of robots, and many tasks such as sorting and picking rely on this skill. The prerequisite for stable grasping is the ability to correctly identify suitable grasping positions. However, finding appropriate grasping points is challenging due to the diverse shapes, varying density distributions, and significant differences between the barycenter of various objects. In the past few years, researchers have proposed many methods to address the above-mentioned issues and achieved very good results on publicly available datasets such as the Cornell dataset and the Jacquard dataset. The problem is that the backgrounds of Cornell and Jacquard datasets are relatively simple - typically just a whiteboard, while in real-world operational environments, the background could be complex and noisy. Moreover, in real-world scenarios, robots usually only need to grasp fixed types of objects. To address the aforementioned issues, we proposed a large-scale grasp detection dataset called NBMOD: Noisy Background Multi-Object Dataset for grasp detection, which consists of 31,500 RGB-D images of 20 different types of fruits. Accurate prediction of angles has always been a challenging problem in the detection task of oriented bounding boxes. This paper presents a Rotation Anchor Mechanism (RAM) to address this issue. Considering the high real-time requirement of robotic systems, we propose a series of lightweight architectures called RA-GraspNet (GraspNet with Rotation Anchor): RARA (network with Rotation Anchor and Region Attention), RAST (network with Rotation Anchor and Semi Transformer), and RAGT (network with Rotation Anchor and Global Transformer) to tackle this problem. Among them, the RAGT-3/3 model achieves an accuracy of 99% on the NBMOD dataset. The NBMOD and our code are available at https://github.com/kmittle/Grasp-Detection-NBMOD.